
基于强化学习的数据分布
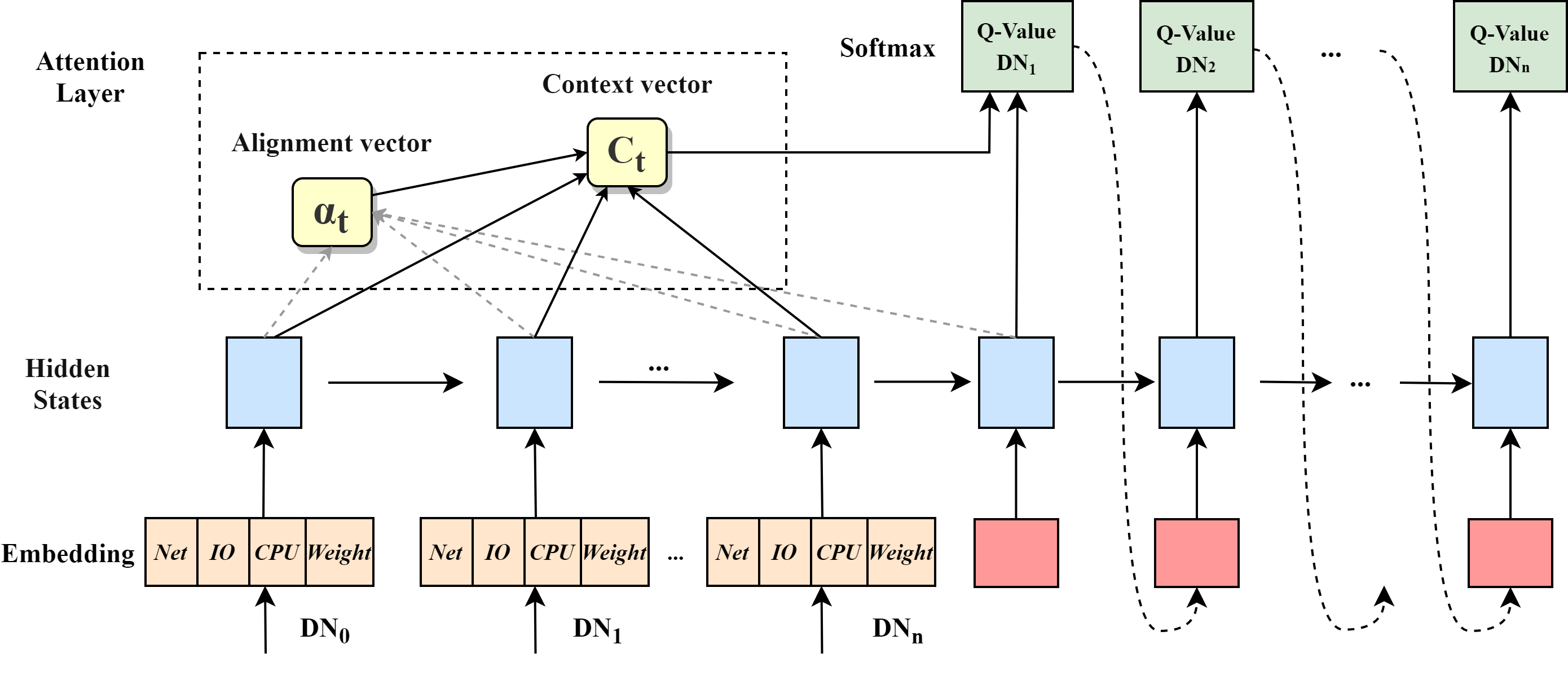
Learning Replica Placement with RLRP
来由同一梦,休笑世人痴。 — 小雪
[TOC]
Abstract
Introduce
- 分布式/对象存储等等
- 分布问题:负载均衡、可靠性问题(副本和故障域)、迁移扩容等等
- 强化学习为解决分布问题带来曙光
- 我们的方案
Motivation
强化学习
问题建模
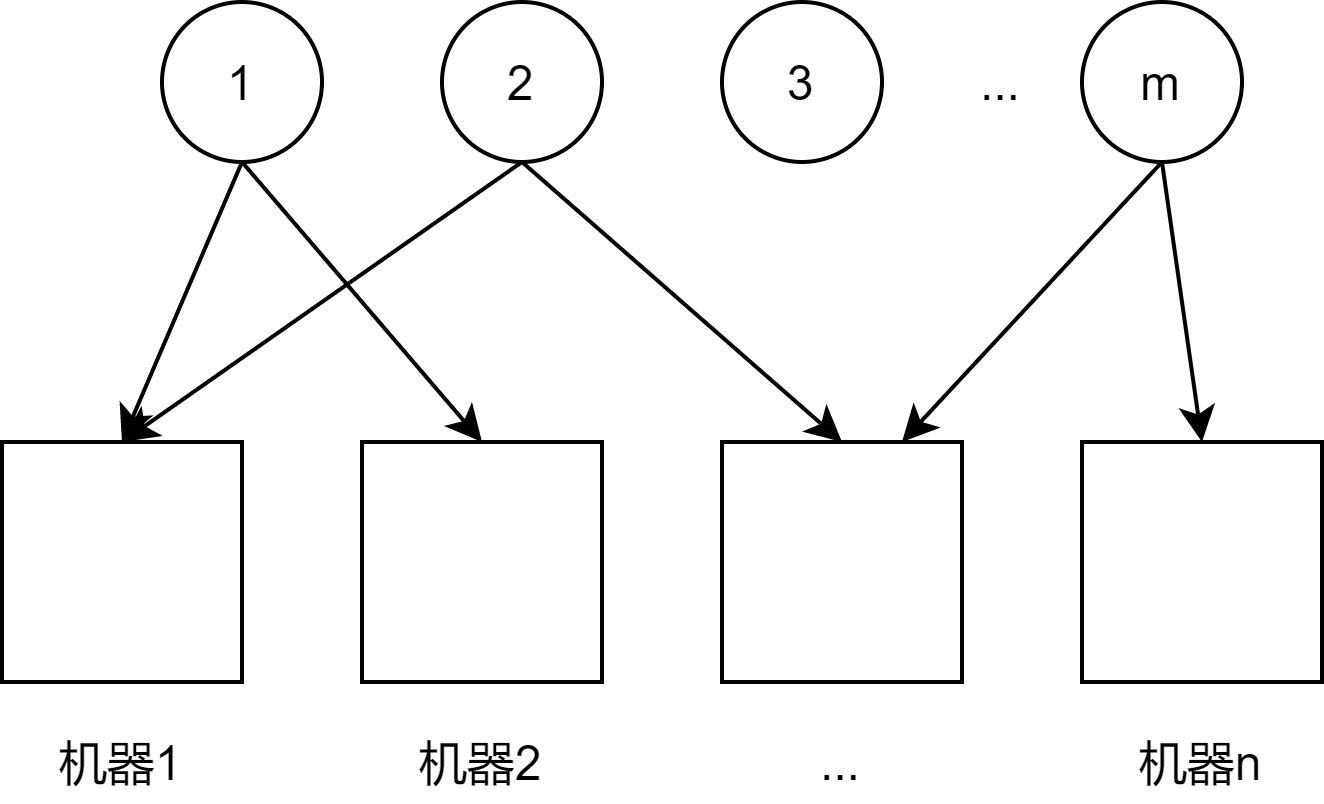
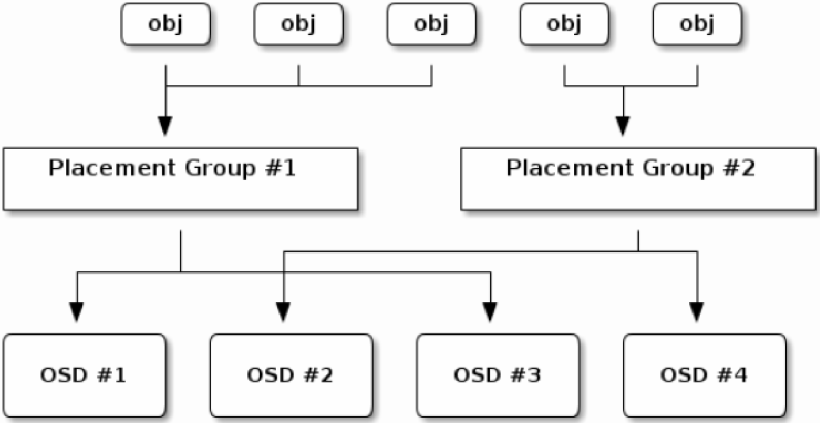
副本放置问题: M个数据存到到N个机器上, 每个数据R个副本在不同机器上, 下图中R=2
目标1. 均匀性,每个机器上的数据尽量均匀;
目标2. 增量迁移性,增加机器,之前机器将数据迁移到新机器上,保证迁移最小且数据均匀;
后续保证: 1. 每个机器上的主副本尽量均匀;3. 机器异构环境
具体到Ceph
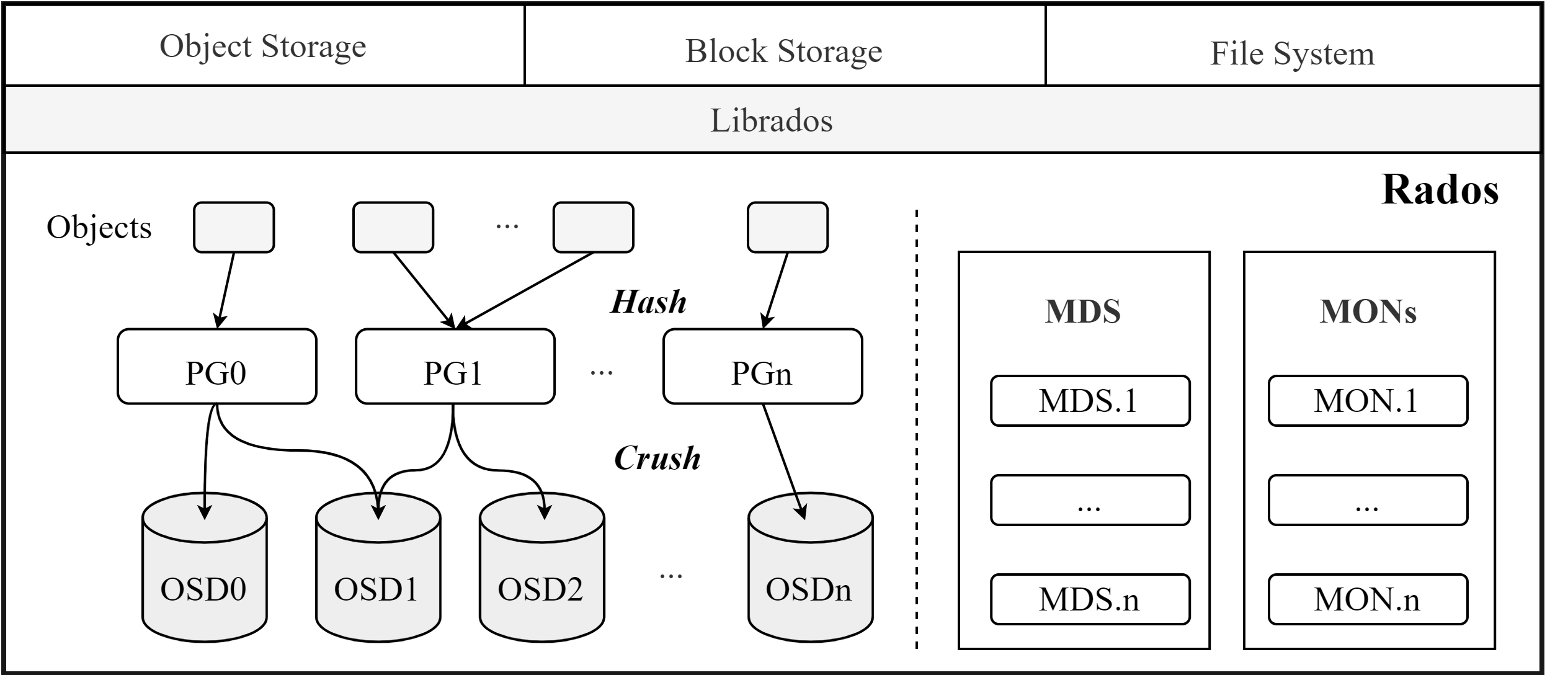
算法目标
- 均匀性:分布均匀
- 一致性:相同输入,相同输出
- 可靠性/可用性:副本放置,故障域隔离
- 可扩展性:增/删节点处理,增量迁移
- 其他:性能指标(负载均衡)、分布式CAP等等
Design
With RL 设计
- 环境定义(park)+ 模型实现(tensorflow),基本框架:
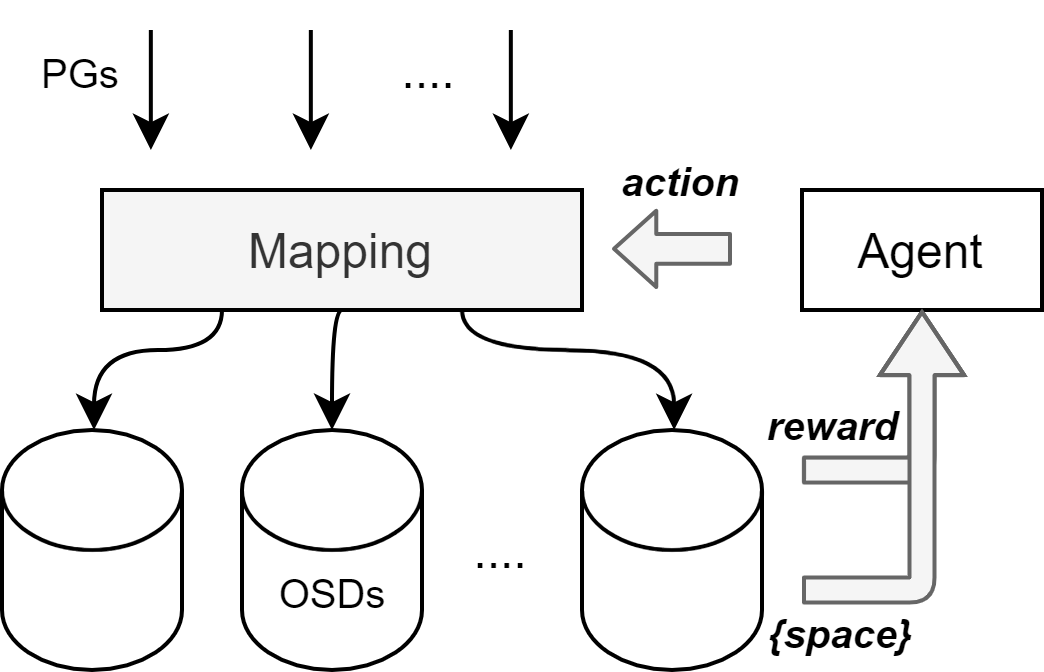
两种思路
- RL作为映射算法
- RL作为辅助,调整原有映射算法
实现1:RL训练出放置策略,action space即为mapping策略
简单实现,目前支持映射均匀性、副本机制、增删pg节点(n->m)
- 一致性 、扩容暂不支持
- spcae:各osd的容量状态,{weight0,weight1,…,weightm,}
- action:{osd0,osd1,…,osdm}
- reward:各osd容量标准 / 前后标准差变化 / 极差
- policy : 当前状态下选择的action,是训练结果
- 模型:当前实现Q-learning和DQN
- 实现和效果
- 多次迭代训练,选择效果最佳的结果
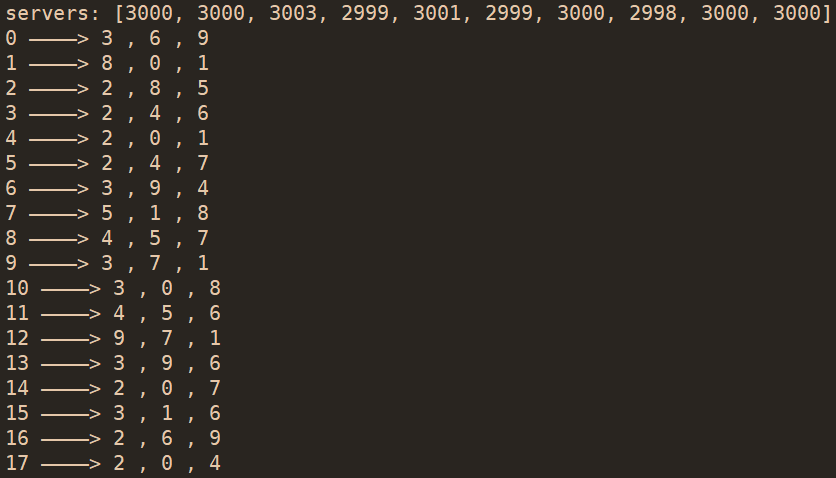
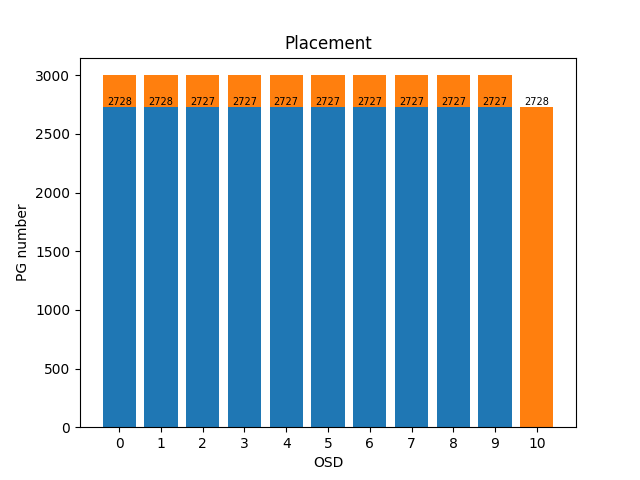
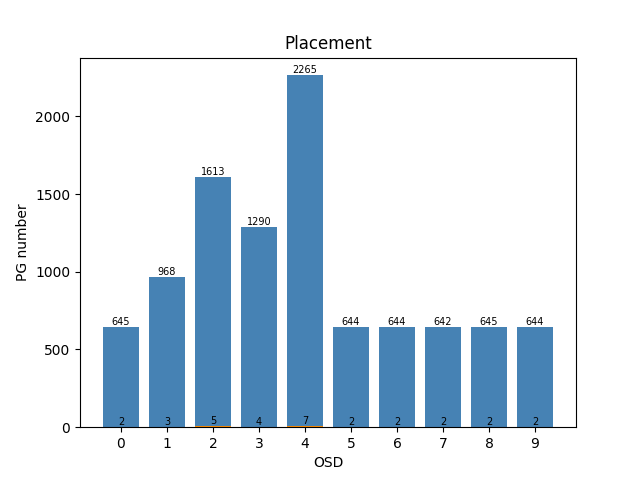
- 1000pg,10osd,3副本,mapping选择另存:
问题1:如何映射?
- 巨大问题:每次得到状态不一致
- 方式1:将映射关系建表
- 方式2:分类问题?区分pg id
问题2:状态过多,空间爆炸;训练精度不足,需要训练很久?
- n ^ m (1000 ^ 10 = 10 ^ 30)
- 改善模型、改善状态定义…
- DQN中模型选择:目前使用的MLP,结合RNN、CNN?
- 训练参数调整,Offline Training
问题3:如何支持增删osd
减少节点m:控制action不能等于m,就可以均匀分布到其他osd;但是两次映射差距甚大…
增加节点:space和action都要变,模型需要重新训练?另外重新训练和原映射差距甚大…
难点:增量迁移怎么定义模型?
想法1:将两次变化量作为reward
训练难收敛,训练效果差
表格 + RL 再训练
想法2:多agent,每个osd相当于agent,Multi-agent Data Distribution
- space:weight
- action:要 / 不要 / 滚;+ 1 / 0 / -1
- reward:对每个agent 尽量少加 / 尽量少减;所有,标准差
- 模型学习困难:Actor-Attention-Critic for Multi-Agent Reinforcement Learning,ICML’19
- 数据集难以构造,有限样本
想法3:动态环境下的强化学习
- A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments,2005
- 多模态强化学习
实现2:采用原有的放置策略(hash、crush),RL作为辅助调整,即action调整mapping
- 简单实现,mapping=crush,支持所有
- space:各osd的容量状态,{weight0,weight1,…,weightm}
- action:crush选出来后左右移动?
- reward:经过调整后,标准差变化
- 问题
- 只能对均匀进行优化,是否影响性能?
- 是否可以抽象成ML分类问题,RL作为调整辅助?
- ML分类器 + RL
- 是否可以做成一种通用框架,可以适用于各种分布算法?
增量迁移设计
- 基本目标:分布均匀,增量迁移
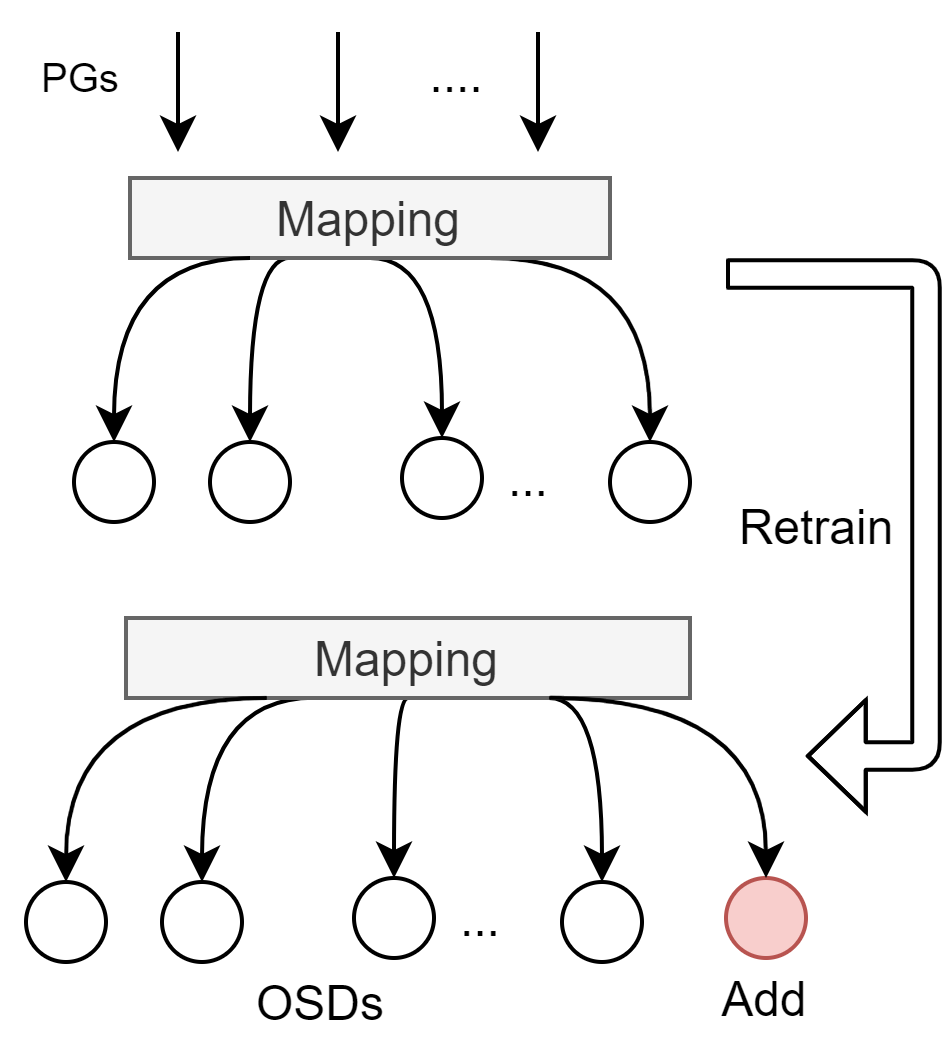
- 实现1:增/减节点重新训练
- state:包括Map
- Reward: 标准差 && Map变化最少
- 训练时间长、训练效果差
- 实现2:增/减节点单独训练模型
- 模型定义
- state:每个节点容量
- action:迁或者不迁
- reward:最少迁移量 && 标准差
- 模型得到每个节点应该迁移量,在Map没冲突的情况下,随机选择
- 两种方式都是扩容一次,训练一次,性能损失严重
- Attention,记忆RNN?
- 模型定义
- 完全RL
- 可变状态空间或者动作空间
- 对深度强化学习算法来说是一个比较棘手的问题。一旦输入空间确定,就意味着神经网络的输入节点个数确定了下来。如果在学习的过程中,输入节点增多或者减少,这对隐藏层乃至输出层的数据都会产生影响
- RNN + nas
- 可变数量的多智能体RL
- 结合Atention模型,Evolutionary Population Curriculum for Scaling Multi-Agent Reinforcement Learning,2020
- 可变状态空间或者动作空间
RLRP 实现
RLRP(第一阶段,简单Demo)
完成简单Demo,副本放置+强化学习框架,实现同构环境分布均匀和迁移最小化
问题1:可变环境及模型优化
- 每次增加节点都要重新训练,费时费力
- 随着PG和OSD数量增加,训练越来越困难,训练时间越来越长
问题2:异构环境及负载均衡
- OSD异构环境,OSD权重、硬件性能、负载状况(CPU、IO、网络)等等差异
主PG的分布影响读性能,迁移之后主PG分布不是很理想
- 副本放置+强化学习框架,实现同构环境分布均匀和迁移最小化

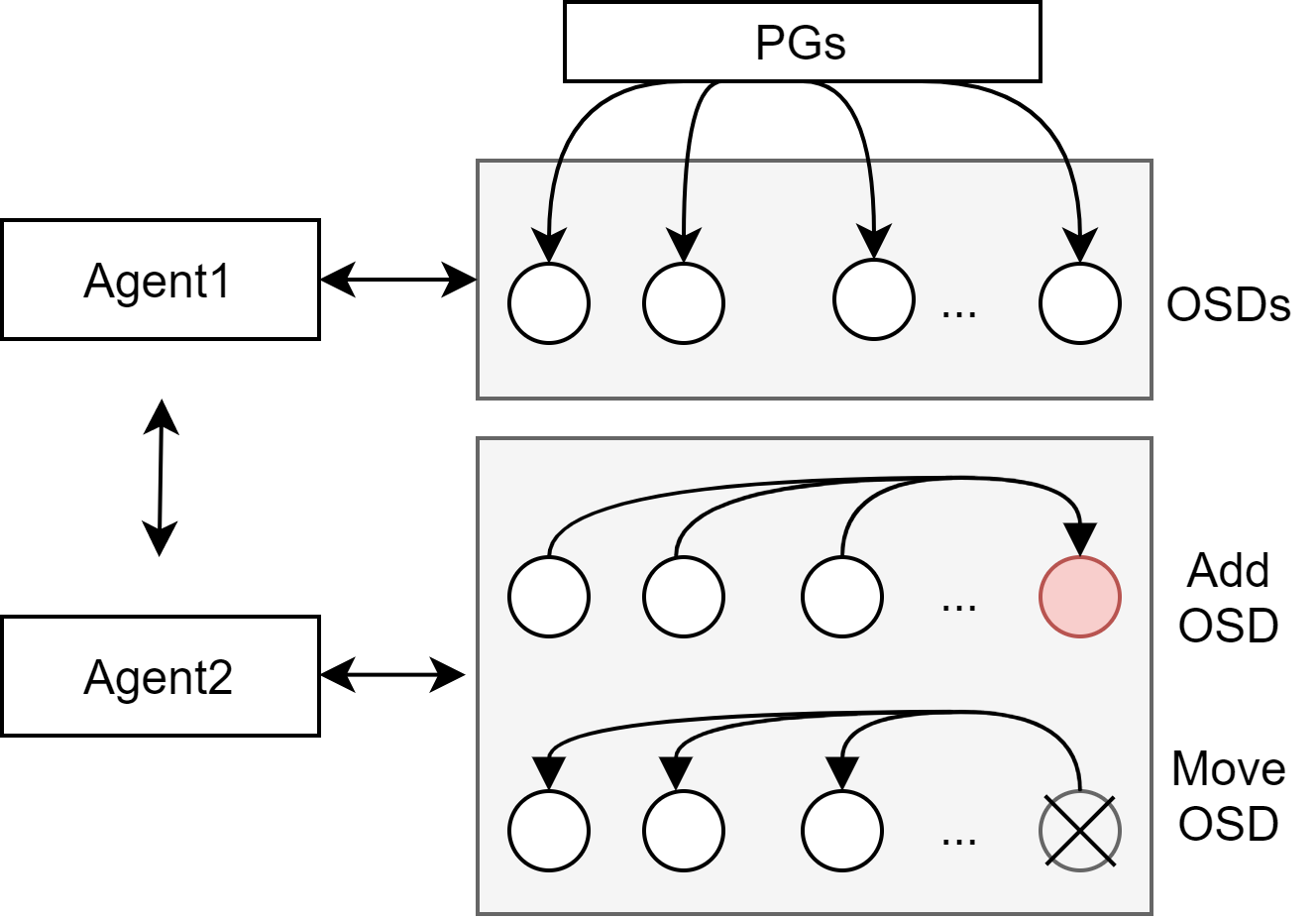
如图2,将均匀分布和迁移分成两个模型进行训练,分别是Agent1和Agent2,两则定义如下
均匀分布(Agent1)
spcae:各osd的容量状态,{weight0,weight1,…,weightm,}
action:{osd0,osd1,…,osdm}
- 限制:每个PG选K次,每次不一样,K为副本数
reward:各osd容量标准 / 前后标准差变化 / 极差
policy : 当前状态下选择的action,是训练结果
模型:当前实现Q-learning和DQN
输出:映射表(n->m)
- 下面是三副本的例子
- 横向上看:可以得到 PGi —> (OSDk, OSDj, OSDl) 的映射,i = 0 to n;0 <= k, j, l <= m
- 纵向上看:可以得到每个OSD中PG个数
OSD0 OSD1 OSD2 OSD3 … OSDm PG0 0 1 0 1 … 1 PG1 1 1 1 0 … 0 … 0 0 0 0 … 0 PGn 0 0 0 1 … 0
增量迁移
减少OSD节点(Agent1)
- 减少OSDm,将OSDm中的节点通过Agent1重新映射
- 限制1:不能选择action OSDm;限制2:不能选择有副本冲突的
- 输出:更新映射表
增加OSD节点(Agent2)
action:{0,1,2,3}
- 对于每个PG,0、1、2分别表示第1、2、3个副本
- PGi —> (OSDk, OSDj, OSDl),0表示从OSDk迁移到新节点,1、2表示迁OSDj、OSDl
- 3表示不迁
其他都和Agent1一样,效果不错
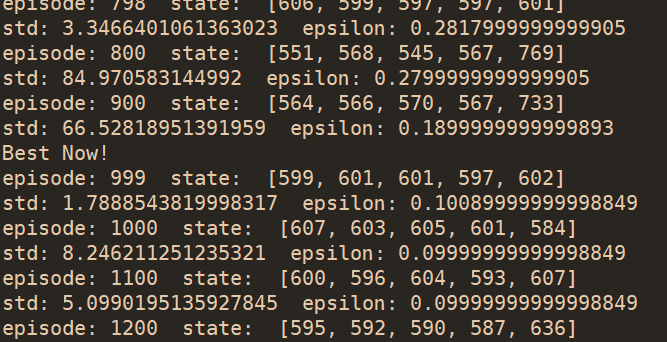
加速收敛:调整学习率、调整网络结构;如果达到某个阈值(比如标准差<=3),可提前停止训练
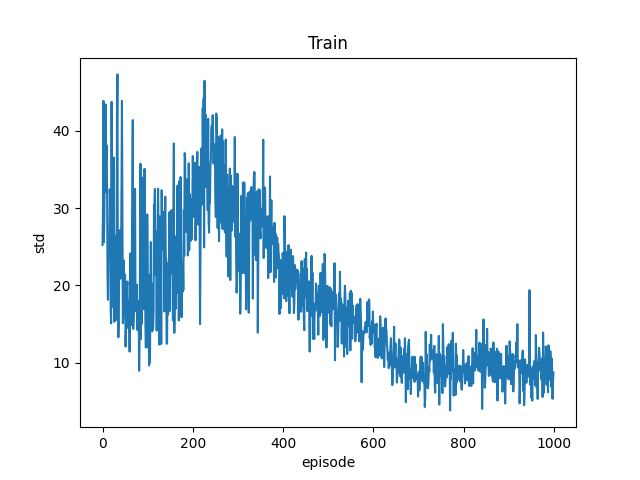
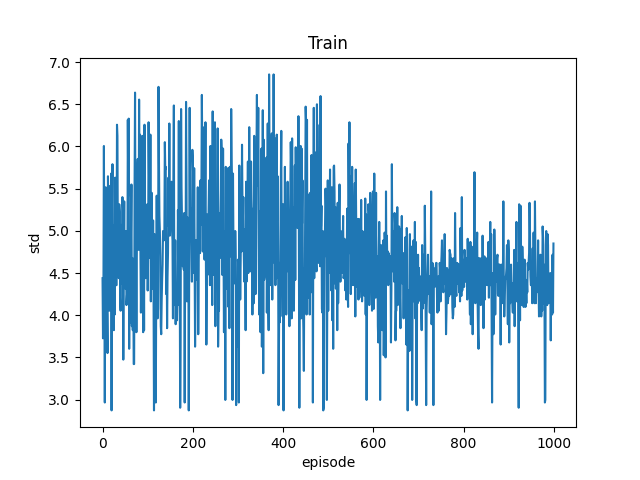
整体演示:200个PGs,3副本映射到10个OSDs上,再添加一个OSD
- Agent1
- 输入:PG、OSD个数,副本数;输出:映射表
- 加速:训练某段时间内std小于阈值,停止训练
- 主PG:先映射一遍得到主PG,再映射两遍得到两副本
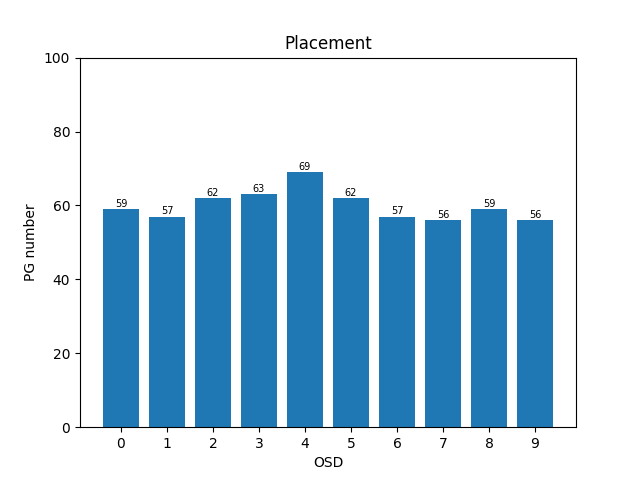
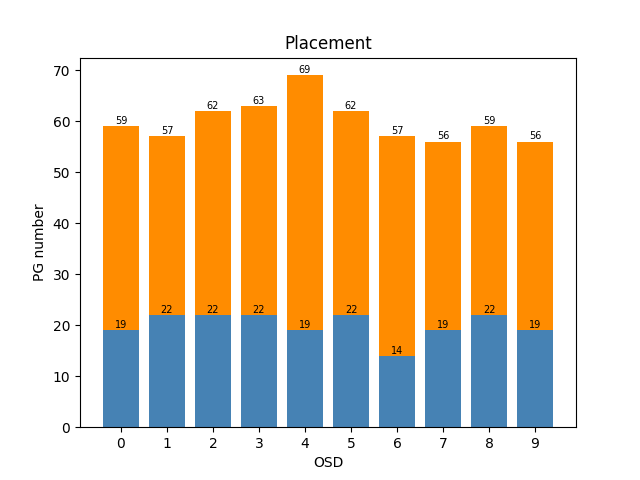
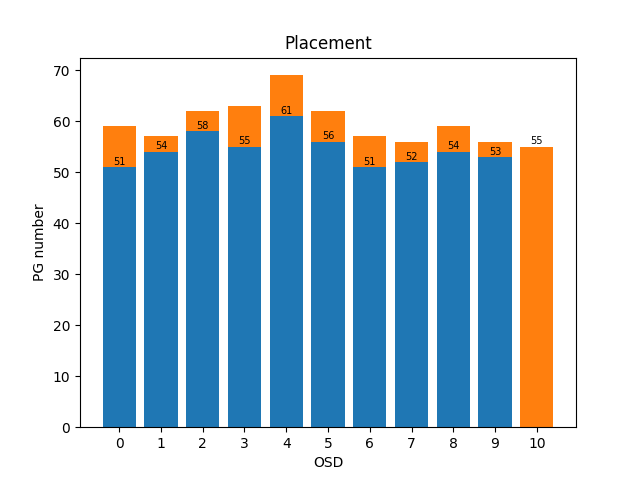
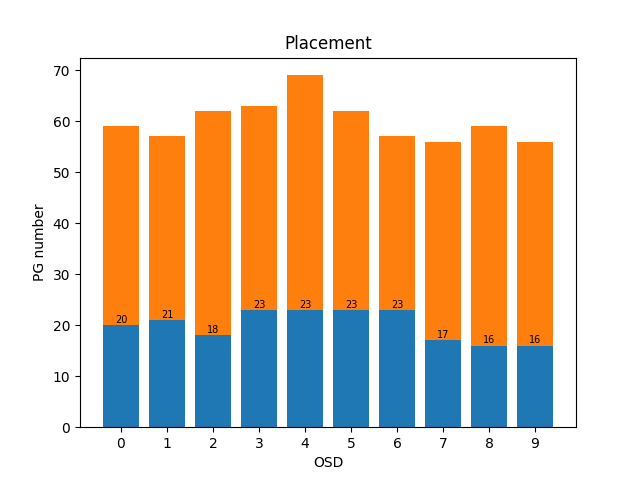
- Agent2
- 输入:映射表,新增OSD个数,副本数;输出:映射表
- 加速:训练某段时间内std小于阈值 / 新增OSD数量最多,停止训练
- 主PG:设置action 0是迁移主PG,在Reward中添加主PG均衡奖励,暂时训练不收敛
- 先迁移主PG,也就是action只能选择0或者3;再迁移其他,action只能选择1,2,3:效果没那么好
- Agent1
模型的比较
- ing
后续
- 问题
- 迁出不可能迁回,考虑保留一段时间前映射表
- 每次增加节点都要重新训练Agent1和Agent2,费时费力
- 还是要解决RL环境变化的问题:可变状态和动作空间
- Atention模型,结合上一次训练结果
- 随着PG和OSD数量增加,训练越来越困难,训练时间越来越长
- 迁移主PG需要重新考虑一下
- 要考虑其他负载均衡、异构因素
- 模型优化
- Attention Mechanism
- RL: Value: Sarsa\Q-learning\DQN… vs. Policy: Policy Gradients\Actor-Critic\A3C\DDPG\PPO…
- Multi-Agent\Signle-Agent Dynamically Varying Environments
- NN: MLP\CNN\DNN\RNN\LSTM…
- 负载均衡
- OSD之间不同权重,PG大小不均设计
- 状态中添加PG大小
- 改Reward计算方法:单位权重(PG数/权重)方差
- 异构环境设计(Agent3)
- OSD权重、硬件性能、负载状况(CPU、IO、网络)等等差异
- Reward目标可能要改成性能
- 主PG均衡设计
- Agent1:每次映射是均匀的,先映射一遍得到主PG,再映射一遍得到两副本
- Agent2:设置action 0是迁移主PG,在Reward中添加主PG均衡奖励
- OSD之间不同权重,PG大小不均设计
- 问题
Attention Mechanism
- 从关注全部到关注重点
- ing
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
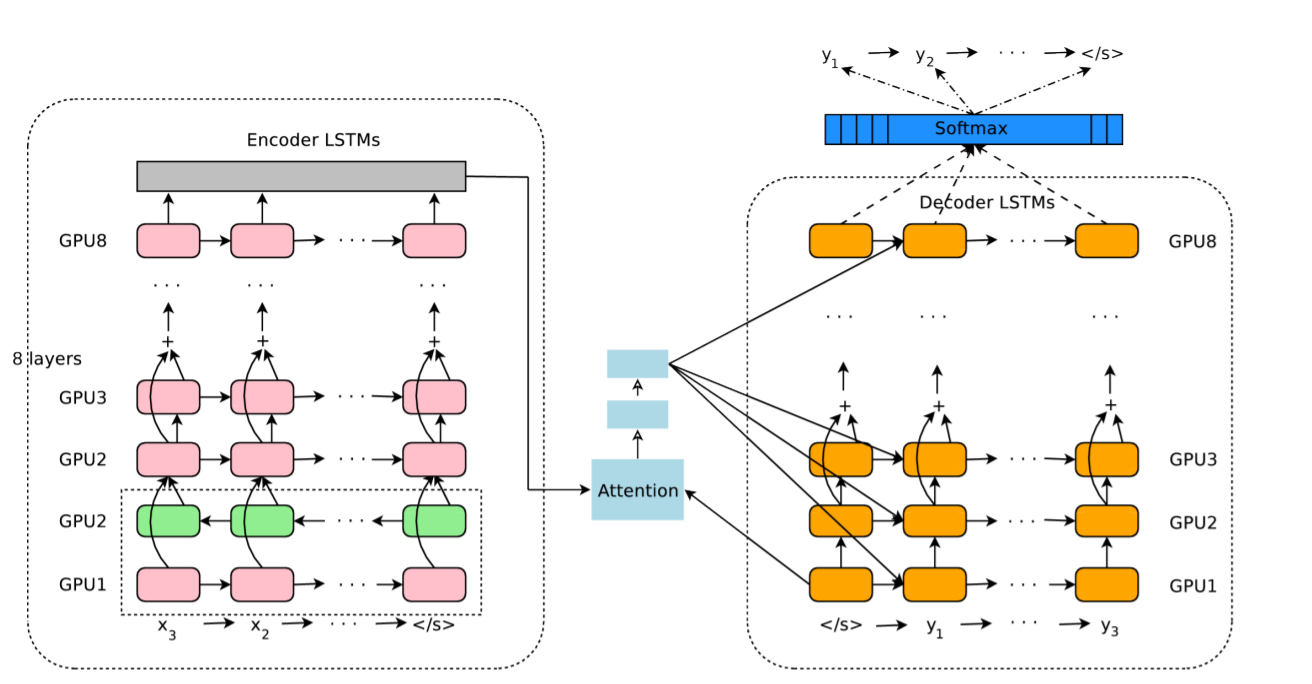
RLRP(第二阶段,模型优化)
模型优化
问题1:模型选择
RL: Value: Sarsa\Q-learning\ DQN… vs. Policy: Policy Gradients\Actor-Critic\A3C\ DDPG\PPO…
问题2:OSD、PG增加训练困难
- OSD增加?
- 不考虑PG差异情况下
- 从绝对状态改为相对状态,[100,121,101] == [0,21,1],每次将状态组所有元素减去最小的值,得到当前状态
- 设置一个训练区间,比如1000,每次迭代1000 steps
问题3:迁出不能迁回,每次映射不一致
- 通过保存模型和固定参数,可以保证每次映射结果一致,可以考虑去掉映射表?
问题4:副本选择
- 选择action时控制三次选择不能重复,但是在test中模型和参数固定,同样的状态选择是一定的,不能重复的会导致选不出来
- 计算reward的时候,出现重复给予很大的惩罚,奖惩控制不当出现畸形选择,一直固定选某几个
- 最终方案:因为模型每次是选择Q值最大的action
- 选Q值前三的作为三组action
- 先选Q值最大的作为action,选其他副本的action和以前某次一样,则选Q值次大的作为替补
问题5:主副本的均衡?
- 先跑一遍模型选出主副本
- 再根据上述副本选择策略跑一遍选出其余副本
问题6:扩容之后,新增节点怎么选择?
- 迁移后的状态作为初始状态,训练新模型
演示效果
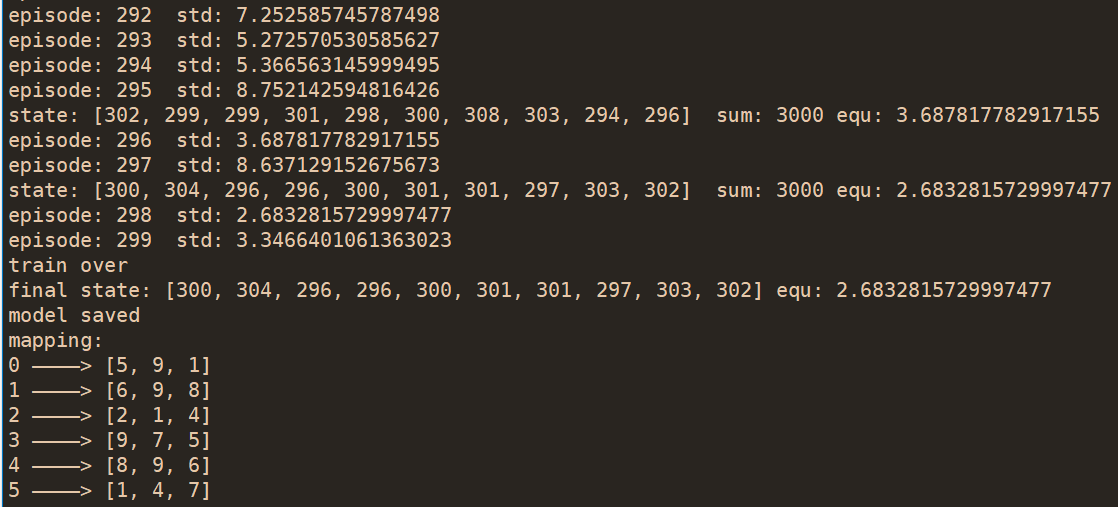
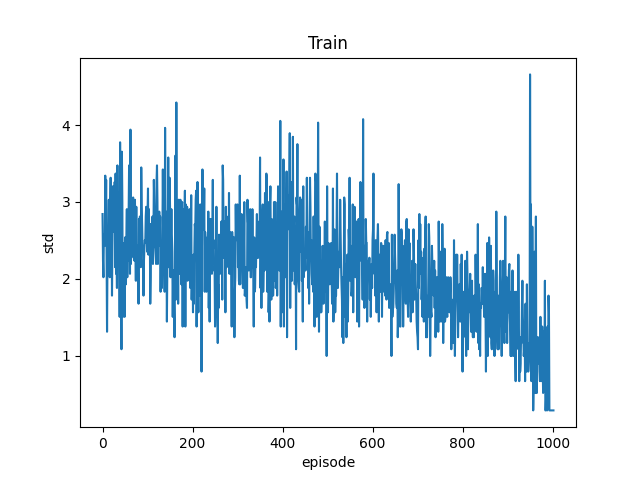
训练的模型:place.ckpt(目前训练出来最完美的模型)
- DQN 模型
- 以100个pg为训练区间
- 这个训练效果是非常重要的,设置无限制训练迭代,当连续十次达到满意结果(标准差小于1),停止训练
- total episode: 1379 ; cost time: 714.2311611175537 s (11.9分钟)
- 三副本 total episode: 631 ; cost time: 985.1475253105164 s (16.4分钟)
- 模型大小 52K = 8K (ckpt.data )+ 4K (.index) + 40K (.meta)
- 可以测试随意多少个pg
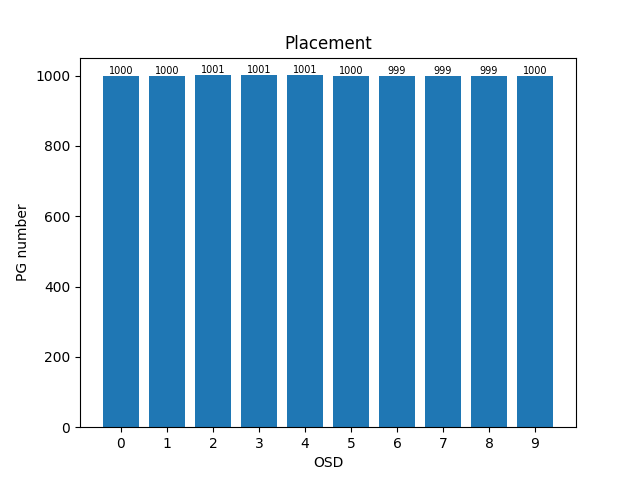
测试:10000 pg,拆分成100个训练区间进行测试
- std:0.7745966692414834; cost time: 4.35152244567871094 s
- 三副本 std:0.9213;cost time: 12.70314908027649 s
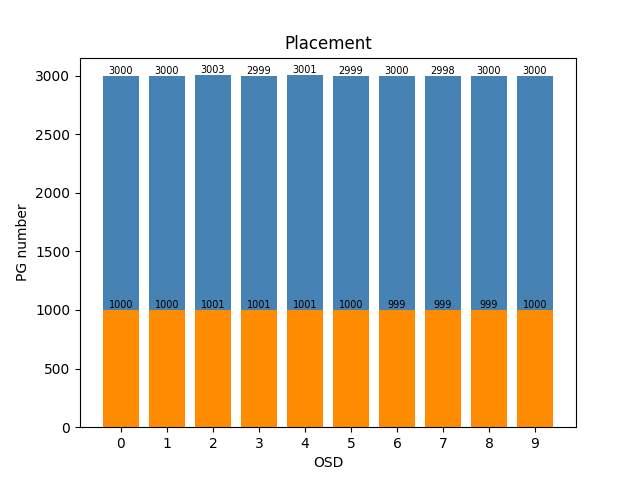
数据迁移:
- 训练 total episode: 992; cost time: 879.645852804184s (14.7分钟)
- 测试 cost time: 1.1143670082092285;std: 0.44536177141512334
RLRP(第2.5阶段,OSD增加)
- 问题:
- OSD增加,每次需要重新训练
- 10 osd:14.4分钟;11 osd:18.3分钟
- 迁移需要训练agent2,之后的状态作为初始状态,又要训练新模型
- OSD增加,每次需要重新训练
方法1:模型调整(参考openai five里面提出的surgery,Dota 2 with Large Scale Deep Reinforcement Learning,66页)
基本思路(大致翻译,具体看原文)
- 改变神经网络结构的参数量:假设我们有输入变量
,其维度为
,经过一个激活函数后得到向量
,其维度为
,然后再经过一层全连接层得到向量
,其维度为
。如果需要增加向量
的参数量,增加其维度从
,那会导致
的维度都发生改变:
这里
指的是随机初始化,经过这个操作后,可以发现
,
的前
,
是完全一致的,随机初始化保证了新加入的权重参数进行优化时可以获得足够的梯度信息,同时,
新增加的权重参数进行置零操作,保证了前面激活部分新增加的变量不影响到全连接层的输出,只将部分的权重置零也不会影响后续的训练。值得注意的是,在LSTM的网络结构中,由于单元之间是循环前后相连的,没有办法如同上面的全连接层一样做到新旧权重参数的完全隔离,如果进行随机初始化,会导致原有模型的能力下降,要是置零,则会导致梯度信息丢失,在实际操作中,采用的方式是两者的综合,即采用一个很小的随机值做初始化,在避免丢失梯度信息的同时最大程度的减少对旧模型能力的影响。
- 改变观测状态:surgery的一个主要部分是增加了许多新的观测状态,放在模型训练上,可以认为是模型的输入发生了变化,游戏的原始状态是经过一系列的转化和编码操作之后才输入到模型的,因此可以理解为原始的输入并没有发生变化,发生变化的只是对原始输入进行编码的部分。因此只要可以保证
,这里
是原始游戏状态,而
则是编码之后的输入,即新模型对扩展后的编码状态的能力水平相比旧模型并没有下降,然后套用上述1的方法,将新增部分的编码对应权重做置零操作后进行训练即可。
- 改变环境或动作空间:上述surgery的改动部分还涉及游戏版本的更新,也包括了新增动作,将原来通过脚本完成的操作改为由模型控制。明显的与前两种类型不同,这里涉及到学习到的策略函数
的改变,因此在训练过程中采用类似“anneal”的策略。在环境改变后,将训练对局中新环境的比例从0%(即完全旧环境)慢慢上升到100%(过渡到新环境),来避免环境突变时导致模型能力出现陡变,同时如果发现模型的Trueskill分在“anneal”过程中出现下降,则进行回退并减慢“anneal”的速度。
- 模型删减:处于保证模型在surgery后能力不变的考虑,很多删减变量或模型参数的需求没有被考虑在内,这些被废除的变量暂时还是被保存在模型内。
- 模型训练重启:在模型经过修改并重启训练之后,优化器中的梯度动量信息可能会带来问题,由于参数空间发生了变化,可能会导致梯度优化方向发生改变而进一步影响训练。因此在重启之后的一小段时间内,优化器的学习率被置零,几小时后等所有的rollout对局稳定后才开始正常的训练。另外,surgery不仅需要保证对当前训练的最新版本模型有效,还需要保证对所有的历史模型而言都有效,否则会导致对战时历史模型能力在surgery后出现下降,影响训练效率。
- 改变神经网络结构的参数量:假设我们有输入变量
尝试一下,10个OSD增加一个,此时state从10维变成11维,action从10变成11
- DQN的NN,MLP

网络三层,输入,隐藏层(20节点) ,输出层
W1 = [self.state_dim,20], b1 = [20]
W2 = [20,self.action_dim]),b2 = [self.action_dim])
读取模型,在原模型参数上增加维度 :原来的值加上新增维度0值
if add: self.saver.restore(self.session, path) variable_names = [v.name for v in tf.compat.v1.trainable_variables()] [W1_old, b1_old, W2_old, b2_old] = self.session.run(variable_names) W1_add_zero = tf.zeros((add,20)) W2_add_zero = tf.zeros((20,add)) b2_add_zero = tf.zeros(add) W1 = tf.Variable(tf.concat([W1_old, W1_add_zero], 0)) b1 = tf.Variable(b1_old) W2 = tf.Variable(tf.concat([W2_old,W2_add_zero], 1)) b2 = tf.Variable(tf.concat([b2_old,b2_add_zero], 0))测试对比,达到相同效果(连续10次迭代标准差<1)
- cost time: 1096.7204835414886 s (原来)
- cost time: 83.1434931755065 s (优化后) cost time: 74.44707727432251 s ; cost time: 81.61742353439331s
快了 92%
补0改成随机
W1_add_random = tf.random.truncated_normal(W1_add_zero.shape) W2_add_random = tf.random.truncated_normal(W2_add_zero.shape) b2_add_random = tf.random.truncated_normal(b2_add_zero.shape) W1 = tf.Variable(tf.concat([W1_old, W1_add_random], 0)) b1 = tf.Variable(b1_old) W2 = tf.Variable(tf.concat([W2_old,W2_add_random], 1)) b2 = tf.Variable(tf.concat([b2_old,b2_add_random], 0))- cost time: 264.1176526546478 s; cost time: 399.5544981956482 s; cost time: 237.48365426063538 s
增加10个OSD,总过20个OSD,训练区间增加为200PGs
原训练时间:cost time: (DQN未知,要求太严苛下,跑了一晚上没训练出来)DDPG+5MLP 3小时24分钟
优化后(10->11->..->20)训练时间:2829.1229819754 s (约47分钟),快了78%
- 类似于Curriculum learning,Self-Paced Learning for Latent Variable Models,NeurIPS’10
高维度状态可以采取此策略,越高维还是很慢
步数 1 2 3 … 10-11, 10-12,10-13 81s 198s 669s 11-12 84s 12-13-14-15-16-17-18-19-20 100~700s
方法2:Attention
NLP的seq2seq问题,encoder+decoder,attention模型用于decoder过程中,它改变了传统decoder对每一个输入都赋予相同向量的缺点,而是根据单词的不同赋予不同的权重
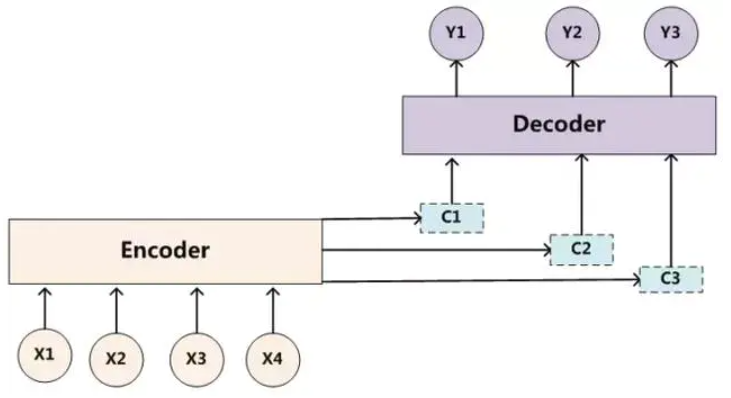
核心观点:不同节点作用/影响不同,给每个节点加一个权重
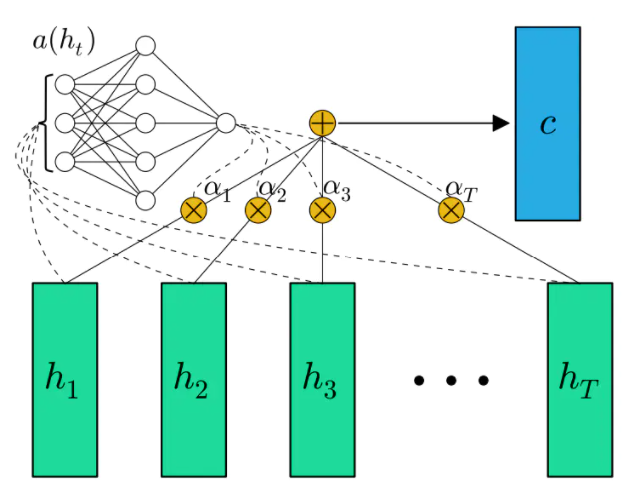
尝试一下,为隐藏层输出加一个权重Ai,在训练过程中更新
def build(self,inputshape): assert len(inputshape) == 3 self.W = self.add_weight(name='attr_weight', shape=(inputshape[1], inputshape[2]), initializer='uniform', trainable=True) self.b = self.add_weight(name='attr_bias', shape=(inputshape[1],), initializer='uniform', trainable=True) super(attention_layers, self).bulid(inputshape)没什么用
方法3:Finite State Machine
- 将看不见的观测结果归为最近的已知观测结果
- 状态空间具有一定的连续性,相似的观察可以触发相似的动作
- 将两个观测值的接近程度,定义为观测向量之间的相似性。相似度度量如欧几里德距离和余弦相似度。因此,看不见的观测可以在提取的FSM中触发一个转换
- 实现:一个比较简单的版本,对于欧几里德距离小于10的未知状态初始状态设为相同动作
- 效果:没明显提升
方法4:
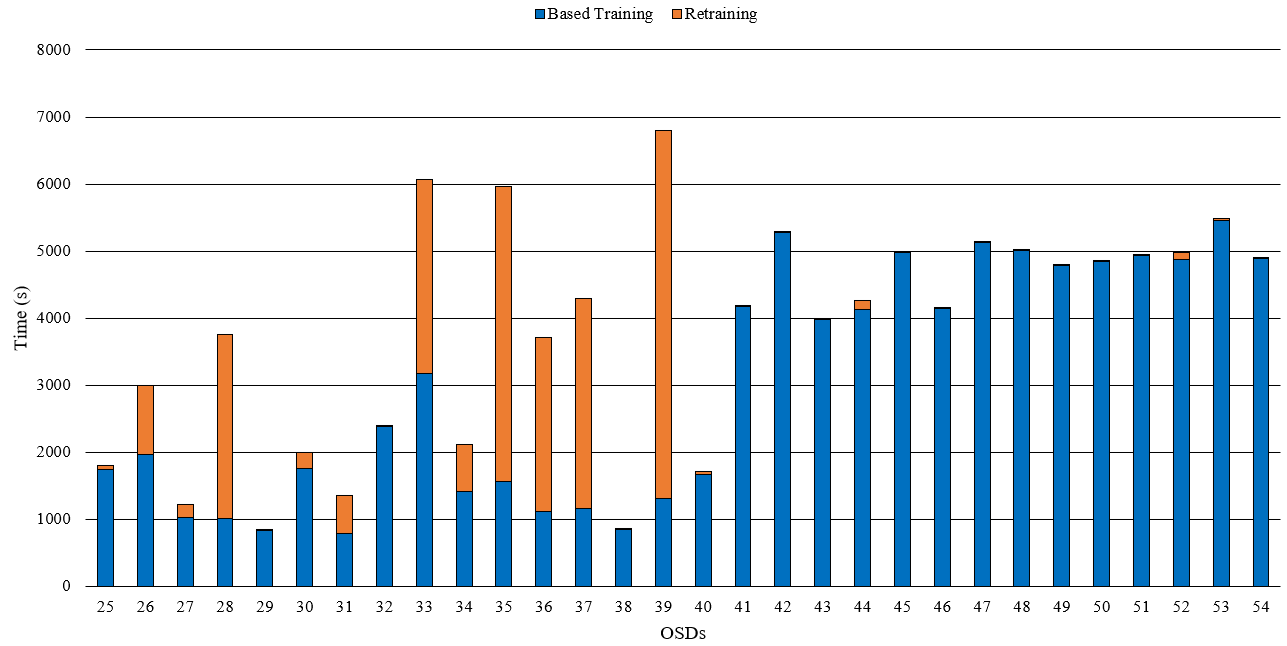
综合测试
25-100 OSDs:800-7000s (0.2-1.6h),稳定于5000s(1.11h)
RLRP(第三阶段,异构环境)
OSD权重的差异
不同weight:最简单的做法,state_i={pg数/weight_i}
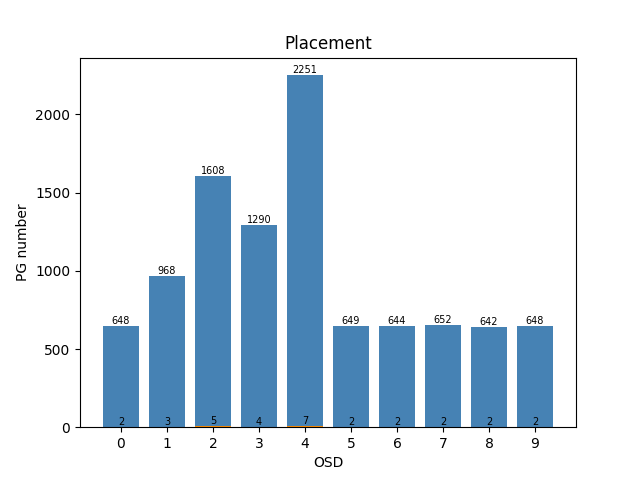
【例子1】 weight: [2, 3, 5, 4, 7, 2, 2, 2, 2, 2] ,训练区间是100
训练 total episode: 548 ; cost time: 626.9669451713562 s
测试 std: 0.4696938456699067; cost time: 4.37903094291687
【例子2】weight: [21, 35, 5, 44, 7, 54, 25, 12, 2, 22],训练区间是1000
训练 total episode: 880 ; cost time: 5182.777556657791 s
测试 servers: std: 0.48989794855663565;cost time: 4.458923101425171
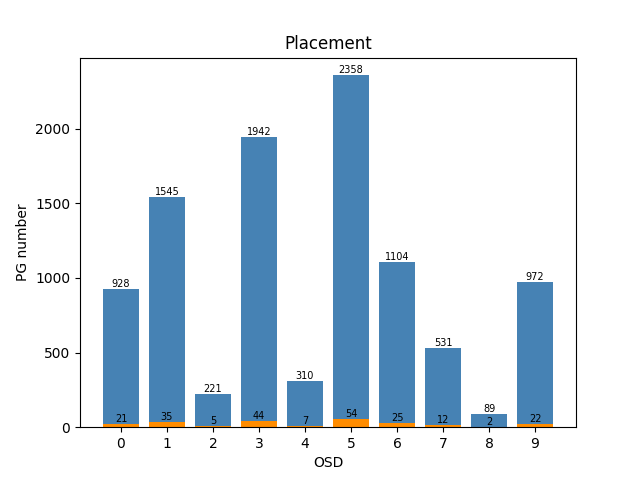
soga
不小心当测试不同权重的时候,使用了原模型 place.ckpt
【例子1】std: 0.8; cost time: 4.831289529800415
【例子2】std: 1.077032961426901; cost time: 4.3217644691467285
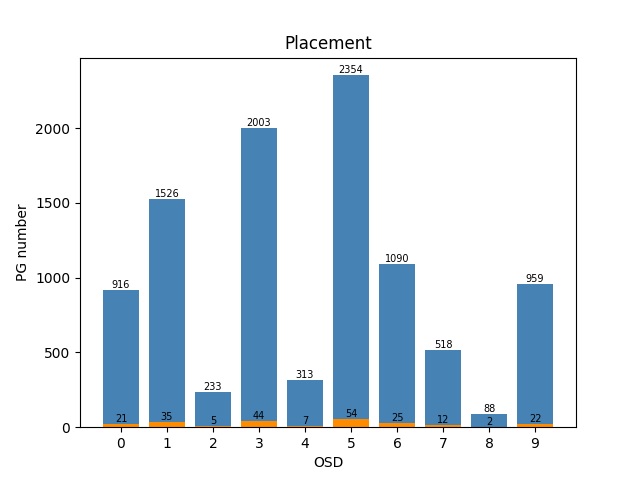
仔细思考一下,也合理,跟状态转换有关
- (pg0, pg1, pg2, ,,, ,pgn) -> (pg0/weight0, pg1/weight1, ,,, ,pgn/weightn)
- place.ckpt 模型可以保证 (pg0/weight0, pg1/weight1, ,,, ,pgn/weightn) 的均衡,于是就有了这样的分布
- 但是比单独训出来的效果差一点点
这样的话:现在得到的 place.ckpt 模型可以解决不同weight的情况
OSD异构环境
- 分布考虑
- 存储设备差异:NVM、SSD、HDD
- 网络、IO、后台、内存等等资源差异
- 迁移考虑
- 上述异构环境
- 地缘因素、网络情况
- 何时迁移
- 基本思路:multi-objective optimization function, 综合考虑均衡和性能
- 难点:构建训练环境和训练的数据
- CPU 、内存、网络、节点性能、节点容量….
- 先考虑三个因素:%iowait(CPU)、每秒磁盘读取请求数、每秒磁盘写入请求数(IO)、网络利用率(网络)
- 训练负载生成:COS-Bench
- 模型
- state:st=(iowait,rtps,wtps, net)t,%iowait值、每秒磁盘读请求数、每秒磁盘写请求数、网络利用率
- action不变,reward
- reward = w2 * thr - w1 * std
- thr = { for i = 0 to n, thr += (k1 * Net - K2 * IO - K3 * CPU) }
- 实现:DQN +输入层网络用LSTM+Attention
- tf.nn.seq2seq.embedding_attention_seq2seq / attention_decoder
- 分布考虑
对象及PG的差异
- 访问频率和访问模式:主要考虑的是obj -> pg的映射了
- 大小,id
RLRP(第四阶段,系统构建)
- In Ceph or others
总结
| 阶段 | 目标 | ||||
| 一、基本功能,简单Demo | 分布均匀 | 最小化迁移 | 高效查询 | 主副本 | 模型简单训练快速 |
| 优 | 优 | 中,需要查表 | 优 | 差,随着OSD和PG增加,训练时间激增 | |
| 二、训练加速,模型调优 | 模型选择与优化 | OSD规模增大训练困难 | PG数量增加训练困难 | 映射不一致 | 扩容之后副本选择 |
| 优,DDPG | 差,在考虑加入Attention机制 | 优,训练区间 | 优,模型保存与参数固定 | 中,原状态下重新训练 | |
| 三、多态处理,适应异构 | 不同权重 | 不同介质 | 不同负载环境 | 对象大小、ID等特征 | 对象访问频率和访问模式 |
| 优 | 无 | 无 | 无 | 无 | |
| 四、系统构建,完善接口 | 封装到Ceph | 系统搭建 | 提供API | 系统功能性测试 | 性能测试 |
| 无 | 无 | 无 | 无 | 无 | |
两种方向
提出一种分布算法,(MIT,André Brinkmann,基于balls-in-bins模型对分布算法提出四条准则,2002年)
Capacity Efficiency and Fairness. A scheme is called capacity efficient if it allows us to store a near-maximum number of data blocks. Fairness describes the property that the number of balls and requests received by a bin are proportional to its capacity. (容量效率和公平性)
Time Efficiency. Computing the position of an object with a low time and space complexity A scheme is called time efficient if it allows a fast computation of the position of any copy of a data block without the need to refer to centralized tables. Schemes often use smaller tables that are distributed to each node that must locate blocks.
(时间效率)
Compactness. We call a scheme compact if the amount of information the scheme requires to compute the position of any copy of a data block is small (in particular, it should only depend on n—the number of bins). (紧凑性)
Adaptivity. We call a scheme adaptive if it only redistributes a near-minimum amount of copies when new storage is added in order to get back into a state of fairness. (自适应)
系统
效果
- 算法
- 从模型上优化,解决OSD增加的问题
- 高效性:训练需要耗时、需要查表
- 系统
- 性能和均匀的权衡,考虑异构环境
- 放置策略:根据环境最优放置
- 动态策略:在初始放置的条件下,根据环境最优迁移调整
- 算法
系统
- collecter:收集并处理指标数据
- model:训练模型
- controller:应用策略
Evaluation
测试平台:Cloudsim、COSBench、fio/rados benchmark
https://github.com/intel-cloud/cosbench
Ceph
真实数据
Related Work
分布算法(见load balancing.md)
强化学习(见RL.md)
强化学习存储研究(见RL.md)
很好的学习教程: https://www.zhihu.com/column/c_1215667894253830144 和 莫凡 https://mofanpy.com/
RL
Evolutionary Population Curriculum for Scaling Multi-Agent Reinforcement Learning
- 主题多智能体缩放问题,ICLR‘20,OpenAI,Facebook,CMU等等
Placement with RL
Towards Self-Managing Cloud Storage with Reinforcement Learning
主题Ceph-RL,机构University of Texas at San Antonio,https://ieeexplore.ieee.org/abstract/document/8789906
IEEE International Conference on Cloud Engineering (IC2E) 2019,未列入ccf推荐,算云计算较好会议
提出:In Ceph,Reinforcement Learning Based Adaptive Load Balancing and Data Migration
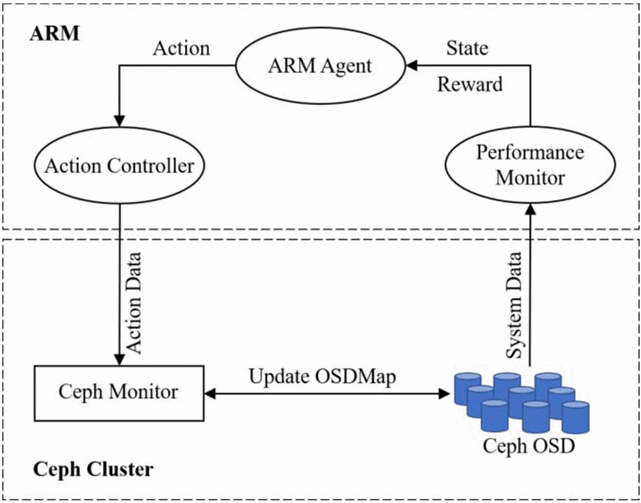
performance hotspots
- 某些osd比其他性能更差,主要原因是硬件异构性、各种后台干扰
- Ceph性能下降:由于CPU、磁盘I/O和各种工作负载混合的网络使用不平衡
负载分析
COSBench的四种不同的工作负载混合

性能热点测试
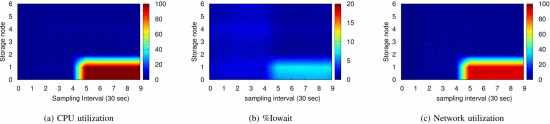
- 8节点OSD,2个OSD有后台干扰
- 从第4个采样间隔开始,后台作业会导致整个Ceph存储节点中CPU,磁盘I / O和网络资源的利用率出现各种程度的不平衡
- CPU利用率
- %iowait:CPU空闲、并且有仍未完成的I/O请求
- 网络利用率
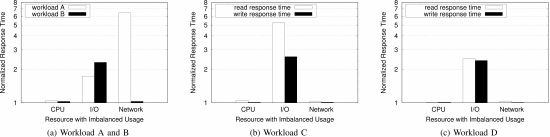
- 在存储节点之间CPU利用率高度不平衡的情况下,COSBench工作负载的性能基本不受影响
- 在网络利用率不平衡的情况下,读工作量大的工作负载A的性能下降很大(平均读响应时间增加了6倍)。但是,其余的工作负载没有受到影响。这是由于工作负载B,C和D中存在大量写操作。由于每个写操作都涉及在网络上所有OSD副本上进行写操作,因此,工作负载B,C和D已经引起Ceph OSD之间的高网络利用率,并且即使没有后台作业的网络干扰,也遭受较大的网络延迟。
- 在后台作业的I / O干扰的情况下,我们发现,就%iowait而言,即使少量的存储节点之间的不平衡也会导致所有COSBench工作负载的性能显着下降。
调控负载均衡旋钮
primary affinity value:决定成为主OSD的概率
- 默认情况下,所有的osd主关联值为1,降低一个osd主关联值可以减少它所服务的读工作量。因此,可以利用primary affinity来调整Ceph osd的读工作负载服务比例。
- 但是只能影响读性能,写性能没影响
OSD weights:决定了OSD中pg数量
权重对读写性能都有影响,但改变权重会导致数据在OSD间迁移,带来相关的开销
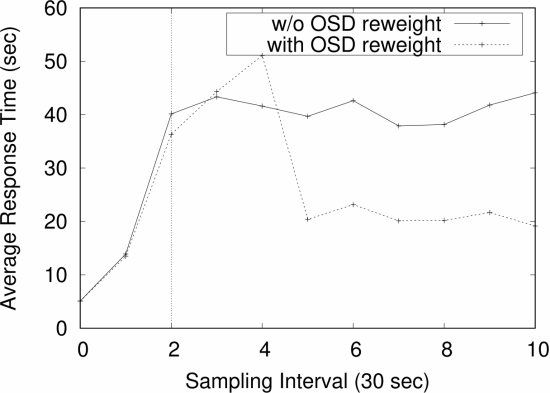
上图可以看出,第二个采样间隔(时间60秒)开始,降低了运行后台作业的两个存储节点的OSD权重
由于OSD重新加权导致数据移动,因此COSBench工作负载A的平均读取响应时间最初会增加
但是,从采样间隔5开始,性能显着提高。这是因为数据从两个性能不佳的OSD迁移到其余OSD,将大部分后续读取请求转移到性能良好的OSD
基于强化学习的负载均衡和数据迁移
- 检测性能指标,通过调整primary affinity和weight来实现负载均衡,提升性能
- state:st=(iowait,rtps,wtps, net)t
- %iowait值、每秒磁盘读请求数、每秒磁盘写请求数、网络利用率
- action:调控
- I/O-based affinity control
- I/O-based OSD reweight
- network-based affinity control
- network-based OSD reweight
- take no action (no-op)
- reward
- 读heavy负载:平均读响应时间的倒数
- 写heavy负载:平均写响应时间的倒数
- 读-写均衡负载:2/(平均读响应时间 + 平均写响应时间)
总结&&问题
- 就是提供了一种类似upmap的工具,来调整集群使得性能最优
- 数据迁移频繁(论文认为不要紧),未考虑节点容量
- 本身的数据监控采集,训练,调控会不会占用资源,影响性能
- 负载类型如何判定
负载均衡
- 节点磁盘容量(数据均衡),数据访问(read/write)负载(负载均衡)
- 设计主pg均衡,其实就是在考虑负载均衡
我们在考虑数据均衡时,是否要考虑负载均衡
- cpu、io、网络等等:这种负载均衡的文章特别多
- 数据迁移量
- 分布式异构环境下的负载均衡
Device Placement Optimization with Reinforcement Learning
主题:RL-Tensorflow中训练操作在各个设备(CPU、GPU)上的分配优化
ICML’17, Azalia Mirhoseini, MIT/Google;Jeff Dean, Google
问题抽象,M->D

寻求最小化执行时间r(P)时,对r(P)的直接优化会导致两个主要问题
- 在训练过程的开始,由于不好的位置采样,r(P)的测量可能是有噪声的,导致不适当的学习信号
- 随着RL模型的逐渐收敛,被采样的位置变得更加相似,相应的运行时间之间的差异较小,导致训练信号的可分辨性较差
问题特点:每个操作之间是有联系的,上个操作会影响下个操作,比较适合用RNN
模型
- attentional RNN / LSTM + Policy Gradients
- 学习参数使用 Adam optimizer ,基于通过REINFORCE方程计算的policy gradients
- 输入
- type:MatMul or conv2d
- output shapes、adj
- Attentional LSTM
- Attention Mechanism:解决变长的输入X映射到一个变长输出Y的问题
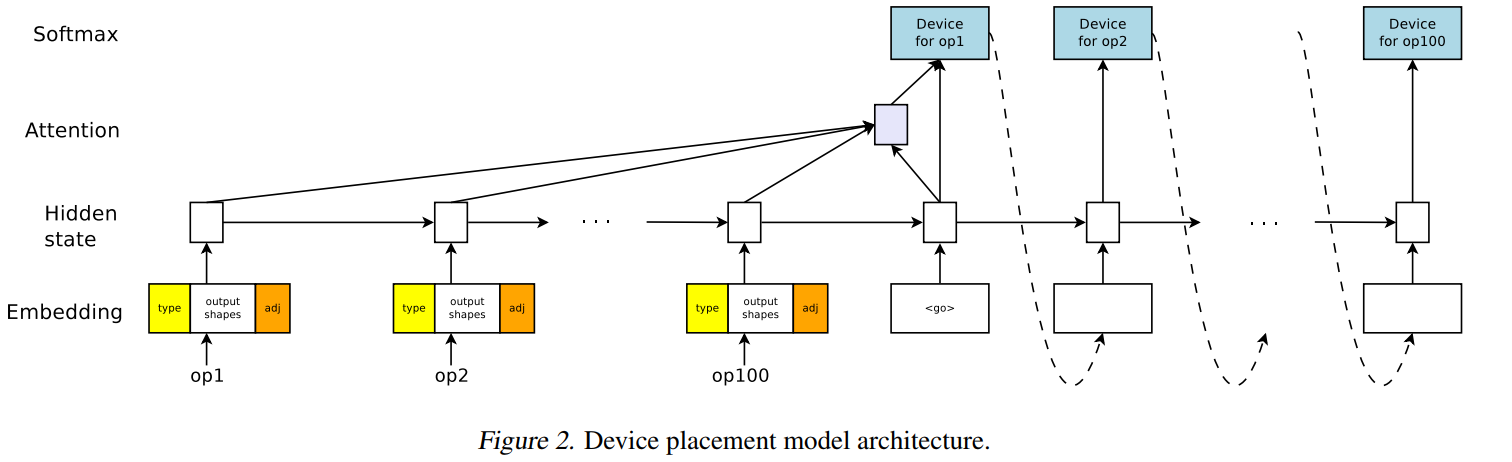
Distributed Training
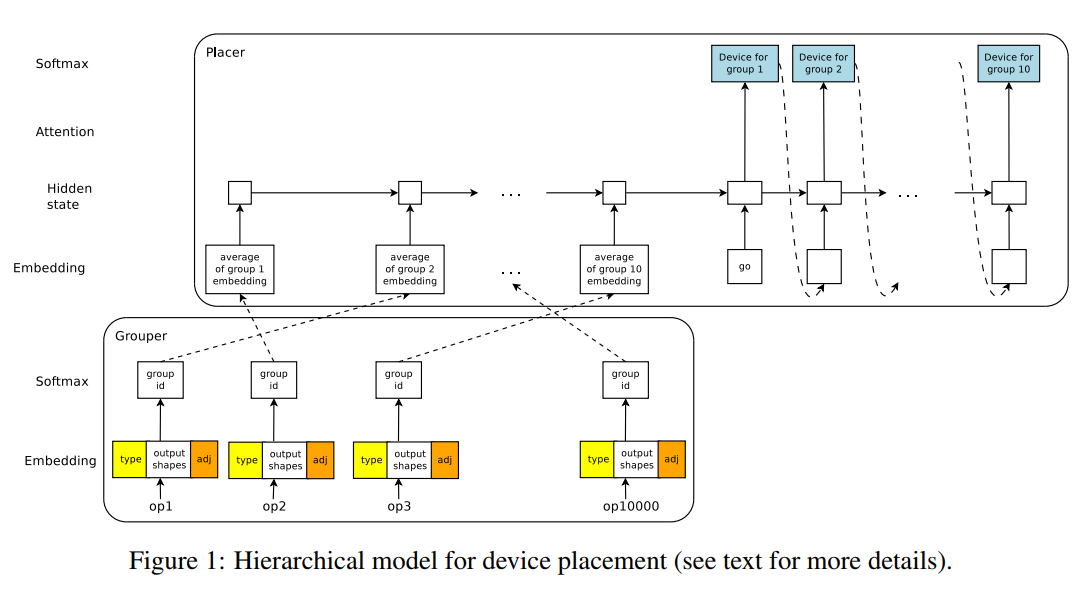
A Hierarchical Model for Device Placement
ICLR’18, Hierarchical Attention Mechanism
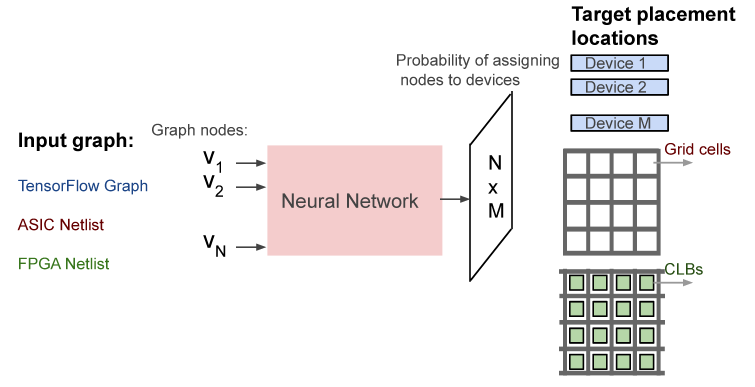
Placement Optimization with Deep Reinforcement Learning
- ISPD’20, Azalia Mirhoseini, MIT/Google
Placement Balance
Mirador: An Active Control Plane for Datacenter Storage
Fast’17,Coho Data,The Load Rebalancing Problem
企业扩展存储产品中的动态放置服务,考虑存储系统的性能、故障响应和工作负载适应相关的多维布局目标
Observe
- 静态特性,如集群拓扑结构(例如,设备和节点的数量、它们的网络链路容量和用户定义的故障域)
- 动态特性,如当前的空闲空间和设备的IO负载以及网络端口的利用率
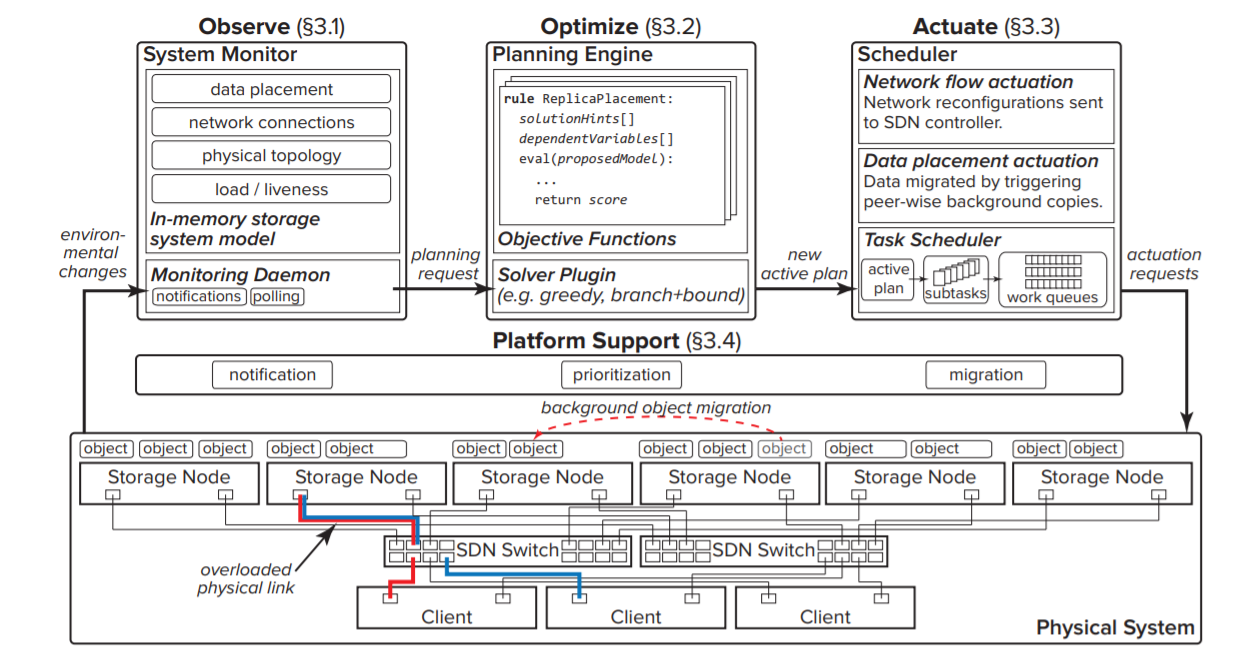
Random Slicing: Efficient and Scalable Data Placement for Large-scale Storage Systems
TOC’14,Barcelona Supercomputing Center
基于动态区间的对象分布算法:该算法将对象映射到(0,1)区间,并将区间划分为多个子区间,每个节点拥有和其权值成正比的多个子区间,以此为依据进行数据映射
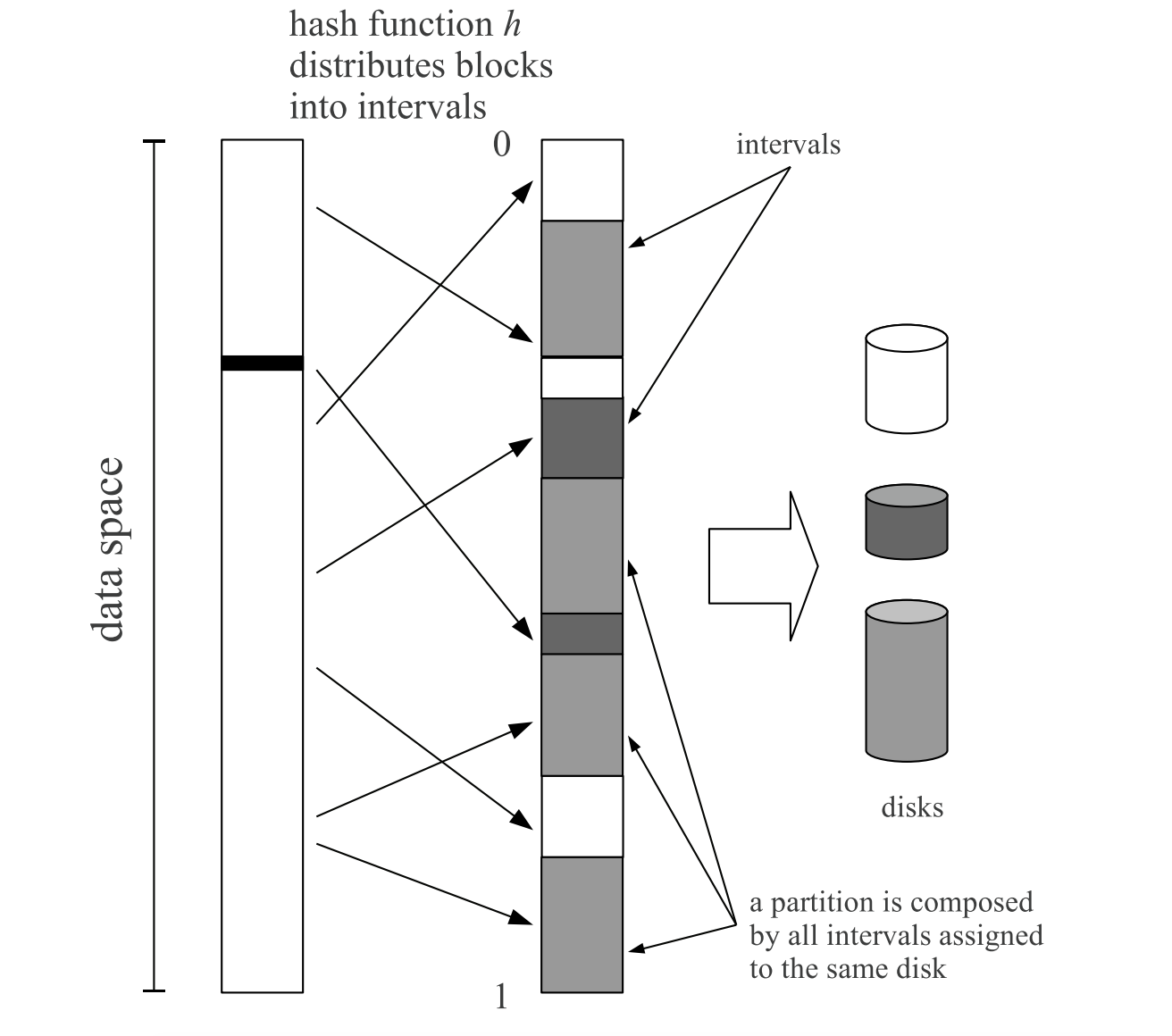
Semantics of caching with SPOCA: a stateless, proportional, optimally-consistent addressing algorithm
ATC‘2011,Yahoo! Inc
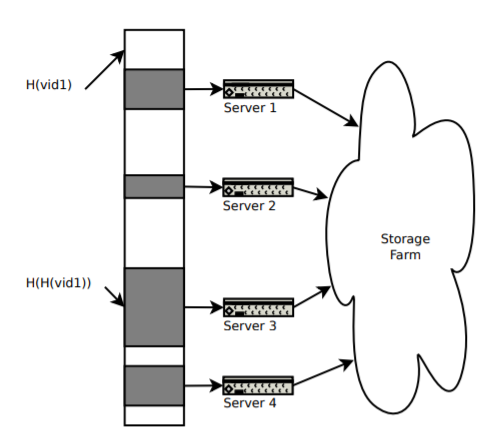
ASURA: Scalable and Uniform Data Distribution Algorithm for Storage Clusters
- 2013年,未发表,引用100多
PRS: A Pattern-Directed Replication Scheme for Heterogeneous Object-Based Storage
TC‘19, IEEE Transactions on Computers,A类期刊,中科院大学,挂了Shuibing He
面向对象存储,高效的异构存储系统复制方案
通过计算对象距离将具有 I/O 相关性的对象聚合到对象组中,并根据识别的应用程序数据访问模式对分组对象进行复制,使用伪随机算法通过考虑存储设备性能和容量特性来优化副本放置
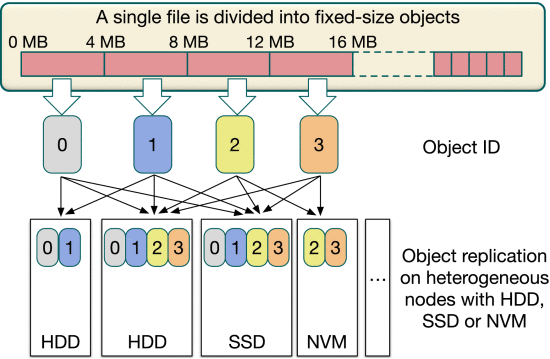
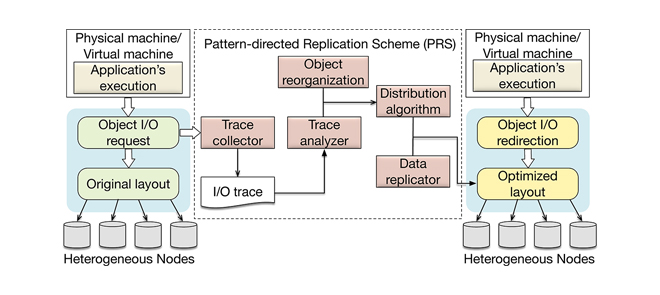
背景
- 单个文件被划分为多个 4 MB 对象。对于每个对象,都有一个与之对应的对象ID,即object0、object1、object2等。对象 ID 唯一标识用于定位的对象。所有对象及其副本分布在不同的节点/设备上进行存储。
- 要考虑异构存储,对象访问模式
设计(PRS )
基于Sheepdog,异构的存储介质
对象第一和第二副本按照Sheepdog的默认数据布局(基于hash)放置
对象的其余副本将通过模式分析使用 PRS 创建
- tracing collector
- 1) 对象 ID,2) 对象中的起始偏移量,3) 访问的大小,4) 访问时间,以及 5) 操作(例如,读或写)
- 在应用程序执行期间在线收集对象 I/O 跟踪,在分布式存储系统中,每个存储节点都会生成一个跟踪文件,其中包含该节点接收或转发的所有 I/O 请求。跟踪文件用于数据访问模式分析和对象重组以在节点中进行复制。
- tracing analyzer
- object reorganization
- distribution algorithm
- data replicator
- tracing collector
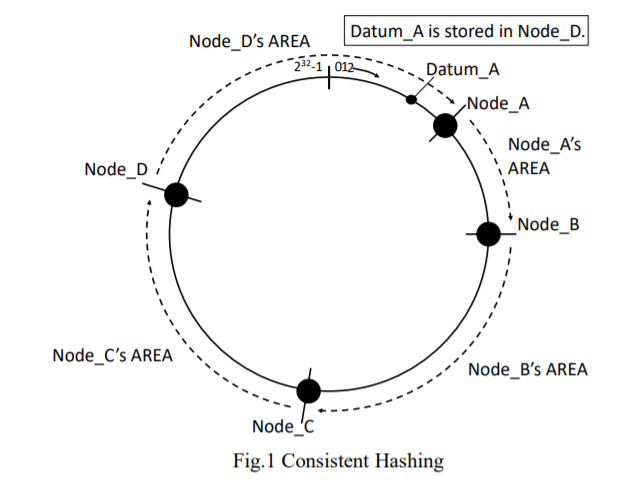
伪随机数算法来优化异构环境中的副本布局
- SPOCA、ASURA;SUORA(同作者)
- consistent hash、crush、random slicing(TOS14)

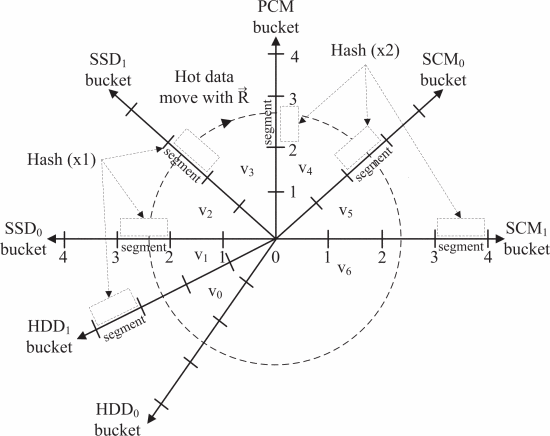
multi-objective optimized replica placement
Dynamic multi-objective optimized replica placement and migration strategies for SaaS applications in edge cloud
国防大学, ACM FGCS‘2019,面向边缘云SaaS应用的副本放置和迁移策略
副本放置原则
- 同一个数据块的不同副本应该放在不同的数据节点上
- 数据副本应该放在高可用的节点上
- 数据块副本应该均匀地放置在整个集群系统中
多目标优化函数 \(min F(x) = [f1(x),f2(x),f3(x)]\)
- f1、f2、f3分别代表文件不可用、节点负载和网络传输成本
- 迁移策略
- 当节点负载高于阈值的时候,需要考虑迁移数据
- 节点负载确定模块。数据节点根据负载状态阈值分为过载节点、均衡节点和低负载节点。当节点的访问负载大于阈值时,需要将节点的部分副本迁移到其他节点以降低负载
- 对于过载的节点,可以根据源节点到目标节点的配对迁移关系,进行特定的动态副本迁移方案。通过快速传播副本,可以获得热点文件所需的副本数量,从而提高系统吞吐量,减少系统响应时间
- 应用 :所提出的复制策略可以应用于社交媒体领域、智能农业、军事领域和交通领域,以满足用户的快速连接、延迟敏感服务和隐私保护需求
其他
- sigmod 2021,西安,6月20 - 25日
ArkDB: a Key-Value Engine for Scalable Cloud Storage Services (阿里)
Learning-Aided Heuristics Design for Storage System (华为)
Chucky: A Succinct Cuckoo Filter for LSM-Tree
Conditional Cuckoo Filters
Nova-LSM: A Distributed, Component-based LSM-tree Key-value Store
FoundationDB: A Distributed Unbundled Transactional Key-Value Store
A-Tree: A Dynamic Data Structure to Efficiently Index Arbitrary Boolean Expressions
- atc 2021,7月14日-16日
Differentiated Key-Value Storage Management for Balanced I/O Performance
Boosting Full-Node Repair in Erasure-Coded Storage
MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices
KVIMR: Key-Value Store Aware Data Management Middleware for Interlaced Magnetic Recording Based Hard Disk Drive
ZNS: Avoiding the Block Interface Tax for Flash-based SSDs
- osdi 2021,7月14日-16日
Modernizing File System through In-Storage Indexing
Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
Rearchitecting Linux Storage Stack for µs latency and High Throughput
Optimizing storage performance with calibrated interrupts
ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Compaction
一. sigmod 2021
概述
- Research Papers 188篇,Industrial Papers 21篇
- https://dblp.org/db/conf/sigmod/sigmod2021.html
- https://2021.sigmod.org/sigmod_research_list.shtml
Nova-LSM: A Distributed, Component-based LSM-tree Key-value Store
为提高资源利用率,本文介绍了一种云原生的分布式KV存储系统,它采用了存算分离的分层结构,该系统由多个组件构成,其中包括LSMtree components (LTCs), logging components (LogCs), 和storage components (StoCs),LTC和StoC是分离的,它们之间通过RDMA进行访问。其中LogC可以与LTC集成到一起,也可以独立运行。本文类似Aurora的架构,能够弹性扩容,实现资源共享,提高资源利用率。并且也针对网络延迟带来的问题,进行了一系列优化。
Chucky: A Succinct Cuckoo Filter for LSM-Tree
NVMe SSD性能提升,与DRAM性能差距进一步缩小,由于在每层都要维护Bloom filter,会引起比较大的查询延迟,引起LSM-Tree中Bloom filter成为新的瓶颈之一(之前的SSD或者HDD等访问延迟较大,Bloom filter引起的开销比重较小,可以忽略不计),本文提出用单个Succinct Cuckoo Filter替代LSM-Tree中的多个Bloom filter,可以有效减少查找引起的开销
FoundationDB: A Distributed Unbundled Transactional Key-Value Store
FoundationDB 是十多年前创建的开源事务键值存储。它是最早结合的系统之一NoSQL 架构的灵活性和可扩展性以及强大的功能ACID 事务(又名 NewSQL)。 FoundationDB 采用了一个解耦内存事务的非捆绑架构管理系统、分布式存储系统和内置分布式配置系统。每个子系统都可以独立配置和配置,以实现所需的可扩展性、高可用性和容错特性。基础数据库独特地集成了一个确定性的模拟框架,用于在无数可能的情况下测试系统的每一个新功能故障。这种严格的测试使 FoundationDB 极其稳定并允许开发人员以一种方式引入和发布新功能节奏快。 FoundationDB 提供了一个最小的和精心挑选的功能集,它启用了一系列不同的系统(从半关系数据库、文档和对象存储,以图数据库等)作为顶层构建。 FoundationDB 是Apple、Snowflake 和其他公司,由于其一致性、稳健性和可用性用于存储用户数据、系统元数据和配置,以及其他关键信息。
ArkDB: a Key-Value Engine for Scalable Cloud Storage Services (阿里)
持久键值存储在启用internet规模的服务方面起着至关重要的作用。阿里巴巴云以分布式键值存储为基础,构建对象存储服务(Object storage Service)、文件存储服务(File storage Service)、表存储(Tablestore)等横向云存储服务。为这些服务设计底层键值引擎的关键挑战在于利用分散存储、支持繁重的写和范围查询工作负载,以及平衡可伸缩性、可用性和资源使用。本文介绍了ArkDB,它是一种键值引擎,通过结合LSM树和bw树的优点,并利用硬件技术的进步来解决这些挑战。ArkDB建立在盘古(Pangu)之上,这是一个只添加的分布式fle系统,ArkDB的创新包括收缩的页面映射表,清晰的系统和用户状态分离,快速恢复,写放大减少,高效的垃圾收集和轻量级的分区拆分和合并。实验结果证明ArkDB对现有设计的改进。与Bwtree相比,尽管写工作集不断增长,ArkDB仍然有效地稳定了映射表的大小。与基于LSM树的key-value引擎RocksDB相比,ArkDB的吞吃吞吐量提高了2.16×,写放大降低了3.1×。它比RocksDB在写重工作负载和范围查询密集型工作负载下的性能分别高出52%和37%。云服务基准。在集群环境中的Tablestore中运行的实验进一步证明了ArkDB的性能盘古及其有效的分区拆分/合并支持。
Learning-Aided Heuristics Design for Storage System (华为)
存储系统等计算机系统通常需要透明的白盒算法,这些算法可以被人类专家解释。在这项工作中,我们提出了一种学习辅助启发式设计方法,它自动生成人类可读的策略从深度强化学习(DRL)代理。该方法受益于深度学习的强大功能,但避免了其黑盒特性的缺点。除了白盒优势,在我们的存储生产的资源分配场景的实验也表明,该解决方案的性能优于系统的默认设置和人工专家精心手工的策略。
二. atc 2021
1. Peeking over the Fence: RDMA (越过栅栏偷看:RDMA)
Session Chairs: Anuj Kalia, Microsoft, and Amy Tai, VMware Research
Naos: Serialization-free RDMA networking in Java
Konstantin Taranov, ETH Zurich; Rodrigo Bruno, INESC-ID / Técnico, ULisboa; Gustavo Alonso and Torsten Hoefler, ETH Zurich
- Java 和 Scala 等托管语言不允许开发人员直接访问堆对象。因此,要通过网络发送堆上数据,必须在发送之前将其显式转换为字节流,并在接收后转换回对象。该技术也称为对象序列化/反序列化,是一种昂贵的过程,限制了基于 JVM 的分布式系统的性能,因为它会导致额外的内存副本并需要数据转换,从而导致高 CPU 和内存带宽消耗。本文介绍了 Naos,这是一种绕过堆序列化边界的基于 JVM 的技术,它允许将对象从本地堆直接发送到远程堆,而 CPU 参与最少,并且通过 RDMA 网络。由于 Naos 消除了复制和转换对象的需要,并支持异步通信,与最先进的序列化库相比,它提供了显着的加速。Naos 公开了一个简单的高级 API,隐藏了 RDMA 协议的复杂性,它透明地允许基于 JVM 的系统利用卸载的 RDMA 网络。
One-sided RDMA-Conscious Extendible Hashing for Disaggregated Memory
Pengfei Zuo, Jiazhao Sun, Liu Yang, and Shuangwu Zhang, Huawei Cloud; Yu Hua, Huazhong University of Science and Technology
- 内存分解是数据中心中一种很有前途的技术,具有提高资源利用率、故障隔离和弹性的好处。散列索引已被广泛用于在分布式内存系统中提供快速查找服务。然而,由于内存池中的计算能力太弱,无法执行复杂的索引请求,因此传统的哈希索引对于分解内存变得效率低下。为了在分解内存场景下提供高效的索引服务,本文提出了RACE hashing,一种单边RDMA-Conscious可扩展哈希索引,具有无锁远程并发控制和高效远程调整大小。RACE 哈希使所有索引操作都能够通过仅使用单方面的 RDMA 动词来高效执行,而无需涉及内存池中的任何计算资源。为了支持高性能的远程并发访问,RACE hashing利用了无锁的远程并发控制方案,使不同的客户端能够以无锁的方式并发操作内存池中的同一个哈希索引。为了以低开销调整哈希表的大小,RACE 哈希利用可扩展的远程调整大小方案来减少由可扩展调整大小引起的额外 RDMA 访问,并允许在调整大小期间并发请求执行。
- 大量实验结果表明,在 YCSB 混合工作负载中,RACE 散列比最先进的分布式内存中散列索引的性能高 1.4 - 13.7 倍。为了以低开销调整哈希表的大小,RACE 哈希利用可扩展的远程调整大小方案来减少由可扩展调整大小引起的额外 RDMA 访问,并允许在调整大小期间并发请求执行。大量实验结果表明,在 YCSB 混合工作负载中,RACE 散列比最先进的分布式内存中散列索引的性能高 1.4 - 13.7 倍。为了以低开销调整哈希表的大小,RACE 哈希利用可扩展的远程调整大小方案来减少由可扩展调整大小引起的额外 RDMA 访问,并允许在调整大小期间并发请求执行。大量实验结果表明,在 YCSB 混合工作负载中,RACE 散列比最先进的分布式内存中散列索引的性能高 1.4 - 13.7 倍。
Characterizing and Optimizing Remote Persistent Memory with RDMA and NVM
Xingda Wei, Xiating Xie, Rong Chen, Haibo Chen, and Binyu Zang, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems
- NVM 的吸引人的特性包括高性能、持久性和字节寻址能力,以及最近使用 RDMA 构建远程内存系统的活动线程,已经引起了人们对将它们组合成快速和持久远程内存系统的极大兴趣。然而,许多先前的系统要么基于仿真 NVM,要么未能充分利用 NVM 特性,导致性能欠佳。
- 本文进行了系统研究,以总结系统设计人员可以用来更好地利用 RDMA 开发 NVM 的优化提示。具体来说,我们演示了系统配置、NVM 访问模式和 RDMAaware 优化如何影响 RDMA-NVM 系统的功效。基于总结的提示,我们实证研究了两个现有 RDMA-NVM 系统的设计,即分布式数据库(DrTM+H)和分布式文件系统(Octopus)。这两个系统都是在没有生产 NVM 可用的情况下设计的,并且它们都没有在其上实现良好的性能。我们优化的系统实现了高达 2.4 倍(从 1.2 倍)更好的性能
MigrOS: Transparent Live-Migration Support for Containerised RDMA Applications
Maksym Planeta and Jan Bierbaum, TU Dresden; Leo Sahaya Daphne Antony, AMOLF; Torsten Hoefler, ETH Zürich; Hermann Härtig, TU Dresden
- RDMA 网络将数据包处理卸载到网络接口控制器 (NIC) 的专用电路上,并绕过操作系统以改善网络延迟和带宽。因此,操作系统失去了对活动 RDMA 连接的控制,并失去了透明迁移 RDMA 应用程序的可能性。本文介绍了 MigrOS,这是一种操作系统级架构,用于容器化 RDMA 应用程序的透明实时迁移。MigrOS 表明,对 RDMA 通信协议的一组最小更改可以重新启用实时迁移,而无需插入关键路径操作。我们的方法不需要对用户应用程序进行任何更改,并在网络堆栈的各个级别保持向后兼容性。总体而言,与纯软件技术相比,MigrOS 最多可将网络延迟降低 33%。
2. Dogs Never Get Tired: Power and Edge Computing (狗永远不会累:功率和边缘计算)
Session Chairs: Marcelo Martins, Apple, and Dilma da Silva, Texas A&M University
Prediction-Based Power Oversubscription in Cloud Platforms
Alok Gautam Kumbhare, Reza Azimi, Ioannis Manousakis, Anand Bonde, Felipe Frujeri, Nithish Mahalingam, Pulkit A. Misra, Seyyed Ahmad Javadi, Bianca Schroeder, Marcus Fontoura, and Ricardo Bianchini, Microsoft Research and Microsoft Azure
- 之前的工作使用功率上限来消除罕见的功率峰值并向数据中心添加更多服务器,从而超额订阅其资源并降低资本成本。当工作负载及其服务器位置已知时,这很有效。不幸的是,这些因素在公共云中是未知的,迫使提供商限制超额订阅,从而限制功率上限带来的潜在性能损失。
- 在本文中,我们认为提供商可以使用工作负载性能关键性和虚拟机 (VM) 资源利用率的预测来增加超额订阅。这带来了许多挑战,例如从不透明的 VM 中识别对性能至关重要的工作负载,创建对关键性感知电源管理的支持,以及在限制上限影响的同时增加超额订阅。我们解决了 Microsoft Azure 硬件和软件的这些挑战。结果表明,我们在对关键工作负载影响最小的情况下使超额订阅增加了 2 倍。我们描述了在生产中部署工作的经验教训。
Proactive Energy-Aware Adaptive Video Streaming on Mobile Devices
Jiayi Meng, Qiang Xu, and Y. Charlie Hu, Purdue University
- 能源感知应用程序自适应使移动应用程序能够动态调整数据保真度,例如流视频质量,以满足用户指定的电池持续时间目标。传统的能量感知应用程序自适应本质上是被动的,其中操作系统监控应用程序的能量消耗,并在检测到能量消耗偏离预先指定的能量预算时向应用程序发出信号以适应,这可能导致高振荡和较差的体验质量(体验质量)。
- 在本文中,我们观察到现代耗电应用程序(例如视频流和基于卸载的应用程序)已经具有复杂的应用程序自适应功能,以处理网络动态等资源变化,并提出了主动的能量感知自适应,其中用户指定的能量预算集成了app适配逻辑。这种方法的潜在好处是应用程序能量消耗适应不再是“后遗症”,因此该方法可能会减少应用程序适应中的振荡并提高应用程序 QoE。
- 在本文中,我们在最耗电的移动应用类别之一、基于 ABR 的视频流的背景下研究了被动和主动能量感知应用适应的设计、实现和性能权衡。我们的研究表明,主动式能量感知 ABR 视频流很容易通过利用现代应用程序的内置适应来实现,并且可以将反应式方法的 QoE 提高 44.8% 和 19.2% 将 360 度视频流式传输到 Pixel 2 和 Moto低功耗预算下的 Z3 手机。
Video Analytics with Zero-streaming Cameras
Mengwei Xu, Peking University/Beijing University of Posts and Telecommunications; Tiantu Xu, Purdue ECE; Yunxin Liu, Institute for AI Industry Research (AIR), Tsinghua University; Felix Xiaozhu Lin, University of Virginia
- 低成本相机可实现强大的分析。一个未开发的机会是,大多数捕获的视频在没有被查询的情况下保持“冷”状态。为了提高效率,我们提倡这些摄像头零流传输:仅在需要分析时才将视频捕获到本地存储并与云通信。
- 如何高效查询零流摄像头?我们的回应是一个名为 DIVA 的相机/云运行时系统。它解决了两个关键挑战:在视频捕获期间最好地利用有限的相机资源;在查询执行期间快速浏览海量视频。 DIVA 贡献了两种非常规技术。 (1) 在捕获视频时,相机会构建稀疏但准确的地标帧,从中学习可靠的知识以加速未来的查询。 (2) 在执行查询时,相机会使用越来越昂贵的运算符在多遍中处理帧。因此,DIVA 会在整个查询执行过程中呈现并不断优化不准确的查询结果。在总共持续 720 小时的超过 15 个视频的各种查询中,DIVA 以超过 100 倍的视频实时运行,并且优于竞争性替代设计。据我们所知,DIVA 是第一个查询存储在低成本远程摄像机上的大型视频的系统。
ASAP: Fast Mobile Application Switch via Adaptive Prepaging
Sam Son, Seung Yul Lee, Yunho Jin, and Jonghyun Bae, Seoul National University; Jinkyu Jeong, Sungkyunkwan University; Tae Jun Ham and Jae W. Lee, Seoul National University; Hongil Yoon, Google
- 随着移动应用程序对内存容量的需求不断增加,以及同时运行的应用程序数量的稳步增长,内存容量正在成为移动设备上的稀缺资源。当内存压力较大时,当前的移动操作系统经常会杀死最近没有使用过的应用进程来回收内存空间。当用户重新启动被终止的应用程序时,这会导致很长的延迟,从而降低用户体验。即使禁用此机制以使用基于压缩的内存交换机制,重新启动应用程序仍然会导致大量延迟损失,因为它需要解压缩压缩的匿名页面和 I/O 访问流以检索文件支持的页面进入记忆。本文将传统的需求分页确定为这种低效率的主要来源,并提出了 ASAP,这是一种通过移动设备上的自适应准备实现快速应用程序切换的机制。ASAP 通过结合 i) 用于文件支持页面和匿名页面的高精度切换足迹估计器,以及 ii) 有效实现准备机制来执行准备工作,以最大限度地减少应用程序切换期间 CPU 周期和磁盘带宽的资源浪费。
- 我们在 Google Pixel 4 和 Pixel 3a 上使用八个实际应用程序进行的评估表明,与 vanilla 相比,ASAP 可以分别将切换时间平均分别减少 22.2% 和 28.3%(分别最大为 33.3% 和 35.7%)安卓 10. ASAP 通过结合 i) 用于文件支持页面和匿名页面的高精度切换足迹估计器,以及 ii) 有效实现准备机制来执行准备工作,以最大限度地减少应用程序切换期间 CPU 周期和磁盘带宽的资源浪费。我们在 Google Pixel 4 和 Pixel 3a 上使用八个实际应用程序进行的评估表明,与 vanilla 相比,ASAP 可以分别将切换时间平均分别减少 22.2% 和 28.3%(分别最大为 33.3% 和 35.7%)安卓 10. ASAP 通过结合 i) 用于文件支持页面和匿名页面的高精度切换足迹估计器,以及 ii) 有效实现准备机制来执行准备工作,以最大限度地减少应用程序切换期间 CPU 周期和磁盘带宽的资源浪费。我们在 Google Pixel 4 和 Pixel 3a 上使用八个实际应用程序进行的评估表明,与 vanilla 相比,ASAP 可以分别将切换时间平均分别减少 22.2% 和 28.3%(分别最大为 33.3% 和 35.7%)安卓 10.
3. Barking up the Wrong Tree: Correctness and Debugging (挑错树:正确性和调试)
Session Chairs: Eric Schkfuza, Amazon, and Pedro Fonseca, Purdue University
PYLIVE: On-the-Fly Code Change for Python-based Online Services
Haochen Huang, Chengcheng Xiang, Li Zhong, and Yuanyuan Zhou, University of California, San Diego
- Python 正在成为许多公司构建在线 Web 服务的流行语言。为了提高在线服务的健壮性,本文提出了一个名为 PYLIVE 的新框架,以实现动态代码更改。PYLIVE 利用 Python、元对象协议和动态类型的独特语言特性,支持动态日志记录、分析和错误修复,而无需重新启动在线服务。PYLIVE 不需要对底层运行时系统(即 Python 解释器)进行修改,这使得它很容易被在线服务采用,几乎没有可移植性问题。
- 我们使用七个广泛用于在线服务的基于 Python 的 Web 应用程序评估了 PYLIVE。从这些应用程序中,我们收集了 20 个现有的真实案例,包括用于评估的错误、性能问题和补丁。PYLIVE 可以通过以很少的开销提供动态日志记录、分析和修补来帮助解决所有情况。此外,PYLIVE 还帮助诊断了两个广泛使用的开源应用程序中的两个新的性能问题。
RIFF: Reduced Instruction Footprint for Coverage-Guided Fuzzing
Mingzhe Wang, Jie Liang, Chijin Zhou, and Yu Jiang, Tsinghua University; Rui Wang, Capital Normal University; Chengnian Sun, Waterloo University; Jiaguang Sun, Tsinghua University
- 覆盖引导的模糊器使用程序覆盖测量来有效地探索不同的程序路径。覆盖管道由运行时收集和执行后处理过程组成。首先,目标程序执行检测代码以收集覆盖率信息。然后模糊器对收集的数据执行昂贵的分析,但大多数程序执行不会导致覆盖率增加。这些步骤的低效实现显着降低了模糊器的整体吞吐量。
- 在本文中,我们提出了 RIFF,一种高效的程序覆盖测量机制,以减少模糊测试开销。对于目标程序,RIFF 通过静态程序分析将最初在运行时完成的计算移动到检测时间,从而将检测代码减少到最低限度。对于模糊器,RIFF 处理具有不同粒度级别的覆盖范围,并利用向量指令来提高吞吐量。
- 我们在 AFL 和 MOpt 等最先进的模糊器中实施 RIFF,并在 Google 的 FuzzBench 和模糊器测试套件中评估其在真实世界程序中的性能。结果表明,RIFF 在运行时收集和执行后处理期间分别将模糊器的覆盖测量效率提高了 23 倍和 6 倍。结果,模糊器完成的执行次数增加了 147%,并且平均只用了 6.53 小时就达到了基线模糊器的 24 小时覆盖率。
TCP-Fuzz: Detecting Memory and Semantic Bugs in TCP Stacks with Fuzzing
Yong-Hao Zou and Jia-Ju Bai, Tsinghua University; Jielong Zhou, Jianfeng Tan, and Chenggang Qin, Ant Group; Shi-Min Hu, Tsinghua University
- TCP 协议栈在网络中提供可靠的数据传输,因此应正确实施并经过良好测试以确保可靠性和安全性。但是,测试 TCP 堆栈很困难。首先,TCP 堆栈接受彼此之间具有依赖关系的数据包和系统调用,因此生成有效的测试用例具有挑战性。其次,TCP 堆栈具有各种复杂的状态转换,但现有的测试方法以覆盖状态为目标,而不是覆盖状态转换,因此其测试覆盖范围有限。最后,我们对 TCP 堆栈提交的研究表明,87% 的错误修复提交与语义错误(例如 RFC 违规)有关,但现有的错误清理器只能检测内存错误,而不能检测语义错误。
- 在本文中,我们设计了一个名为 TCP-Fuzz 的新型模糊测试框架,以有效地测试 TCP 堆栈并检测错误。TCP-Fuzz 包含三个关键技术: (1) 基于依赖的策略,考虑数据包和系统调用之间的依赖关系,生成有效的测试用例;(2) 一种转移引导的模糊测试方法,它使用名为分支转移的新覆盖度量作为程序反馈,以提高状态转移的覆盖率;(3) 一个差分检查器,它比较相同输入的多个 TCP 堆栈的输出,以检测语义错误。我们在五个广泛使用的 TCP 堆栈(TLDK、F-Stack、mTCP、FreeBSD TCP 和 Linux TCP)上评估了 TCP-Fuzz,并发现了 56 个真正的错误(包括 8 个内存错误和 48 个语义错误)其中 40 个漏洞已得到相关开发人员的确认。
MLEE: Effective Detection of Memory Leaks on Early-Exit Paths in OS Kernels
Wenwen Wang, University of Georgia
- 操作系统 (OS) 内核中的内存泄漏会导致严重的性能和安全问题。然而,由于现实世界操作系统内核的固有复杂性和大规模代码库,检测内存泄漏非常具有挑战性。在这项工作中,受到软件错误通常隐藏在很少测试的程序路径中的观察的启发,我们专注于检测操作系统内核中早期退出 (EE) 路径上的内存泄漏。为此,我们对 OS 内核中的 EE 路径所涉及的内存管理操作进行了系统研究。基于这些发现,我们为 OS 内核设计了一种新颖的泄漏检测器:MLEE,它通过交叉检查不同 EE 路径和正常路径上内存释放的存在,智能地发现 EE 路径上的内存泄漏。MLEE 成功报告了 Linux 内核中的 120 个新的内存泄漏错误。
Argus: Debugging Performance Issues in Modern Desktop Applications with Annotated Causal Tracing
Lingmei Weng, Columbia University; Peng Huang, Johns Hopkins University; Jason Nieh and Junfeng Yang, Columbia University
- 现代桌面应用程序涉及许多异步、并发交互,这使得性能问题难以诊断。尽管之前的工作使用因果跟踪来调试分布式系统中的性能问题,但我们发现这些技术在桌面应用程序中存在很高的不准确性。我们展示了 Argus,这是一种快速、有效的因果跟踪工具,用于调试桌面应用程序中的性能异常。Argus 引入了一种新的强边和弱边概念来显式地建模和注释迹线图的歧义,一种新的基于波束搜索的诊断算法,用于在存在歧义的情况下选择最可能的因果路径,以及一种比较因果路径的新方法。正常和异常执行。我们已经在多个版本的 macOS 中实施了 Argus,并在流行的 macOS 应用程序中对 12 个臭名昭著的旋转风车问题进行了评估。阿格斯诊断了所有问题的根本原因,其中 10 个以前未知,其中一些已经开放了好几年。启用系统范围的跟踪后,Argus 产生的 CPU 开销不到 5%,从而使始终在线的跟踪变得可行。
4. Searching for Tracks: Graphs (搜索曲目:Graphs )
Session Chairs: Laurent Bindschaedler, Massachusetts Institute of Technology, and Dalit Naor, The Academic College of Tel Aviv-Yaffo
aDFS: An Almost Depth-First-Search Distributed Graph-Querying System
Vasileios Trigonakis and Jean-Pierre Lozi, Oracle Labs; Tomáš Faltín, Oracle Labs and Charles University; Nicholas P. Roth, KUNGFU.AI; Iraklis Psaroudakis, Arnaud Delamare, Vlad Haprian, Călin Iorgulescu, Petr Koupy, Jinsoo Lee, Sungpack Hong, and Hassan Chafi, Oracle Labs
- 图处理是数据分析的宝贵工具。特别是,模式匹配查询支持灵活的图形探索和分析,类似于 SQL 为关系数据库提供的功能。图查询侧重于跟踪数据中的连接;它们是一项具有挑战性的工作量,因为即使是看似微不足道的查询也很容易产生数十亿个中间结果和不规则的数据访问模式。
- 在本文中,我们介绍了 aDFS:一种分布式图形查询系统,它几乎可以完全在内存中处理任何查询,同时保持有限的运行时内存消耗。为了实现这种行为,aDFS 依赖于 (i) 具有一些广度优先特性的几乎深度优先 (aDFS) 图探索,以及 (ii) 将中间结果非阻塞分派到远程边缘。我们针对最先进的图形查询(Neo4J 和 Apache Spark 的 GraphFrames)、图形挖掘(G-Miner、Fractal 和 Peregrine)以及数据流连接 (BiGJoin) 评估 aDFS,并表明 aDFS在各种工作负载上的表现明显优于之前的工作。
GLIST: Towards In-Storage Graph Learning
Cangyuan Li, Ying Wang, Cheng Liu, and Shengwen Liang, SKLCA, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; Huawei Li, SKLCA, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; Peng Cheng Laboratory, Shenzhen, China; Xiaowei Li, SKLCA, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China
- 图学习是一种新兴技术,广泛用于各种应用,如推荐系统和药物设计。现实世界的图学习应用程序通常在具有丰富信息的大型属性图上运行,这些图不适合内存。因此,图学习请求必须穿过深度 I/O 堆栈并将大量数据从存储移动到主机内存,这会导致相当大的延迟和功耗。为了解决这个问题,我们开发了 GLIST,一种高效的存储图学习系统,用于处理 SSD 内的图学习请求。它在存储中实现了定制的图学习加速器,使存储能够直接响应图学习请求。因此,与传统的基于 GPGPU 的系统相比,GLIST 大大减少了数据移动开销。此外,GLIST 提供了一组高级图学习 API,允许开发人员方便地部署他们的图学习服务。在基于 FPGA 的原型上的实验结果表明,与基于 CPU 和 GPU 的解决方案相比,GLIST 在一系列图学习任务上实现了 13.2 倍和 10.1 倍的平均加速比,并分别降低了高达 98.7% 和 98.0% 的功耗。
DART: A Scalable and Adaptive Edge Stream Processing Engine
Pinchao Liu, Florida International University; Dilma Da Silva, Texas A&M University; Liting Hu, Virginia Tech
- 许多物联网 (IoT) 应用程序对时间要求严格且动态变化。然而,传统的数据处理系统(例如,流处理系统、基于云的物联网数据处理系统、广域数据分析系统)并不适合这些物联网应用。这些系统通常不能很好地扩展大量并发运行的物联网应用程序,不支持有限计算资源下的低延迟处理,并且不适应边缘环境中普遍存在的异构和动态水平。这表明需要一种新的边缘流处理系统来推进流处理范式,以在边缘计算架构提出的约束下实现效率和灵活性。
- 我们展示了 Dart,这是一种可扩展且自适应的边缘流处理引擎,可在动态边缘环境中快速处理大量并发运行的 IoT 应用程序查询。我们工作的新颖之处在于通过利用基于分布式哈希表 (DHT) 的点对点 (P2P) 覆盖网络引入动态数据流抽象,该网络可以自动放置、链接和扩展流操作符以减少查询延迟,适应边缘动态,并从故障中恢复。
- 我们通过分析和经验表明,Dart 在查询延迟方面优于 Storm 和 EdgeWise,并且在处理大量现实世界物联网流应用程序的查询时显着提高了可扩展性和适应性。Dart 显着缩短了应用程序部署设置时间,成为第一个支持边缘平台物联网应用程序 DevOps 的流媒体引擎。
CrystalPerf: Learning to Characterize the Performance of Dataflow Computation through Code Analysis
Huangshi Tian, HKUST; Minchen Yu, HKUST and Huawei Technologies Ltd.; Wei Wang, HKUST
- 数据流计算在大数据处理领域占据主导地位,其中程序被构造为操作的有向无环图 (DAG)。由于数据流计算在集群中消耗大量资源,因此了解其性能变得至关重要。然而,由于 DAG 执行的复杂性,这在实践中可能很困难。在本文中,我们提出了一种新方法,该方法基于代码分析来学习表征数据流计算的性能。与现有的性能推理技术不同,我们的方法不需要代码检测并适用于各种数据流框架. 我们的主要见解是操作的源代码包含可学习的句法和语义模式,揭示了它如何使用资源。我们的方法建立了一个性能资源模型,在给定数据流程序的情况下,使用机器学习技术从过去的执行跟踪和程序源代码中自动推断每个操作在每个资源(例如 CPU、网络、磁盘)上花费了多少时间. 然后我们使用该模型来预测不同资源配置下的程序运行时间。我们已将我们的解决方案实现为名为 CrystalPerf 的 CLI 工具。在 Spark、Flink 和 TensorFlow 中的广泛评估表明,CrystalPerf 可以高精度预测多种资源配置变化下的作业性能。
Controlling Memory Footprint of Stateful Streaming Graph Processing
Pourya Vaziri and Keval Vora, Simon Fraser University
- 随着对有效分析动态图的发展,流图处理系统依赖有状态的迭代模型,在执行过程中跟踪中间状态,以便在图突变时逐步调整结果。我们观察到这些有状态迭代模型跟踪的中间状态显着增加了这些系统的内存占用,这限制了它们在大图上的可扩展性。
- 在本文中,我们开发了内存高效的状态迭代模型,该模型需要更少的内存容量来有效处理流图并提供与现有状态迭代模型提供的相同结果。首先,我们提出了一种选择性状态迭代模型,其中通过选择要在整个执行过程中维护的一小部分中间状态来控制内存占用。然后,我们提出了一个最小状态迭代模型通过利用图算法的关键属性,进一步减少了内存占用。我们为我们的两个模型开发了增量处理策略,以便即使在中间状态不可用的情况下也能正确计算图突变对最终结果的影响。评估表明,我们的内存高效模型在限制内存占用方面是有效的,同时仍然保留了传统有状态迭代模型的大部分性能优势,因此能够在传统模型无法处理的较大图上进行扩展。
5. Please Don’t Chain Me Up: Blockchain and Security(请不要束缚我:区块链和安全性)
Session Chairs: Amy Tai and Adriana Szekeres, VMware Research
Avocado: A Secure In-Memory Distributed Storage System
Maurice Bailleu, Dimitra Giantsidi, and Vasilis Gavrielatos, University of Edinburgh; Do Le Quoc, Huawei Research; Vijay Nagarajan, University of Edinburgh; Pramod Bhatotia, University of Edinburgh and TU Munich
- 我们介绍了 Avocado,这是一种安全的内存分布式存储系统,可为不受信任的云环境提供强大的安全性、容错性、一致性(线性化)和性能。 Avocado 基于 TEE 实现了这些特性,然而,TEE 主要用于保护单节点系统内有限的物理内存(飞地)。 Avocado 通过将安全的单节点 enclave 的信任扩展到不受信任的网络上的分布式环境来克服这一限制,同时确保副本在恶意环境中保持一致和容错。为了实现这些目标,我们设计并实现了基于跨层贡献的 Avocado,包括网络堆栈、复制协议、可扩展信任建立和内存管理。 Avocado 很实用:与 BFT 相比,Avocado 以更少的副本提供机密性,并且速度明显更快——YCSB 读写繁重的工作负载分别为 4.5 倍到 65 倍。
Accelerating Encrypted Deduplication via SGX
Yanjing Ren and Jingwei Li, University of Electronic Science and Technology of China; Zuoru Yang and Patrick P. C. Lee, The Chinese University of Hong Kong; Xiaosong Zhang, University of Electronic Science and Technology of China
- 加密重复数据删除保留了加密数据重复数据删除的有效性,对外包存储具有吸引力。然而,现有的加密重复数据删除方法建立在昂贵的加密原语之上,这会导致性能大幅下降。我们展示了 SGXDedup,它利用英特尔 SGX 加速基于服务器辅助消息锁定加密 (MLE) 的加密重复数据删除,同时通过 SGX 保持安全性。SGXDedup 实现了一套安全接口,以在 SGX 飞地中执行 MLE 密钥生成和所有权证明操作。它还提出了各种设计来支持安全和高效的飞地操作。对合成和实际工作负载的评估表明,SGXDedup 实现了显着的加速并保持了高带宽和存储节省。
ICARUS: Attacking low Earth orbit satellite networks
Giacomo Giuliari, Tommaso Ciussani, Adrian Perrig, and Ankit Singla, ETH Zurich
- 由于具有全球低延迟连接的潜力,基于低地球轨道卫星的互联网服务在网络社区中引起了极大的兴奋。尽管 LEO 卫星网络前景广阔,但迄今为止,其运行的安全性在很大程度上被忽视了。在此背景下,我们介绍了 ICARUS,这是一种针对 LEO 网络的新型拒绝服务攻击。
- ICARUS 将这些网络的主要优势转化为漏洞:对手可以利用直接的全球可访问性从多个位置发起攻击,而对低延迟的追求限制了路由,并为对手提供了可预测性。我们探索对手如何利用其他独特功能,包括此类网络的路径结构,以及卫星路由器位置和连接性的公共知识。我们发现少量的攻击带宽会阻碍大面积陆地区域之间的通信。最后,我们在这个方向上列出了未解决的问题,并提供了一个框架,以便在这种情况下进一步研究攻击和防御。
RainBlock: Faster Transaction Processing in Public Blockchains
Soujanya Ponnapalli, Aashaka Shah, and Souvik Banerjee, University of Texas at Austin; Dahlia Malkhi, Diem Association and Novi Financial; Amy Tai, VMware Research; Vijay Chidambaram, University of Texas at Austin and VMware Research; Michael Wei, VMware Research
- 我们提出了 RAINBLOCK,这是一种公共区块链,可在不修改工作量证明共识的情况下实现高交易吞吐量。RAINBLOCK 背后的主要观点是,虽然共识控制了新区块添加到区块链的速度,但每个区块中的交易数量受到 I/O 瓶颈的限制。像以太坊这样的公共区块链将每个区块中的交易数量保持在较低水平,以便所有参与的服务器(矿工)有足够的时间在创建下一个区块之前处理一个区块。通过消除交易处理中的 I/O 瓶颈,RAINBLOCK 允许矿工在相同的时间内处理更多的交易。RAINBLOCK 做出了两个新的贡献:从处理事务 (txs) 的关键路径中移除 I/O 的 RAINBLOCK 架构,以及分布式、有效存储系统状态的多版本 DSM-TREE 数据结构。我们使用基于公共以太坊跟踪(包括智能合约)的工作负载来评估 RAINBLOCK。我们展示了单个 RAINBLOCK 矿工每秒处理 27.4K txs(比单个以太坊矿工高 27 倍)。在跨越三大洲的四个区域的地理分布式设置中,RAINBLOCK 矿工每秒处理 20K txs。
An Off-The-Chain Execution Environment for Scalable Testing and Profiling of Smart Contracts
Yeonsoo Kim and Seongho Jeong, Yonsei University; Kamil Jezek, The University of Sydney; Bernd Burgstaller, Yonsei University; Bernhard Scholz, The University of Sydney
- 以太坊中的智能合约是部署在区块链上的可执行程序,需要客户端才能执行。当客户端执行智能合约时,包含合约存储和帐户详细信息的世界状态会以一致的方式更改。因此,智能合约的执行必须是顺序的,以确保世界状态的确定性表示。由于最近的增长,世界状态变得臃肿,使得大规模测试和分析以太坊交易变得非常困难。
- 在这项工作中,我们引入了一种新颖的链下执行环境,用于智能合约的可扩展测试和分析。我们通过使用子状态隔离和并行执行事务来断开事务与世界状态的连接。与以太坊客户端相比,我们的执行环境将重放初始 9 M 块的交易所需的空间从 700.11 GB 减少到 285.39 GB。我们将吞吐量从 620.62 tx/s 增加到 2,817.98 tx/s(单线程)和 30,168.76 tx/s(扩展到 44 个内核)。我们展示了用于硬分叉测试、智能合约指标评估和合约模糊测试的链下执行环境的可扩展性。
6. I’m Old But I Learned a New Trick: Machine Learning (我老了,但我学到了一个新技巧:机器学习)
Session Chairs: Sangeetha Abdu Jyothi, University of California, Irvine, and VMware Research, and Justin Gottschlich, Intel Labs and University of Pennsylvania
Octo: INT8 Training with Loss-aware Compensation and Backward Quantization for Tiny On-device Learning
Qihua Zhou and Song Guo, Hong Kong Polytechnic University; Zhihao Qu, Hohai University; Jingcai Guo, Zhenda Xu, Jiewei Zhang, Tao Guo, and Boyuan Luo, Hong Kong Polytechnic University; Jingren Zhou, Alibaba Group
- 设备上学习是一种新兴技术,可为实现边缘智能铺平最后一英里,它消除了需要数十种计算能力和内存的传统云计算的局限性。高性能的设备端学习系统需要打破有限资源的约束,减轻计算开销。在本文中,我们展示了在深度模型的前向和后向传递中采用 8 位定点 (INT8) 量化是在实践中实现微型设备学习的一种很有前途的方法。有效的量化感知训练方法的关键是利用硬件级启用的加速,同时保持每一层的训练质量。然而,现成的量化方法无法处理定点处理的设备上学习范式。为了克服这些挑战,我们提出了一种新颖的 INT8 训练方法,该方法分别通过精心设计的损失感知补偿 (LAC) 和参数化范围裁剪 (PRC) 来优化前向和后向传递的计算。具体来说,我们构建了一个新的网络组件,即补偿层,以自动抵消张量算法的量化误差。
- 我们在 Octo 中实现了我们的方法,Octo 是一个轻量级的跨平台系统,用于微小的设备学习。对商用 AI 芯片的评估表明,Octo 比最先进的量化训练方法具有更高的训练效率,同时在全精度训练中实现了足够的处理加速和内存减少。它分别通过精心设计的损耗感知补偿 (LAC) 和参数化范围裁剪 (PRC) 来优化前向和后向传递的计算。具体来说,我们构建了一个新的网络组件,即补偿层,以自动抵消张量算法的量化误差。
Fine-tuning giant neural networks on commodity hardware with automatic pipeline model parallelism
Saar Eliad, Ido Hakimi, and Alon De Jagger, Department of Computer Science, Technion - Israel Institute of Technology; Mark Silberstein, Department of Computer Science and Department of Electrical Engineering, Technion - Israel Institute of Technology; Assaf Schuster, Department of Computer Science, Technion - Israel Institute of Technology
- 微调是一种越来越普遍的技术,它利用迁移学习来显着加快大型高质量模型的训练。至关重要的是,微调有可能使在高端超级计算级系统上预先训练的巨型最先进模型可供无法访问如此昂贵资源的用户随时使用。不幸的是,这种潜力仍然难以实现,因为模型通常不适合单个商品 GPU 的内存,这使得微调成为一个具有挑战性的问题。
- 我们提出了 FTPipe,这是一个探索管道模型并行性新维度的系统,使大型神经网络的微调任务的多 GPU 执行易于在商品硬件上访问。一个关键思想是一种新的模型划分和任务分配方法,称为混合管道。混合管道将模型划分为任意计算块而不是层,并在将块分配给 GPU 时放宽模型拓扑约束,允许在同一 GPU 上执行不相邻的块。与之前的工作相比,更灵活的分区可以更好地平衡 GPU 上的计算和内存负载,但不会增加通信开销。此外,也许令人惊讶的是,当应用于异步训练时,
- 我们对巨型最先进的 NLP 模型(BERT-340M、GPT2-1.5B 和 T5-3B)进行的大量实验表明,FTPipe 可实现高达 3 倍的加速和最先进的准确度——调整具有数十亿参数的巨型变压器。这些模型需要 12GB 到 59GB 的 GPU 内存,FTPipe 在 8 个商用 RTX2080-Ti GPU 上执行它们,每个 GPU 具有 11GB 内存和标准 PCIe。
INFaaS: Automated Model-less Inference Serving
Francisco Romero, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis, Stanford University
- 尽管在机器学习推理服务方面已有工作,但易用性和成本效率仍然是大规模的挑战。开发人员必须手动搜索数以千计的模型变体——在硬件、资源占用、延迟、成本和准确性方面不同的已训练模型的版本——以满足不同的应用程序需求。由于需求、查询负载和应用程序本身随着时间的推移而发展,因此需要为每个推理查询动态地做出这些决策,以避免通过简单的自动缩放来避免过多的成本。为了避免在模型变体的庞大而复杂的权衡空间中导航,开发人员经常跨查询修复变体,并在负载增加时复制它。然而,鉴于云中变体和硬件平台的多样性,对权衡空间的缺乏了解可能会给开发人员带来巨大的成本。
- 本文介绍了 INFaaS,一种用于分布式推理服务的自动化无模型系统,开发人员只需为其应用程序指定性能和准确性要求,而无需为每个查询指定特定的模型变体。 INFaaS 从已经训练好的模型中生成模型变体,并代表开发人员有效地导航模型变体的巨大权衡空间以满足特定于应用程序的目标:(a) 对于每个查询,它选择一个模型、硬件架构和模型优化,(b) 它将 VM 级水平自动缩放与模型级自动缩放相结合,其中使用多个不同的模型变体来为每台机器内的查询提供服务。通过利用不同的变体和跨模型共享硬件资源,与最先进的推理相比,INFaaS 的吞吐量提高了 1.3 倍,违反延迟目标的频率降低了 1.6 倍,并节省了高达 21.6 倍的成本(平均 8.5 倍) AWS EC2 上的服务系统。
Jump-Starting Multivariate Time Series Anomaly Detection for Online Service Systems
Minghua Ma, Tsinghua University, BNRist; Shenglin Zhang, Nankai University; Junjie Chen, Tianjin University; Jim Xu, Georgia Tech; Haozhe Li and Yongliang Lin, Nankai University; Xiaohui Nie, Tsinghua University, BNRist; Bo Zhou and Yong Wang, CNCERT/CC; Dan Pei, Tsinghua University, BNRist
- 随着在线服务系统的蓬勃发展,对多变量时间序列的异常检测,如CPU利用率、平均响应时间和每秒请求数的组合,对系统可靠性越来越重要。尽管为此目的设计了一系列基于学习的方法,但我们的实证研究表明,这些方法的初始化时间较长,无法获得足够的训练数据。在本文中,我们将压缩感知技术引入多元时间序列异常检测以实现快速初始化。为了构建快速启动异常检测器,我们提出了一种名为 JumpStarter 的方法。基于特定领域的见解,我们为 JumpStarter 设计了一种基于形状的聚类算法以及一种抗异常值采样算法。使用从两家互联网公司收集的真实世界多元时间序列数据集,我们的结果表明 JumpStarter 的平均 F1 得分为 94.12%,显着优于最先进的异常检测算法,初始化时间更短,仅为 20分钟。我们已将 JumpStarter 应用于在线服务系统,并在实际场景中获得了有用的经验。
Palleon: A Runtime System for Efficient Video Processing toward Dynamic Class Skew
Boyuan Feng, Yuke Wang, Gushu Li, Yuan Xie, and Yufei Ding, University of California, Santa Barbara
- 与人类分类的准确性一样,卷积神经网络 (CNN) 推动了许多视频处理系统在云支持的移动平台(例如手机和机器人)上的部署。然而,这些视频处理系统经常面临来自 CNN 的密集能源消耗和移动平台上有限资源之间的紧张关系。为了解决这种紧张关系,我们建议使用广泛可用但尚未充分探索的运行时输入级信息(即类偏斜)来加速视频处理。通过这种运行时分析的信息,它努力针对时变视频流自动优化 CNN。具体来说,我们构建了 Palleon,这是一个运行时系统,可以根据自动检测到的类偏斜动态适应和选择能耗最低的 CNN 模型,同时仍能达到所需的精度。对最先进的 CNN 和真实世界视频的广泛评估表明,Palleon 能够实现高效的视频处理,节能高达 6.7 倍,延迟减少 7.9 倍。
7. Can I Come In? It’s Raining!: Cloud Computing(我能进来吗? 下雨了!:云计算)
Session Chairs: Adriana Szekeres, VMware Research, and Sanidhya Kashyap, EPFL
FaaSNet: Scalable and Fast Provisioning of Custom Serverless Container Runtimes at Alibaba Cloud Function Compute
Ao Wang, George Mason University; Shuai Chang, Alibaba Group; Huangshi Tian, Hong Kong University of Science and Technology; Hongqi Wang, Haoran Yang, Huiba Li, and Rui Du, Alibaba Group; Yue Cheng, George Mason University
- 无服务器计算或功能即服务 (FaaS) 允许用户部署细粒度功能,同时提供完全托管的资源配置和自动扩展,从而实现了一种构建和扩展应用程序的新方法。自定义 FaaS 容器支持越来越受到关注,因为它可以更好地控制操作系统、版本控制和工具,以实现 FaaS 应用程序的现代化。然而,提供快速容器供应给 FaaS 提供商带来了不小的挑战,因为容器供应成本高昂,而且现实世界的 FaaS 工作负载表现出高度动态的模式。
- 在本文中,我们设计了 FaaSNet,这是一个高度可扩展的中间件系统,用于加速 FaaS 容器配置。 FaaSNet 由全球最大的云提供商之一阿里云函数计算的 FaaS 平台的工作负载和基础设施需求驱动。FaaSNet 通过轻量级、自适应函数树 (FT) 结构实现可扩展的容器供应。 FaaSNet 使用 I/O 高效的按需获取机制来进一步大规模降低配置成本。我们在阿里云函数计算中实现并集成了 FaaSNet。评估结果表明,FaaSNet:(1)在 8.3 秒内在 1,000 台虚拟机上完成 2,500 个功能容器的配置,(2)比阿里云当前的 FaaS 平台和最先进的 P2P 容器注册中心的扩展速度快 13.4 倍和 16.3 倍(Kraken) 和 (3) 分别使用比优化基线少 75.2% 的时间来维持突发工作负载。
Experiences in Managing the Performance and Reliability of a Large-Scale Genomics Cloud Platform
Michael Hao Tong, Robert L. Grossman, and Haryadi S. Gunawi, University of Chicago
- 我们分享了我们在提高基因组数据共享 (GDC)(一个大型癌症基因组学云平台)上长期运行作业的性能方面的技术经验。我们展示了常见的生物信息学工作负载如何在几天后导致 VM 老化,从而导致大量扩展页表 (EPT) 违规,从而显着影响性能。我们介绍了主机和虚拟机级别的 EPT 监控并评估了几种可能的缓解方案。我们强调了这项研究所需的漫长调查过程,实验需要很多天才能完成。
Scaling Large Production Clusters with Partitioned Synchronization
Yihui Feng, Alibaba Group; Zhi Liu, Yunjian Zhao, Tatiana Jin, and Yidi Wu, The Chinese University of Hong Kong; Yang Zhang, Alibaba Group; James Cheng, The Chinese University of Hong Kong; Chao Li and Tao Guan, Alibaba Group
- 近年来,计算机集群的规模显着增长。今天,一个集群可能有 10 万台机器,每天执行数十亿个任务,尤其是短任务。因此,管理集群中资源利用率的调度程序也需要升级以在更大范围内工作。然而,在大型生产集群中升级调度器(一个中央系统组件)是一项艰巨的任务,因为我们需要确保集群的稳定性和健壮性,例如应保证用户透明度,并且其他集群组件和现有调度策略需要维持不变。我们调查了现有的调度程序设计,发现大多数无法处理我们生产集群的规模或可能危及它们的健壮性。我们分析了一种遵循共享状态架构的最合适的设计,它的局限性使我们采用了一种细粒度的陈旧感知状态共享设计,称为分区同步 (ParSync)。ParSync 具有维护生产集群稳健性所需的简单性,同时实现高调度效率和扩展质量。ParSync 已部署并在我们的生产集群中稳定运行。
Fighting the Fog of War: Automated Incident Detection for Cloud Systems
Liqun Li and Xu Zhang, Microsoft Research; Xin Zhao, University of Chinese Academy of Sciences; Hongyu Zhang, The University of Newcastle; Yu Kang, Pu Zhao, Bo Qiao, and Shilin He, Microsoft Research; Pochian Lee, Jeffrey Sun, Feng Gao, and Li Yang, Microsoft Azure; Qingwei Lin, Microsoft Research; Saravanakumar Rajmohan, Microsoft 365; Zhangwei Xu, Microsoft Azure; Dongmei Zhang, Microsoft Research
- 事件和中断会显着降低 AWS、Azure 和 GCP 等大型云计算系统的可用性。在当前的事件响应实践中,每个团队对整个系统只有一个局部视图,这使得事件的检测就像在“战争迷雾”中打仗一样。结果,延长缓解时间并招致更多财务损失。在这项工作中,我们提出了一个自动事件检测系统,即 Warden,作为事件管理 (IcM) 平台的一部分。Warden 收集来自不同服务的警报,并从全局角度检测事件的发生。对于每个检测到的潜在事件,Warden 都会通知相关的值班工程师,以便他们可以正确确定任务的优先级并启动跨团队协作。我们在 Azure 的 IcM 平台中实现并部署了 Warden。我们根据 18 个月内从 26 个主要服务收集的数据得出的评估结果表明,Warden 是有效的,并且优于基准方法。对于大多数成功检测到的事件(~68%),Warden 的速度比人类快,对于需要很长时间手动检测的事件尤其如此。
8. SIT, Fido!: Training Machine Learning Algorithms(坐下,Fido!训练机器学习算法)
Session Chair: Mark Silberstein, Technion—Israel Institute of Technology
Habitat: A Runtime-Based Computational Performance Predictor for Deep Neural Network Training
Geoffrey X. Yu, University of Toronto/Vector Institute; Yubo Gao, University of Toronto; Pavel Golikov and Gennady Pekhimenko, University of Toronto/Vector Institute
- 深度学习研究人员和从业者通常利用 GPU 来帮助更快地训练他们的深度神经网络 (DNN)。然而,选择要使用的 GPU 具有挑战性,因为 (i) 有很多选择,以及 (ii) 用户需要解决竞争问题:最大化计算性能同时最小化成本。在这项工作中,我们提出了一种新的实用技术来帮助用户做出明智且具有成本效益的 GPU 选择:借助用户已有的 GPU 进行性能预测。我们的技术利用观察结果,因为 DNN 训练由重复的计算步骤组成,因此预测单次迭代的执行时间通常足以表征整个训练过程的性能。我们使用 (i) 波缩放,一种基于 GPU 执行模型的技术,或 (ii) 预训练的多层感知器,通过将训练迭代中每个操作的执行时间从一个 GPU 缩放到另一个来进行预测。我们将我们的技术实施到一个名为 Habitat 的 Python 库中,发现它在 ResNet-50、Inception v3、Transformer、GNMT 和 DCGAN 上跨六种不同的 GPU 架构做出准确的迭代执行时间预测(平均误差为 11.8%)。 Habitat 支持 PyTorch,易于使用,并且是开源的。
Zico: Efficient GPU Memory Sharing for Concurrent DNN Training
Gangmuk Lim, UNIST; Jeongseob Ahn, Ajou University; Wencong Xiao, Alibaba Group; Youngjin Kwon, KAIST; Myeongjae Jeon, UNIST
- GPU 是现代服务器基础设施中的主力军,推动了许多计算密集型工作负载的进步,例如深度神经网络 (DNN) 训练。最近的几项工作提出了跨多个并发 DNN 训练作业共享 GPU 资源的解决方案,但没有一个解决方案解决此类作业共置带来的快速增加的内存占用,这极大地限制了共享 GPU 资源的有效性。在本文中,我们介绍了 Zico,这是第一个旨在减少并发训练的系统范围内存消耗的 DNN 系统。Zico 通过监控 GPU 计算进度来跟踪单个训练作业的内存使用模式,并使从作业中回收的内存可全局共享。基于这种内存管理方案,Zico 自动决定在并发作业之间共享内存的策略,以最小的训练延迟,同时不超过给定的内存预算,例如 GPU 内存容量。我们的评估表明,Zico 优于现有的 GPU 共享方法,并在各种工作协同定位场景中带来好处。
Refurbish Your Training Data: Reusing Partially Augmented Samples for Faster Deep Neural Network Training
Gyewon Lee, Seoul National University and FriendliAI; Irene Lee, Georgia Institute of Technology; Hyeonmin Ha, Kyunggeun Lee, and Hwarim Hyun, Seoul National University; Ahnjae Shin and Byung-Gon Chun, Seoul National University and FriendliAI
- 数据增强是一种广泛采用的技术,用于提高深度学习模型的泛化能力。它通过应用随机变换为训练样本提供额外的多样性。虽然它很有用,但数据增强通常会受到大量 CPU 开销的影响,这会降低训练速度。为了解决这个问题,我们提出了数据翻新,这是一种新的样本重用机制,可以在保持模型泛化的同时加速深度神经网络的训练。数据翻新不是将数据增强视为黑盒操作,而是将其拆分为部分增强和最终增强。它重用部分增强的样本以减少 CPU 计算,同时使用最终增强进一步转换它们以保留通过数据增强获得的样本多样性。我们设计并实现了一个新的数据加载系统,Revamper,实现数据的翻新。它通过保持每个训练步骤的 CPU 处理时间不变来最大化 CPU 和深度学习加速器之间的重叠。我们的评估表明,Revamper 可以将计算机视觉模型的训练速度提高 1.03×–2.04 倍,同时保持可比的准确性。
ZeRO-Offload: Democratizing Billion-Scale Model Training
Jie Ren, UC Merced; Samyam Rajbhandari, Reza Yazdani Aminabadi, and Olatunji Ruwase, Microsoft; Shuangyan Yang, UC Merced; Minjia Zhang, Microsoft; Dong Li, UC Merced; Yuxiong He, Microsoft
- 大规模模型训练一直是少数需要复杂模型重构和访问昂贵的 GPU 集群的场所。ZeRO-Offload 通过让几乎所有人都可以使用大型模型训练来改变大型模型训练的格局。它可以在单个 GPU 上训练具有超过 130 亿个参数的模型,与 PyTorch 等流行框架相比,大小增加了 10 倍,并且无需数据科学家更改模型或牺牲计算效率。
- ZeRO-Offload 通过将数据和计算卸载到 CPU 来实现大型模型训练。为了保持计算效率,它旨在最大限度地减少进出 GPU 的数据移动,并减少 CPU 计算时间,同时最大限度地节省 GPU 上的内存。因此,对于 10B 参数模型,ZeRO-Offload 在单个 NVIDIA V100 GPU 上可以实现 40 TFlops/GPU,而对于 1.4B 参数模型,单独使用 PyTorch 可以达到 30TF,这是可以在不耗尽内存的情况下进行训练的最大值。ZeRO-Offload 还旨在在可用时在多个 GPU 上进行扩展,在多达 128 个 GPU 上提供近乎线性的加速。此外,它可以与模型并行一起工作,在单个 DGX-2 机器上训练具有超过 700 亿个参数的模型,与单独使用模型并行相比,模型大小增加了 4.5 倍。通过将计算和内存效率与易用性相结合,ZeRO-Offload 使大规模模型训练民主化,即使数据科学家也可以使用单个 GPU。
9. I Can Smell That Fluffy Was Here: Networks(我能闻到这里有毛茸茸的味道:网络)
Session Chairs: Patrick Stuedi, LinkedIn, and Anuj Kalia, Microsoft
Hashing Linearity Enables Relative Path Control in Data Centers
Zhehui Zhang, University of California, Los Angeles; Haiyang Zheng, Jiayao Hu, Xiangning Yu, Chenchen Qi, Xuemei Shi, and Guohui Wang, Alibaba Group
- 数据中心网络是一个具有丰富路径多样性的环境,其中跨多层交换机的终端主机对之间有大量路径可用。使用 ECMP(等价多路径路由)在这些路径之间分配流量以进行负载平衡和故障处理。尽管 ECMP 在流量极化和路径模糊方面有其局限性,但它仍然是数据中心中最流行的多路径路由机制,因为它是无状态、简单且易于在交换机 ASIC 中实现的。
- 在本文中,我们分析了当今数据中心交换机 ASIC 中使用的 ECMP 哈希算法,旨在提供轻量级路径控制解决方案,可以解决 ECMP 的局限性,而无需对现有数据中心路由和传输协议进行任何更改。与关于 ECMP 散列随机性的普遍看法相反,我们揭示了数据中心广泛部署的交换机 ASIC 中使用的散列算法(例如 XOR 和 CRC)的线性特性。基于散列线性,我们提出了相对路径控制(RePaC),这是一种新的轻量级且易于部署的路径控制机制,可以执行具有确定性路径偏移的按需流迁移。
Live in the Express Lane
Patrick Jahnke, TU Darmstadt and SAP; Vincent Riesop, SAP; Pierre-Louis Roman and Pavel Chuprikov, Università della Svizzera italiana; Patrick Eugster, Università della Svizzera italiana, TU Darmstadt, and Purdue University
- 我们介绍了 Express-Lane (X-Lane),这是一种用于减轻数据中心基础设施干扰以提高协调服务活跃度的新型系统。X-Lane从头开始遵循新颖的设计,以实现单位数微秒范围内的超低延迟和纳秒范围内的抖动的交互,而其余交互则照常处理。为了展示 X-Lane 的适用性和通用性,我们在 SAP SE 生产环境中的商品硬件上实施和评估了两项服务:检测时间低于 10 μs 的故障检测器 (X-FD) 和 Raft 实现 (X-Raft)延迟低于 20 μs。我们通过用 X-Raft 替换 Redis 的复制协议,进一步展示了 X-Lane 服务的平滑可集成性,
Understanding Precision Time Protocol in Today’s Wi-Fi Networks: A Measurement Study
Paizhuo Chen and Zhice Yang, ShanghaiTech University
- 涉及分布式控制和传感的新兴移动应用需要通过无线链路实现准确的时间同步。本文系统地研究了精确时间协议(PTP)在当今 Wi-Fi 网络中的性能。我们研究了软件和硬件 PTP 实现。我们的研究揭示了软件 PTP 同步错误的根本原因。我们表明,通过微调系统配置和在线校准程序,软件 PTP 可以使用现成的 Wi-Fi 设备实现合理的精度。硬件 PTP 需要 Wi-Fi NIC 中不包含的 PTP 硬件时间戳时钟。我们提出了一种利用硬件 TSF 计数器来模拟 PTP 时钟的方法。
AUTO: Adaptive Congestion Control Based on Multi-Objective Reinforcement Learning for the Satellite-Ground Integrated Network
Xu Li, Feilong Tang, and Jiacheng Liu, Shanghai Jiao Tong University; Laurence T. Yang, St. Francis Xavier University; Luoyi Fu and Long Chen, Shanghai Jiao Tong University
- 星地一体化网络高度异构,应用多样化。它需要拥塞控制(CC)来在长时延卫星网络和大带宽地面网络中实现一致的高性能,并应对不同的应用需求。然而,现有的方案很难实现这些目标,因为它们不能自适应地平衡CC的目标(即吞吐量、延迟)并且不是目标可配置的。为了解决这些限制,我们提出并实施了一种基于多目标强化学习 (MORL) 的新型自适应 CC 方案,名为 AUTO。这是环境适应性通过训练 MORL 代理和偏好适应模型。第一个可以为所有可能的偏好(即目标的相对重要性)生成最佳策略。后者通过将状态序列作为输入来识别环境,自动为每个环境选择合适的偏好。同时,AUTO可以通过让应用随意决定输入偏好来满足多样化的应用需求。对模拟网络和真实互联网的评估表明,AUTO 在代表性网络环境中始终优于最先进的技术,并且对随机数据包丢失和快速网络变化具有更强的鲁棒性。此外,AUTO 可以实现对不同 CC 方案的公平性。
Hey, Lumi! Using Natural Language for Intent-Based Network Management
Arthur S. Jacobs, Ricardo J. Pfitscher, and Rafael H. Ribeiro, Federal University of Rio Grande do Sul (UFRGS); Ronaldo A. Ferreira, UFMS; Lisandro Z. Granville, Federal University of Rio Grande do Sul (UFRGS); Walter Willinger, NIKSUN, Inc.; Sanjay G. Rao, Purdue University
- 在这项工作中,我们问:例如,校园网络运营商使用自然语言告诉网络“检查宿舍流量”需要什么?网络如何立即正确地将请求转换为低级配置命令并将它们部署在网络中以完成它“要求”做的工作?我们通过展示 Lumi 的设计和实现来回答这些问题,这是一个新系统,它 (i) 允许操作员用自然语言表达意图,(ii) 使用机器学习和操作员反馈来确保翻译的意图符合操作员的目标, (iii) 在网络中正确编译和部署它们。作为 Lumi 的一部分,我们依赖于自然语言意图和称为 Nile(网络意图语言)的网络配置命令之间的抽象层。我们使用合成和真实的校园网络策略评估 Lumi,并表明 Lumi 可以高精度提取实体并在几毫秒内编译意图。我们还报告了一项用户研究,其中 88.5% 的参与者表示他们更愿意单独使用 Lumi 或与配置命令结合使用。
10. I Buried That Bone Here Somewhere: Storage(我把那根骨头埋在这里某处:存储)
Session Chairs: Avani Wildani, Emory University, and Changwoo Min, Virginia Tech
Boosting Full-Node Repair in Erasure-Coded Storage
Shiyao Lin, Guowen Gong, and Zhirong Shen, Xiamen University; Patrick P. C. Lee, The Chinese University of Hong Kong; Jiwu Shu, Xiamen University and Tsinghua University
- 作为当今存储系统中容错的常见选择,纠删码仍然受到修复中引入的大量流量的阻碍。近年来设计了多种纠删码和修复算法来缓解修复流量,但我们通过仔细分析发现它们仍然受到一些限制的困扰,这些限制限制甚至否定了性能提升。我们提出了 RepairBoost,这是一个调度框架,可以辅助现有的线性纠删码和修复算法来提升全节点修复性能。RepairBoost 建立在三个设计原语之上:(i) 修复抽象,它采用有向无环图来表征单块修复过程;(ii) 修复流量平衡,即同时平衡上传和下载修复流量;(iii) 传输调度,它小心地分派所请求的数据块以使最空闲的带宽饱和。在 Amazon EC2 上的大量实验表明,RepairBoost 可以将各种纠删码和修复算法的修复速度提高 35.0-97.1%。
KVIMR: Key-Value Store Aware Data Management Middleware for Interlaced Magnetic Recording Based Hard Disk Drive
Yuhong Liang, Tsun-Yu Yang, and Ming-Chang Yang, The Chinese University of Hong Kong
- 基于日志结构合并树 (LSM-tree) 的键值 (KV) 存储在硬盘驱动器 (HDD) 上提供具有高吞吐量的写入密集型应用程序。最近,新兴的隔行磁记录 (IMR) 技术使基于 IMR 的 HDD 由于其高面密度而成为构建具有成本效益的 KV 存储的另一个理想选择。尽管如此,我们观察到在基于 IMR 的 HDD 上部署基于 LSM 树的 KV 存储可能会显着降低传入读/写的吞吐量。因此,本文介绍了 KVIMR,这是一种数据管理,用于在基于 IMR 的 HDD 上构建具有成本效益且高吞吐量的基于 LSM 树的 KV 存储。 KVIMR 被构建为中间件,介于基于 LSM 树的 KV 存储和基于 IMR 的 HDD 之间,以通过有限的修改来兼容主流的基于 LSM 树的 KV 存储实现。从技术上讲,KVIMR 采用了一种新颖的 Compaction-aware Track Allocation 方案,它利用了 Compaction 过程背后的特殊属性来弥补吞吐量下降的问题。 KVIMR 进一步利用一种新颖的合并 RMW 方法来提高将 KV 存储的多轨道大小的文件持久保存到 IMR 轨道的效率,并确保崩溃一致性。我们对几个著名的基于 LSM-tree 的 KV 存储实现的评估表明,KVIMR 不仅在写入密集型工作负载下将整体吞吐量提高了 1.55 倍,而且在 HDD 的高空间使用率下甚至实现了 2.17 倍的吞吐量。最先进的 IMR 轨道分配方案。
Differentiated Key-Value Storage Management for Balanced I/O Performance
Yongkun Li and Zhen Liu, University of Science and Technology of China; Patrick P. C. Lee, The Chinese University of Hong Kong; Jiayu Wu, University of Science and Technology of China; Yinlong Xu, Anhui Province Key Laboratory of High Performance Computing, University of Science and Technology of China; Yi Wu, Liu Tang, Qi Liu, and Qiu Cui, PingCAP
- 现代键值 (KV) 存储采用 LSM 树作为管理 KV 对的核心数据结构,但存在高写入和读取放大的问题。现有的 LSM 树优化通常会进行设计权衡,无法同时实现写入、读取和扫描的高性能。为了解决设计紧张,我们提出了 DiffKV,它建立在 KV 分离的基础上,以仔细管理键和值的排序。DiffKV 使用具有完全排序顺序的传统 LSM 树(在 LSM 树的每个级别内)来管理键,同时以协调的方式根据键的完全排序顺序使用部分排序来管理值,以保持高扫描性能。我们进一步提出了细粒度的 KV 分离,以按大小区分 KV 对,从而在混合工作负载下实现平衡的性能。
ZNS: Avoiding the Block Interface Tax for Flash-based SSDs
Matias Bjørling, Western Digital; Abutalib Aghayev, The Pennsylvania State University; Hans Holmberg, Aravind Ramesh, and Damien Le Moal, Western Digital; Gregory R. Ganger and George Amvrosiadis, Carnegie Mellon University
- 分区命名空间 (ZNS) 接口代表了主机软件和基于闪存的 SSD 之间的新功能划分。当前基于闪存的 SSD 保持了几十年前的块接口,这在容量过度配置、用于页面映射表的 DRAM、垃圾收集开销以及试图减轻垃圾收集的主机软件复杂性方面付出了巨大的代价。 ZNS 为这种不断上升的块接口税提供了庇护。
- 本文介绍了 ZNS 接口并解释了它如何影响 SSD 硬件/固件和主机软件。通过公开闪存擦除块边界和写入顺序规则,ZNS 接口要求主机软件解决这些问题,同时继续管理 SSD 内的介质可靠性。我们描述了存储软件如何专门用于 ZNS 接口的语义,通常会带来显着的效率优势。我们展示了启用对 ZNS SSD 的支持所需的工作,并展示了 f2fs 和 RocksDB 的修改版本如何利用 ZNS SSD 实现与在具有相同物理硬件的块接口 SSD 上运行相比更高的吞吐量和更低的尾部延迟。例如,我们发现与块接口 SSD 相比,我们的区域专用 RocksDB 的 99.9% 随机读取延迟在 ZNS SSD 上至少低 2-4 倍,写入吞吐量高 2 倍。
MapperX: Adaptive Metadata Maintenance for Fast Crash Recovery of DM-Cache Based Hybrid Storage Devices
Lujia Yin, NUDT; Li Wang, Didi Chuxing; Yiming Zhang, NiceX Lab, NUDT; Yuxing Peng, NUDT
- DM-cache 是 Linux 内核设备映射器的一个组件,已被广泛用于将 SSD 和 HDD 映射到更高级别的虚拟块设备上,这些虚拟块设备将快速 SSD 作为慢速 HDD 的缓存,以实现高 I/O 性能。货币成本。在享受持久缓存的好处(其中 SSD 可以加速正常 I/O 而不必担心数据丢失)的同时,DM 缓存的当前设计受到崩溃恢复时间长(以小时为单位)和低可用性的困扰。这是因为它的脏位元数据必须异步持久化以提高性能,从而导致 SSD 上的所有缓存数据都被假定为脏数据并在系统重新启动后恢复。
- 本文介绍了 MapperX,这是 DM-cache 的一种新颖扩展,它使用磁盘上的自适应位树 (ABT) 以分层方式同步维护脏位的元数据。利用块写入的空间局部性,MapperX 通过在 ABT 中自适应地添加/删除叶子来实现受控元数据持久性开销和快速崩溃恢复,其中不同级别代表不同粒度的缓存块的状态。我们已经为 Linux DM-cache 模块实现了 MapperX。实验结果表明,基于 MapperX 的混合存储设备在崩溃恢复时间上优于原始基于 DM-cache 的混合设备几个数量级,同时仅引入可忽略不计的元数据持久性开销。
11. My Tail Never Has Any Latency: OS & Hardware(我的尾巴从来没有任何延迟:操作系统和硬件)
Session Chairs: Michio Honda and Antonio Barbalace, University of Edinburgh
Exploring the Design Space of Page Management for Multi-Tiered Memory Systems
Jonghyeon Kim, Wonkyo Choe, and Jeongseob Ahn, Ajou University
- 随着包含各种类型内存(例如 DRAM 和 SCM)的分层内存系统的出现,操作系统对内存管理的支持变得越来越重要。但是,操作系统当前管理页面的方式是在假设所有内存都具有基于 DRAM 的相同功能的情况下设计的。这种过度简化会导致分层内存系统中的内存使用不理想。本研究对当前 Linux 设计中的页面管理方案进行了深入分析,扩展 NUMA 以支持配备 DRAM 和 SCM(英特尔的 DCPMM)的系统。在这种多层内存系统中,我们发现影响性能的关键因素不仅是访问局部性,还有内存的访问层。在考虑这两个特征时,页面放置有多种替代方案。然而,当前的操作系统只优先考虑访问局部性。本文探讨了称为 AutoTiering 的页面管理方案的设计空间,以有效地使用多层内存系统。我们的评估结果表明,与股票 Linux 内核相比,我们提出的技术可以通过释放多层内存层次结构的潜力显着提高各种工作负载的性能。
A Fast and Flexible Hardware-based Virtualization Mechanism for Computational Storage Devices
Dongup Kwon, Dongryeong Kim, Junehyuk Boo, Wonsik Lee, and Jangwoo Kim, Seoul National University
- 在其存储单元内部或附近并入计算单元的计算存储设备是一种非常有前途的技术,可以最大限度地提高存储服务器的性能。然而,要应用此类计算存储设备并在虚拟化环境中充分发挥其潜力,服务器架构师必须解决一个基本挑战:经济高效的虚拟化。这个关键挑战可以通过以下问题直接解决:(1)如何虚拟化两个不同的硬件单元(即计算和存储)和(2)如何集成它们以构建虚拟计算存储设备,以及(3)如何将它们提供给用户。然而,由于缺乏硬件辅助的虚拟化支持,现有的计算存储虚拟化方法严重受到其低性能和高成本的影响。
- 在这项工作中,我们提出了 FCSV-Engine,这是一种 FPGA 卡,旨在最大限度地提高计算存储虚拟化的性能和成本效益。FCSV-Engine 介绍了实现设计目标的三个关键思想。首先,它通过将硬件辅助虚拟化应用于计算和存储单元来实现高虚拟化性能。其次,它通过为虚拟化单元应用硬件辅助资源编排来进一步提高性能。第三,通过动态构建和调度虚拟计算存储设备,实现了高性价比。据我们所知,这是为现代计算存储设备实现硬件辅助虚拟化机制的第一项工作。
Fair Scheduling for AVX2 and AVX-512 Workloads
Mathias Gottschlag, Philipp Machauer, Yussuf Khalil, and Frank Bellosa, Karlsruhe Institute of Technology
- CPU 调度程序(例如 Linux Completely Fair Scheduler)尝试通过分配相等的 CPU 时间作为提高单个任务的服务质量的技术,将相等份额的 CPU 性能分配给具有相同优先级的任务。然而,最近,CPU 的功率受到限制,指令集的不同子集根据指令的复杂性允许不同的操作频率。特别是,支持 AVX2 和 AVX-512 指令的 Intel CPU 在使用这些 256 位和 512 位 SIMD 指令时通常会降低其频率,以防止过度耗电。这种频率降低通常会影响其他功耗较低的进程,在这种情况下,CPU 时间的平均分配会导致性能不均,并且严重缺乏性能隔离。
- 我们描述了对现有调度程序的修改,以恢复涉及执行复杂耗电指令的任务的工作负载的公平性。特别是,我们提出了一种识别负责降低频率的 AVX2/AVX-512 任务的技术,并且我们修改了 CPU 时间计算以增加被这些 AVX2/AVX-512 任务减慢的其他任务的优先级。虽然之前与 AVX-512 应用程序并行运行的非 AVX 应用程序平均速度降低了 24.9%,但我们的原型将此类场景中非 AVX 任务和 AVX-512 任务之间的性能差异降低到平均 5.4%,具有涉及 AVX2 应用程序的工作负载的类似改进。
SKQ: Event Scheduling for Optimizing Tail Latency in a Traditional OS Kernel
Siyao Zhao, Haoyu Gu, and Ali José Mashtizadeh, University of Waterloo
- 本文介绍了可调度 Kqueue (SKQ),这是 FreeBSD Kqueue 的一种新设计,可改善应用程序尾部延迟和低延迟吞吐量。SQQ 引入了新的可扩展架构和事件调度。我们提供多种调度策略,以提高缓存局部性并减少工作负载不平衡。SQQ 还使应用程序能够优先处理对延迟敏感的请求,而不是常规请求。
- 在 RocksDB 基准测试中,SKQ 将尾延迟降低了 1022 倍,并将低延迟吞吐量扩展了 27.4 倍。对于不平衡的工作负载,SKQ 还将传统操作系统内核网络与最先进的内核绕过网络系统之间的差距缩小了 83.7%。
A Linux Kernel Implementation of the Homa Transport Protocol
John Ousterhout, Stanford University
- Homa/Linux 是实现 Homa 传输协议的 Linux 内核模块。与 TCP 和 DCTCP 相比,Homa/Linux 的测量再次证实了 Homa 的卓越性能。在具有 40 个节点的集群基准测试中,Homa/Linux 为所有消息大小提供了比 TCP 和 DCTCP 更低的延迟;对于短消息,Homa 的 99% 尾部延迟比 TCP 和 DCTCP 低 7-83 倍。基准测试还表明,Homa 已经消除了网络拥塞作为一个重要的性能限制。尾部延迟和吞吐量现在都受到软件开销的限制,特别是由跨内核的协议栈的不完美负载平衡引起的软件拥塞。如果将来可以消除软件开销,则可以实现 5-10 倍的性能提升。
12. Friends Fur-Ever: Persistent Memory and In-Memory Computing(朋友Fur-Ever:持久性内存和内存计算)
Session Chairs: Changwoo Min, Virginia Tech, and Yu Hua, Huazhong University of Science and Technology
Ayudante: A Deep Reinforcement Learning Approach to Assist Persistent Memory Programming
Hanxian Huang, Zixuan Wang, Juno Kim, Steven Swanson, and Jishen Zhao, University of California, San Diego
- 非易失性随机存取存储器 (NVRAM) 被设想为未来服务器系统中的新存储器层。它们启用了一种有前途的持久内存 (PM) 技术,具有与 DRAM 相当的性能和存储的持久性属性。然而,编程 PM 会在编写代码以采用新的 PM 感知库和 API 方面强加了大量的劳动。此外,非专家 PM 代码可能容易出错。为了减轻 PM 程序员的负担,我们提出了 Ayudante,这是一种基于深度强化学习 (RL) 的 PM 编程助手框架,由两个关键组件组成:基于深度 RL 的 PM 代码生成器和代码精炼管道。给定一段为传统易失性存储器系统开发的 C、C++ 或 Java 源代码,我们的代码生成器会自动生成相应的 PM 代码并检查其数据持久性。代码细化管道解析生成的代码,为进一步的程序测试和性能优化提供报告。我们对配备 Optane DC PM 的英特尔服务器的评估表明,微基准测试程序和 Ayudante 生成的键值存储应用程序都通过了 PMDK 检查器。微基准测试的性能评估表明,生成的代码实现了与 PMDK 代码示例相当的加速和内存访问性能。
TIPS: Making Volatile Index Structures Persistent with DRAM-NVMM Tiering
R. Madhava Krishnan, Wook-Hee Kim, Xinwei Fu, and Sumit Kumar Monga, Virginia Tech; Hee Won Lee, Samsung Electronics; Minsung Jang, Peraton Labs; Ajit Mathew and Changwoo Min, Virginia Tech
- 我们提出了 TIPS—一个系统地使易失性索引持久化的框架。 TIPS 既不限制并发模型,也不要求深入了解 volatile 索引。 TIPS 依靠新颖的 DRAM-NVMM 分层来支持索引不可知转换、持久线性化及其称为分层并发的并发模型,以实现良好的性能和可扩展性。 TIPS 提出了一种称为 UNO 日志记录的混合低开销日志记录技术,以保证崩溃一致性并处理崩溃期间的持久内存泄漏。我们使用 TIPS 转换了具有不同并发模型的 7 个易失性索引和 Redis 键值存储应用程序,并使用 YCSB 对其进行了评估。我们的评估表明,启用 TIPS 的索引优于最先进的索引转换技术 PRONTO、NVTraverse、RECIPE 以及 NVMM 优化的 B+Tree(BzTree、FastFair)、Hash(CCEH 和 Level Hash)和 Trie( WOART) 索引 3-10 倍,同时支持强一致性和索引不可知转换。
Improving Performance of Flash Based Key-Value Stores Using Storage Class Memory as a Volatile Memory Extension
Hiwot Tadese Kassa, University of Michigan; Jason Akers, Mrinmoy Ghosh, and Zhichao Cao, Facebook Inc.; Vaibhav Gogte and Ronald Dreslinski, University of Michigan
- 数据中心中基于闪存的高性能键值存储利用大量 DRAM 来缓存热数据。然而,受 DRAM 高成本和高功耗的推动,具有较低 DRAM 每计算比率的服务器设计正变得流行。这些低成本服务器通过降低服务器工作负载密度来实现横向扩展服务。这会提高整体服务的可靠性,从而降低可扩展工作负载的总拥有成本 (TCO)。然而,对于具有大内存占用的键值存储,由于 IO 利用率和数据访问延迟的增加,这些减少的 DRAM 服务器会降低性能。在这种情况下,提高分片数据库性能的标准做法是减少每台机器的分片数量,这会降低降低 DRAM 低成本服务器的 TCO 优势。
- 在本文中,我们在 AppDirect 模式下使用英特尔®傲腾™PMem 100 系列 SCM (DCPMM) 来扩展 RocksDB(Facebook 最大的键值存储之一)的可用内存。我们首先在 RocksDB 中设计了混合缓存以分层利用 DRAM 和 SCM。然后我们描述了混合缓存在 Facebook 的三个最大的 RocksDB 用例(WhatsApp、Tectonic Metadata 和 Laser)中的性能。我们的结果表明,与现有的小型 DRAM 单插槽平台相比,我们可以实现高达 80% 的吞吐量改进和 20% 的 P95 延迟改进,同时与大型 DRAM 双插槽平台相比保持 43-48% 的成本改进。据我们所知,这是对商业数据中心 DCPMM 平台的首次研究。
First Responder: Persistent Memory Simultaneously as High Performance Buffer Cache and Storage
Hyunsub Song, Shean Kim, J. Hyun Kim, Ethan JH Park, and Sam H. Noh, UNIST
- 持久内存(PM)是一种具有良好特性的新介质,可以极大地提高存储 I/O 性能。虽然已经开发了新的基于 PM 的文件系统来利用 PM,但在将 PM 介质与传统存储介质(如 SSD 和 HDD)完全集成方面,大多数工作都没有成功。我们提出了 First Responder (FR),这是一种利用 PM 有益功能的方法,同时利用现代和成熟的文件系统,例如为传统存储设备开发的 Ext4。从概念上讲,FR 很像缓冲区缓存,但涉及的内容更多,例如在故障情况下保持一致性和提供轻量级管理开销。FR 带来多重好处。首先,我们保留了现有文件系统的成熟度,允许在部署传统文件系统的环境中部署 FR。第二,可以使用这些文件系统支持的传统存储设备,从而轻松将 PM 与传统存储集成。最后,FR 允许以接近 PM 设备延迟的顺序文件系统语义。通过英特尔 DC PMM 的实验评估,我们表明当以缓存形式使用时,FR 的性能可以超过 Ext4 9 倍以上,同时提供持久的有序文件系统语义,而 Ext4 则不能。我们还表明,当用作典型文件系统的一部分时,性能与 NOVA 和 Ext4-DAX 相当。同时提供持久的有序文件系统语义,而 Ext4 则不能。我们还表明,当用作典型文件系统的一部分时,性能与 NOVA 和 Ext4-DAX 相当。同时提供持久的有序文件系统语义,而 Ext4 则不能。我们还表明,当用作典型文件系统的一部分时,性能与 NOVA 和 Ext4-DAX 相当。
A Case Study of Processing-in-Memory in off-the-Shelf Systems
Joel Nider, Craig Mustard, Andrada Zoltan, John Ramsden, Larry Liu, Jacob Grossbard, and Mohammad Dashti, University of British Columbia; Romaric Jodin, Alexandre Ghiti, and Jordi Chauzi, UPMEM SAS; Alexandra Fedorova, University of British Columbia
- 我们评估了来自 UPMEM 的新的内存处理 (PIM) 架构,该架构在现成的服务器中构建和部署。几十年来,人们一直在提出旨在在内存中或内存附近执行计算的系统,以克服众所周知的内存墙,但大多数系统从未通过蓝图或模拟。当硬件实际构建并集成到一个功能齐全的系统中时,它必须解决在模拟中可能被忽略的现实约束。评估一个真正的实施可以揭示有价值的见解。我们在五个常用应用程序上的实验突出了这种架构的主要优势:计算能力和内存带宽随内存大小的变化。此属性有助于某些应用程序克服冯诺依曼瓶颈,而对于其他应用程序,架构限制阻碍了实现硬件潜力。我们的分析解释了原因。
13. Time to File the Claws: Files(是时候归档爪子了:文件)
Session Chairs: Sanidhya Kashyap, EPFL, and Youjip Won, Korea Advanced Institute of Science and Technology (KAIST)
XFUSE: An Infrastructure for Running Filesystem Services in User Space
Qianbo Huai, Windsor Hsu, Jiwei Lu, Hao Liang, Haobo Xu, and Wei Chen, Alibaba Group
- 在用户空间中实现文件系统降低了开发复杂性并减少了对底层操作系统平台的依赖。然而,在用户级别而不是在操作系统内核内部实现文件系统,传统上意味着较低的性能。这种性能开销越来越受到基于新持久内存技术(例如 3D XPoint)和高级网络技术(例如 RDMA)的高性能存储设备的限制。用户空间文件系统也与较差的可靠性、可用性和可服务性 (RAS) 特性相关联。因此,有一种趋势是将用户空间文件系统视为原型和概念验证。在本文中,我们系统地分析了部署用户空间文件系统以提供生产文件存储服务的问题。我们介绍 XFUSE,用户空间框架中的文件系统,解决性能和 RAS 问题,并使文件存储服务能够在用户级别有效部署。我们的性能分析表明,XFUSE 能够在用户级别处理通过标准内核接口发出的文件系统请求,延迟在 4 微秒范围内,并提供超过 8 GB/s 的吞吐量。
Max: A Multicore-Accelerated File System for Flash Storage
Xiaojian Liao, Youyou Lu, Erci Xu, and Jiwu Shu, Department of Computer Science and Technology, Tsinghua University, and Beijing National Research Center for Information Science and Technology (BNRist)
- 近年来,闪存的带宽一直在激增。采用多核充分释放其丰富的带宽成为构建高性能存储系统的必要步骤。本文介绍了 Max 的设计和实现,Max 是一种用于闪存存储的多核友好日志结构文件系统 (LFS)。Max通过三种主要技术,在保留闪存友好设计的同时,系统地提高了LFS的可扩展性。首先,我们提出了一个新的读写信号量来扩展用户 I/O,对 LFS 的内部操作的影响可以忽略不计。其次,我们引入文件单元来扩展对内存索引和缓存的访问,同时提供对并发和闪存友好的磁盘布局。第三,为了充分利用闪存并行性,我们推进了具有运行时独立日志分区的单日志设计,并将排序和一致性保证延迟到崩溃恢复。我们在 Linux 内核中基于 F2FS 实现 Max。评估表明,Max 显着提高了可扩展性,并实现了比现有 Linux 文件系统高一个数量级的吞吐量。
Z-Journal: Scalable Per-Core Journaling
Jongseok Kim and Cassiano Campes, Sungkyunkwan University; Joo-Young Hwang, Samsung Electronics Co., Ltd.; Jinkyu Jeong and Euiseong Seo, Sungkyunkwan University
- 文件系统日志严重限制了文件系统的可扩展性,因为来自多个内核的所有同时写入操作都必须序列化才能写入日志区域。尽管已经提出了一些可扩展的日志方法,但它们需要彻底重新设计文件系统,或者只解决了部分可扩展性瓶颈。每核心日志,其中一个核心有自己的日志堆栈,可以清楚地提供可扩展性。但是,它需要日志一致性机制,因为两个或多个内核可以写入共享文件系统块,因此必须跨多个日志保留共享块上的写入顺序。在本文中,我们提出了一种新颖的可扩展的 per-core 期刊设计。提议的设计允许一个核心独立于其他核心。共享区块中涉及的日志交易通过保序交易链链接在一起,形成交易顺序图。稍后将在检查点过程中施加排序约束。由于提议的设计是独立于日志层的,不依赖于文件系统,因此其实现 Z-journal 可以轻松替换通用日志层 JBD2。我们对在 80 核服务器中的 ext4 文件系统上运行的 FxMark、SysBench 和 Filebench 进行的评估表明,它的性能比当前的 JBD2 高出大约 10 倍。
LODIC: Logical Distributed Counting for Scalable File Access
Jeoungahn Park, KAIST; Taeho Hwang, Hanyang University; Jongmoo Choi, Dankook University; Changwoo Min, Virginia Tech; Youjip Won, KAIST
- 我们开发了一种内存高效的多核可扩展分布式引用计数器,用于可扩展文件访问,逻辑分布式计数 (LODIC)。在逻辑分布式计数中,我们建议在每个进程的基础上分配本地计数器。我们以进程为中心的计数器设计使内核免受现有基于每核的分布式计数方案中过多的内存压力和计数器查询延迟问题的影响。逻辑分布式计数旨在动态地结合引用计数的三个特征:i) 对象的数量,ii) 引用的简洁性,以及 iii) 共享程度。逻辑分布式计数的关键成分是内存映射、计数器嵌入和基于进程空间的反向映射。通过将文件区域映射到进程地址空间,LODIC 可以在进程地址空间分配本地计数器。通过计数器嵌入,逻辑分布式计数定义了本地计数器,而不会对现有内核代码进行重大更改,并且不会为本地计数器引入大量内存开销。利用现有Linux内核的虚拟内存段分配算法,基于进程空间的反向映射定位物理页的本地计数器,无需大量开销。在读取共享文件块时,逻辑分布式计数将吞吐量提高了 65 倍于普通 Linux。当部署在 RocksDB(键值存储)和 NGINX(网络服务器)应用程序中时,LODIC 表现出与理想的可扩展参考计数器一样好的性能。
14. But You Played with Me Yesterday: Serverless Computing and Consistency(但你昨天跟我玩了:无服务器计算和一致性)
Session Chairs: Larry Rudolph, Two Sigma, and Keval Vora, Simon Fraser University
UniStore: A fault-tolerant marriage of causal and strong consistency
Manuel Bravo, Alexey Gotsman, and Borja de Régil, IMDEA Software Institute; Hengfeng Wei, Nanjing University
- 现代在线服务依赖于跨地理分布的数据中心复制其数据的数据存储。在此类数据存储中提供强一致性会导致高延迟并使系统容易受到网络分区的影响。放松一致性的替代方案违反了关键的正确性属性。妥协是允许多个一致性级别在数据存储中共存。在本文中,我们介绍了 UniStore,这是第一个结合了因果一致性和强一致性的容错和可扩展数据存储。我们在 UniStore 中解决的主要挑战是在数据中心发生故障时保持活跃度:如果强事务依赖于后来因故障而丢失的因果事务,这可能会受到损害。UniStore 确保不会出现此类情况,同时仅在必要时为因果交易支付持久性成本。我们使用微基准测试和真实的 RUBiS 基准测试评估 Amazon EC2 上的 UniStore。我们的结果表明 UniStore 有效且可扩展地结合了因果一致性和强一致性。
Optimistic Concurrency Control for Real-world Go Programs
Zhizhou Zhang, University of California, Santa Barbara; Milind Chabbi and Adam Welc, Uber Technologies; Timothy Sherwood, University of California, Santa Barbara
- 我们提出了一个源到源转换框架 Gocc,它使用 Go 语言中基于锁的悲观并发程序,并将它们转换为使用硬件事务内存 (HTM) 的乐观并发程序。选择 Go 语言的动机是并发是 Go 中的一等公民,并且它在 Go 程序中被广泛使用。Gocc 执行丰富的过程间程序分析来检测和过滤锁保护区域,并在有利可图时对周围的锁执行 AST 级代码转换。盈利能力由关键部分的静态分析和通过执行配置文件的动态分析驱动。使用感知器的自定义 HTM 库学习并发行为并动态决定是否在重写的锁定/解锁点中使用 HTM。鉴于事务内存研究的丰富历史,但它在任何工业环境中都缺乏采用,我们相信这种最终产生源代码补丁的工作流程更适合行业规模的采用。广泛采用的 Go 库和应用程序的结果表明,我们的自动化转换带来了显着(高达 10 倍)和可扩展的性能提升,同时避免了重大的性能回归。
Faastlane: Accelerating Function-as-a-Service Workflows
Swaroop Kotni, Ajay Nayak, Vinod Ganapathy, and Arkaprava Basu, Indian Institute of Science
- 在 FaaS 工作流中,一组函数通过在它们之间交互和交换数据来实现应用程序逻辑。当代 FaaS 平台在单独的容器中执行工作流的每个功能。当工作流中的功能交互时,由此产生的延迟会减慢执行速度。
- Faastlane 通过努力将工作流的功能作为容器实例的单个进程中的线程来执行,从而最大限度地减少了功能交互延迟,从而通过简单的加载/存储指令简化了数据共享。对于处理敏感数据的 FaaS 工作流,Faastlane 使用英特尔内存保护密钥 (MPK) 提供轻量级线程级隔离域。虽然线程可以简化共享,但 Python 和 Node.js(广泛用于 FaaS 应用程序)等语言的实现不允许线程的并发执行。Faastlane 动态识别 FaaS 工作流和 fork 进程(而不是线程)中的并行机会,或产生新的容器实例以并发执行工作流的并行功能。我们在 Apache OpenWhisk 上实现了 Faastlane,并表明与 OpenWhisk 相比,它可以将工作流实例加速多达 15 倍,并将函数交互延迟减少多达 99.95%。
SONIC: Application-aware Data Passing for Chained Serverless Applications
Ashraf Mahgoub, Purdue University; Karthick Shankar, Carnegie Mellon University; Subrata Mitra, Adobe Research; Ana Klimovic, ETH Zurich; Somali Chaterji and Saurabh Bagchi, Purdue University
- 数据分析应用程序越来越多地利用无服务器执行环境来实现其易用性和即用即付计费。此类应用程序的结构通常由链接在一起以形成工作流的多个功能组成。当前在函数之间交换中间(临时)数据的方法是通过远程存储(例如 S3),这会带来显着的性能开销。我们比较了三种数据传递方法,我们称之为 VM-Storage、Direct-Passing 和 State-of-practice Remote-Storage。至关重要的是,我们表明没有一种数据传递方法在所有场景下都占优势,最佳选择取决于动态因素,例如输入数据的大小、中间数据的大小、应用程序的并行度和网络带宽。我们提出了 SONIC,这是一种数据传递管理器,可通过为无服务器工作流 DAG 的每个边缘透明地选择最佳数据传递方法并实现通信感知功能放置来优化应用程序性能和成本。 SONIC 监控应用程序参数并使用简单的回归模型来相应地调整其混合数据传递。我们将 SONIC 与 Open-Lambda 集成,并使用在无服务器环境中流行的三个分析应用程序评估 Amazon EC2 上的系统。与四个基线相比,SONIC 在不同条件下提供更低的延迟(原始性能)和更高的性能/美元:SAND、vanilla OpenLambda、OpenLambda with Pocket 和 AWS Lambda。
三. osdi 2021
OSDI 2021是改为annual后的第一届会议,因为时间的仓促和与其他会议投稿时间的冲突,今年OSDI应该算是一个小年,投稿数量和社区关注度都打了一个折扣,投稿163篇,录用31篇
1. Optimizations and Scheduling for Machine Learning(机器学习的优化和调度)
Session Chairs: Gennady Pekhimenko, University of Toronto / Vector Institute, and Shivaram Venkataraman, University of Wisconsin—Madison
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aurick Qiao, Petuum, Inc.; School of Computer Science, Carnegie Mellon University; Sang Keun Choe and Suhas Jayaram Subramanya, Carnegie Mellon University; Willie Neiswanger, Petuum, Inc. and Carnegie Mellon University; Qirong Ho, Petuum, Inc.; Hao Zhang, Petuum, Inc. and UC Berkeley; Gregory R. Ganger, Carnegie Mellon University; Eric P. Xing, MBZUAI, Petuum, Inc., and Carnegie Mellon University
- Pollux 通过在每个作业级别和集群范围级别自适应地协同优化相互依赖的因素,提高了深度学习 (DL) 集群中的调度性能。大多数现有调度程序希望用户为每个作业指定资源数量,这通常会导致资源使用效率低下。最近的一些调度程序为用户选择作业资源,但没有意识到如何重新优化 DL 培训以更好地利用所提供的资源。
- Pollux 同时考虑这两个方面。通过在训练期间监控每个作业的状态,Pollux 模拟了它们的Goodput(我们引入的一种新指标,将系统吞吐量与统计效率相结合)将如何通过添加或删除资源而改变。利用这些信息,Pollux 动态(重新)分配资源以提高集群范围的吞吐量,同时尊重公平性并不断优化每个 DL 作业以更好地利用这些资源。
- 在真实 DL 作业和跟踪驱动模拟的实验中,相对于最先进的 DL 调度程序,Pollux 将平均作业完成时间减少了 37-50%,即使它们为每个作业提供了理想的资源和培训配置. Pollux 基于对“有用”作业进度的更有意义的衡量来促进竞争资源的 DL 作业之间的公平性,并揭示了在云环境中降低 DL 成本的新机会。Pollux 作为开源项目的一部分在https://github.com/petuum/adaptdl 上实施并公开可用。
Oort: Efficient Federated Learning via Guided Participant Selection
Fan Lai, Xiangfeng Zhu, Harsha V. Madhyastha, and Mosharaf Chowdhury, University of Michigan
- Federated Learning (FL) 是分布式机器学习 (ML) 的一个新兴方向,它支持对边缘数据进行原位模型训练和测试。尽管与传统 ML 具有相同的最终目标,但 FL 执行的规模差异很大,涉及数千到数百万的参与设备。因此,数据特征和设备功能因客户端而异。然而,现有的努力随机选择 FL 参与者,这导致模型和系统效率不佳。
- 在本文中,我们建议 Oort 通过引导参与者选择来提高联合训练和测试的性能。为了提高模型训练的准确时间性能,Oort 优先使用那些拥有在提高模型准确度方面提供最大效用和快速运行训练能力的数据的客户。为了让 FL 开发人员能够在模型测试中解释他们的结果,Oort 对参与者数据的分布实施了他们的要求,同时缩短了挑选客户的联合测试的持续时间。我们的评估表明,与现有的参与者选择机制相比,Oort 将时间精度性能提高了 1.2X-14.1X,将最终模型的准确度提高了 1.3%-9.8%,
PET: Optimizing Tensor Programs with Partially Equivalent Transformations and Automated Corrections
Haojie Wang, Jidong Zhai, Mingyu Gao, Zixuan Ma, Shizhi Tang, and Liyan Zheng, Tsinghua University; Yuanzhi Li, Carnegie Mellon University; Kaiyuan Rong and Yuanyong Chen, Tsinghua University; Zhihao Jia, Carnegie Mellon University and Facebook
- 高性能张量程序对于在实际任务中有效部署深度神经网络 (DNN) 模型至关重要。现有框架通过应用完全等效的变换来优化张量程序,这些变换在输出张量的每个元素上保持等效。这种方法错过了可能的优化机会,因为排除了仅保留输出张量子集的等效性的转换。
- 我们提出了 PET,这是第一个通过部分等效转换和自动校正优化张量程序的 DNN 框架。PET 发现并应用可提高计算效率但仅保持部分功能等效的程序转换。然后 PET 会自动校正结果以恢复完全等效。我们开发了严格的理论基础来简化部分等效变换的等效检查和校正,并设计一种有效的搜索算法,通过在张量、运算符和图级别结合完全和部分等效优化来快速发现高度优化的程序。我们的评估表明,PET 比现有系统的性能高出 2.5 倍,因为它从部分等效的转换中释放了以前错失的机会。
Privacy Budget Scheduling
Tao Luo, Mingen Pan, Pierre Tholoniat, Asaf Cidon, and Roxana Geambasu, Columbia University; Mathias Lécuyer, Microsoft Research
- 在个人数据上训练的机器学习 (ML) 模型已被证明会泄露有关用户的信息。差分隐私 (DP) 使模型训练能够保证这种泄漏的界限。使用 DP 训练的每个新模型都会增加数据泄漏的界限,并且可以被视为消耗不应超过的全球隐私预算的一部分。该预算是一种稀缺资源,必须谨慎管理以最大限度地增加成功训练的模型数量。
- 我们描述了 PrivateKube,它是流行的 Kubernetes 数据中心编排器的扩展,它将隐私作为一种新型资源与其他传统计算资源(例如 CPU、GPU 和内存)一起管理。我们为隐私资源设计的抽象反映了 Kubernetes 为传统资源定义的抽象,但也存在重大差异。例如,传统的计算资源是可补充的,而隐私则不可补充:模型完成执行后可以重新获得 CPU,而隐私预算则不能。这种区别迫使重新设计调度程序。我们提出了 DPF(主导私有区块公平)——流行的主导资源公平(DRF)算法的一种变体——它面向不可补充的隐私资源,但具有与 DRF 相似的理论特性。
- 我们在微基准测试上评估 PrivateKube 和 DPF,并在 Amazon Reviews 数据上评估 ML 工作负载。与现有基线相比,DPF 允许在相同的全局隐私保证下训练更多模型。对于 DPF over Rényi DP 尤其如此,这是一种高度可组合的 DP 形式。
2. Storage(存储)
Session Chairs: Dushyanth Narayanan, Microsoft Research, and Gala Yadgar, Technion—Israel Institute of Technology
Modernizing File System through In-Storage Indexing
Jinhyung Koo, Junsu Im, Jooyoung Song, and Juhyung Park, DGIST; Eunji Lee, Soongsil University; Bryan S. Kim, Syracuse University; Sungjin Lee, DGIST
- 我们认为文件系统和 SSD 之间的键值接口优于传统的块接口,通过提供 KEVIN。KEVIN 将快速、轻量且符合 POSIX 的文件系统与执行存储索引的键值存储设备相结合。我们在存储设备中实现了一种日志结构合并树的变体,它不仅索引文件对象,还支持事务和管理物理存储空间。因此,简化了与空间管理和崩溃一致性相关的文件系统设计,仅需要 10.8K LOC 即可实现全部功能。我们证明了 KEVIN 减少了主机和设备之间的 I/O 流量,并且随着系统老化和数据变得碎片化而保持特别稳健。对于元数据密集型基准测试,我们的方法大大优于块 SSD 上的现有文件系统 - 平均 6.2 倍。对于实际工作负载,KEVIN 将吞吐量平均提高 68%。
Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
Qing Wang, Youyou Lu, Junru Li, and Jiwu Shu, Tsinghua University
- 我们提出了Nap,这是一种将并发持久内存 (PM) 索引转换为 NUMA 感知对应物的黑盒方法。基于观察到现实世界的工作负载总是具有倾斜的访问模式,Nap在现有并发 PM 索引的顶部引入了一个 NUMA 感知层 (NAL),并将对热点项目的访问引导到这一层。NAL 维护 1) PM 中的每个节点部分视图,用于为具有故障原子性的插入/更新/删除操作提供服务,以及 2) DRAM 中的全局视图,用于提供查找操作。NAL 消除了对热门项目的远程 PM 访问,而不会引起额外的本地 PM 访问。此外,为了处理动态工作负载,Nap采用了快速 NAL 切换机制。我们使用Nap转换了五个最先进的 PM 索引. 在具有 Optane DC 持久性内存的四节点机器上的评估表明,在写入密集型和读取密集型工作负载下,Nap可以分别将吞吐量提高 2.3✕ 和 1.56✕。
Rearchitecting Linux Storage Stack for µs Latency and High Throughput
Jaehyun Hwang and Midhul Vuppalapati, Cornell University; Simon Peter, UT Austin; Rachit Agarwal, Cornell University
- 本文表明,即使数十个对延迟敏感的应用程序与以接近硬件容量的吞吐量执行读/写操作的吞吐量受限应用程序竞争主机资源,也可以使用 Linux 内核存储堆栈实现 μs 级延迟。此外,无需对应用程序、网络硬件、内核 CPU 调度程序和/或内核网络堆栈进行任何修改即可实现此类性能。
- 我们使用
blk-switch新的 Linux 内核存储堆栈架构的设计、实现和评估来演示上述内容。在关键的见解blk-switch是认为Linux的多队列存储设计,具有多队列网络和存储硬件一起,使概念上类似于一个网络交换机的存储堆栈。blk-switch使用这种洞察力将计算机网络文献中的技术(例如,多个出口队列、单个请求的优先处理、负载平衡和交换机调度)应用于 Linux 内核存储堆栈。 - 对各种场景的 blk-switch 评估表明,它始终如一地实现 μs 级平均和尾部延迟(在第99个和第99.9个百分位数处),同时允许应用程序近乎完美地利用硬件容量。
Optimizing Storage Performance with Calibrated Interrupts
Amy Tai, VMware Research; Igor Smolyar, Technion — Israel Institute of Technology; Michael Wei, VMware Research; Dan Tsafrir, Technion — Israel Institute of Technology and VMware Research
- 请求完成后,I/O 设备必须决定要么通过立即触发中断来最小化延迟,要么通过延迟中断来优化吞吐量,预计更多的请求将很快完成并帮助分摊中断成本。设备采用自适应中断合并试探法,试图在这些对立的目标之间取得平衡。不幸的是,由于设备缺乏有关哪些 I/O 请求对延迟敏感的语义信息,这些启发式方法有时会导致灾难性的结果。
- 相反,我们建议通过允许软件明确指定设备是否提交的请求对延迟敏感,从而解决启发式问题的根本原因。然后,设备“校准”其中断以完成对延迟敏感的请求。我们专注于 NVMe 存储设备,并表明在内核和应用程序中表达这些语义是很自然的,并且只需要对设备接口进行适度的两位更改。校准中断可将吞吐量提高多达 35%,将 CPU 消耗降低多达 30%,并在合并中断时将延迟降低多达 37%。
ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Compaction
Kyuhwa Han, Sungkyunkwan University and Samsung Electronics; Hyunho Gwak and Dongkun Shin, Sungkyunkwan University; Jooyoung Hwang, Samsung Electronics
- NVMe 分区命名空间 (ZNS) 正在作为一种新的存储接口出现,其中逻辑地址空间被划分为固定大小的区域,并且每个区域必须按顺序写入以方便闪存访问。由于 ZNS 的顺序只写区域方案,访问 ZNS 固态驱动器 (SSD) 需要日志结构文件系统 (LFS)。虽然在目前的 ZNS 接口下可以简化 SSD,但其对应的 LFS 必须承担段压缩开销。
- 为了解决这个问题,我们提出了一种新的 LFS 感知 ZNS 接口,称为 ZNS+,及其实现,其中主机可以将数据复制操作卸载到 SSD 以加速段压缩。ZNS+ 还允许使用稀疏顺序写入请求覆盖每个区域,这使 LFS 能够使用基于线程日志记录的块回收而不是段压缩。我们还为 ZNS+-aware LFS 提出了两种文件系统技术。回拷感知块分配考虑 SSD 内不同复制路径的不同复制成本。混合段回收基于它们的成本在段压缩和线程日志之间选择合适的块回收策略。
- 我们在 SSD 模拟器和真正的 SSD 上实现了 ZNS+ SSD。所提出的 ZNS+ 存储系统的文件系统性能是基于 ZNS 的普通存储系统的 1.33–2.91 倍。混合段回收基于它们的成本在段压缩和线程日志之间选择合适的块回收策略。我们在 SSD 模拟器和真正的 SSD 上实现了 ZNS+ SSD。所提出的 ZNS+ 存储系统的文件系统性能是基于 ZNS 的普通存储系统的 1.33–2.91 倍。混合段回收基于它们的成本在段压缩和线程日志之间选择合适的块回收策略。我们在 SSD 模拟器和真正的 SSD 上实现了 ZNS+ SSD。所提出的 ZNS+ 存储系统的文件系统性能是基于 ZNS 的普通存储系统的 1.33–2.91 倍。
3. Data Management(数据管理)
Session Chairs: Deniz Altinbüken, Google, and Rashmi Vinayak, Carnegie Mellon University
DMon: Efficient Detection and Correction of Data Locality Problems Using Selective Profiling
Tanvir Ahmed Khan and Ian Neal, University of Michigan; Gilles Pokam, Intel Corporation; Barzan Mozafari and Baris Kasikci, University of Michigan
- 糟糕的数据局部性会损害应用程序的性能。虽然已经提出了基于编译器的技术来改善数据局部性,但它们依赖于启发式,这有时会损害性能。因此,开发人员通常通过动态分析发现数据局部性问题并手动修复它们。另外现有的分析技术在用于识别数据局部性问题时会产生高开销,并且无法部署在生产中,其中程序可能会出现以前未见过的性能问题。
- 我们提出了selective profiling,这是一种以足够低的开销定位数据局部性问题的技术,适合生产使用。为了实现低开销,selective profiling有选择地、增量地收集运行时执行信息。使用selective profiling,我们构建了 DMon,该系统可以自动定位生产中的数据局部性问题,识别损害局部性的访问模式,并使用有针对性的优化修复此类模式。
- 由于selective profiling,DMon 的分析开销平均为 1.36%,使其可用于生产用途。与使用最高级别编译器优化的基线相比,DMon 的目标优化平均提供 16.83% 的加速(高达 53.14%)。DMon 将最受欢迎的数据库系统之一 PostgreSQL 平均加速 6.64%(最高 17.48%)。
CLP: Efficient and Scalable Search on Compressed Text Logs
Kirk Rodrigues, Yu Luo, and Ding Yuan, University of Toronto and YScope Inc.
- 本文介绍了 CLP 的设计和实现,这是一种能够无损压缩非结构化文本日志的工具,同时能够直接对压缩数据进行快速搜索。日志搜索和日志归档虽然是关键问题,但它们是相互排斥的。广泛使用的日志搜索工具(如 Elasticsearch 和 Splunk Enterprise)索引日志以提供快速搜索性能,但索引的大小与原始日志大小在同一数量级内。常用的日志归档和压缩工具如 Gzip 提供了高压缩率,但搜索归档日志是一个缓慢而痛苦的过程,因为它首先需要对日志进行解压缩。相比之下,CLP 实现了比所有常用压缩机更高的压缩比,提供与 Elasticsearch 和 Splunk Enterprise 相当甚至更好的快速搜索性能。
- 此外,CLP 的日志摄取性能优于 Elasticsearch 和 Splunk Enterprise 的 13 倍以上,并且我们展示了 CLP 可扩展到 PB 级的日志。CLP 的收益来自于使用经过调整的、特定于域的压缩和搜索算法,该算法利用了文本日志中的大量重复。因此,CLP 支持对存档日志进行高效搜索和分析,如果没有它,这是不可能的。特定领域的压缩和搜索算法,利用文本日志中的大量重复。因此,CLP 支持对存档日志进行高效搜索和分析,如果没有它,这是不可能的。特定领域的压缩和搜索算法,利用文本日志中的大量重复。因此,CLP 支持对存档日志进行高效搜索和分析,如果没有它,这是不可能的。
Polyjuice: High-Performance Transactions via Learned Concurrency Control
Jiachen Wang, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Ding Ding, Department of Computer Science, New York University; Huan Wang, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Conrad Christensen, Department of Computer Science, New York University; Zhaoguo Wang and Haibo Chen, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Jinyang Li, Department of Computer Science, New York University
- 并发控制算法是内存数据库性能的关键决定因素。现有算法被设计为适用于某些工作负载。例如,在低争用情况下,乐观并发控制(OCC)优于两相锁定(2PL),而在高争用情况下则相反。
- 为了适应不同的工作负载,先前的工作使用手动洞察或简单的启发式方法在一些已知算法之间混合或切换。我们提出了一个基于学习的框架,它通过离线训练显式优化并发控制以最大化性能。我们的方法不是在少数已知算法中进行选择,而是在细粒度操作的“策略空间”中进行搜索,从而产生通过专门针对给定工作负载而优于现有算法的新算法。
- 我们基于我们的学习框架构建 Polyjuice,并根据几种现有算法对其进行评估。在 TPC-C 和 TPC-E 的不同配置下,Polyjuice 可以实现比现有最佳算法高 15% 到 56% 的吞吐量数。
Retrofitting High Availability Mechanism to Tame Hybrid Transaction/Analytical Processing
Sijie Shen, Rong Chen, Haibo Chen, and Binyu Zang, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai Artificial Intelligence Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China
- 通过对并发事务生成的实时数据集执行查询,许多应用程序域可以从混合事务/分析处理 (HTAP) 中受益。然而,由于大内存和快速互连导致交易和查询越来越快,商用 HTAP 系统必须在数据新鲜度和性能下降之间做出权衡。幸运的是,我们观察到现代分布式 OLTP 系统中的高可用性备份可以进行改造,以桥接 HTAP 工作负载中的分析查询和事务。
- 在本文中,我们介绍了Vegito,一种分布式内存 HTAP 系统,它采用以下三种技术实现新鲜度和性能:(1)轻量级八卦式方案,以一致地将日志应用于备份;(2) 多版本列式备份的基于块的设计;(3) 一种基于树的备份索引的两阶段并发更新机制。他们共同使备份保持新鲜、柱状和容错,甚至面临每秒数百万个并发事务。
- 评估显示Vegito可以执行 190 万次 TPC-C NewOrder事务和每秒 24 个 TPC-H 等效查询,保留了专门的 OLTP 和 OLAP 对应物(例如 DrTM+H 和 MonetDB)的出色性能。这些结果在事务性能上优于最先进的 HTAP 系统几个数量级,同时几乎不会导致性能下降(比纯 OLTP 工作负载低 5%),并且仍然享受分析查询的数据新鲜度(最大小于 20 毫秒)延迟)在无故障情况下。此外,Vegito可以在不到 60 毫秒的时间内使用柱状备份从级联机器故障中恢复。
4. Operating Systems and Hardware(操作系统和硬件)
Session Chairs: Nadav Amit, VMware Research Group, and Ada Gavrilovska, Georgia Institute of Technology
The nanoPU: A Nanosecond Network Stack for Datacenters
Stephen Ibanez, Alex Mallery, Serhat Arslan, and Theo Jepsen, Stanford University; Muhammad Shahbaz, Purdue University; Changhoon Kim and Nick McKeown, Stanford University
- 我们展示了 nanoPU,这是一种新的 NIC-CPU 协同设计,用于加速日益普及的一类数据中心应用程序:那些利用许多小型远程过程调用 (RPC) 且处理时间非常短(微秒级)的应用程序。nanoPU 的新颖之处在于设计了网络和应用程序之间的快速路径——绕过缓存和内存层次结构,并将到达的消息直接放入 CPU 寄存器文件中。该快速路径包含对低延迟传输和拥塞控制的可编程硬件支持,以及对 RPC 到内核的高效负载平衡的硬件支持。硬件加速的线程调度程序做出亚纳秒级的决策,从而导致 RPC 的 CPU 利用率高和尾部响应时间短。
- 我们通过修改开源 RISC-V CPU 构建了 nanoPU 快速路径的 FPGA 原型,并使用 AWS FPGA 上的周期精确模拟来评估其性能。通过 nanoPU 的线对线 RPC 响应时间仅为 69ns,比同类最佳的低延迟商业 NIC 快一个数量级。我们证明了硬件线程调度器能够将 RPC 尾部响应时间降低约 5✕,同时使系统能够承受比传统线程调度技术高 20% 的负载。我们实施和评估了一套应用程序,包括用于文档检索的 MICA、Raft 和 Set Algebra;并且我们证明了 nanoPU 可以用作单边 RDMA 操作的高性能、可编程替代方案。
Beyond malloc efficiency to fleet efficiency: a hugepage-aware memory allocator
A.H. Hunter, Jane Street Capital; Chris Kennelly, Paul Turner, Darryl Gove, Tipp Moseley, and Parthasarathy Ranganathan, Google
- 内存分配代表了仓库规模的巨大计算成本,其优化可以节省大量成本。一种经典方法是提高分配器的效率以最小化分配器代码中花费的周期。但是,内存分配决策也会通过数据放置影响整体应用程序性能,从而提供机会通过使用更少的硬件资源完成更多的应用程序工作单元来提高整个团队的生产力。在这里,我们专注于大页面覆盖。我们展示了 TEMERAIRE,它是 TCMALLOC 的大页感知增强,用于减少应用程序代码中的 CPU 开销。
- 我们讨论了 TEMERAIRE 的设计和实现,包括大页面感知内存布局的策略,以最大化大页面覆盖率和最小化碎片开销。我们介绍了 8 个应用程序的应用程序研究,将每秒请求数 (RPS) 提高了 7.7%,并将 RAM 使用率降低了 2.4%。我们展示了车队规模的 1% 实验结果以及谷歌仓库规模计算机的纵向部署。这使 TLB 未命中停顿减少了 6%,并且由于碎片而浪费的内存减少了 26%。我们最后讨论了用于改进分配器开发过程的其他技术以及未来内存分配器的潜在优化策略。
Scalable Memory Protection in the PENGLAI Enclave
Erhu Feng, Xu Lu, Dong Du, Bicheng Yang, and Xueqiang Jiang, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Yubin Xia, Binyu Zang, and Haibo Chen, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China
- 安全硬件enclaves 已被广泛用于保护云中的安全关键应用程序。然而,现有的 enclave 设计无法满足无服务器计算等新场景对可扩展性的要求,主要是由于其安全内存保护机制的局限性,包括静态分配、容量受限和高成本初始化。在本文中,我们提出了一种软硬件协同设计,以支持动态、细粒度、大规模的安全内存以及快速初始化。我们首先介绍两个新的硬件原语: 1) Guarded Page Table (GPT),它保护页表页以支持页级安全内存隔离;2) Mountable Merkle Tree (MMT),支持安全内存的可扩展完整性保护。
- 在这两个基元上,我们已经实现了基于蓬莱的设计原型,蓬莱是 RISC-V 的开源enclaves 系统。实验结果表明,蓬莱可支持1000s个enclave实例并发运行,并可扩展至512GB安全内存,同时具有加密和完整性保护。GPT 的开销对于内存密集型工作负载(例如 Redis)是 5%,对于 CPU 密集型工作负载(例如 RV8 和 Coremarks)可以忽略不计。蓬莱还将安全内存初始化的延迟降低了三个数量级,并将实际应用程序(例如 MapReduce)的速度提高了 3.6 倍。
NrOS: Effective Replication and Sharing in an Operating System
Ankit Bhardwaj and Chinmay Kulkarni, University of Utah; Reto Achermann, University of British Columbia; Irina Calciu, VMware Research; Sanidhya Kashyap, EPFL; Ryan Stutsman, University of Utah; Amy Tai and Gerd Zellweger, VMware Research
- 众所周知,编写正确的操作系统内核非常困难。内核代码需要手动内存管理和类型不安全代码,并且必须有效地处理复杂的异步事件。此外,增加 CPU 内核数使内核开发更加复杂。通常,单片内核跨内核共享状态并依赖于专用于每个内核结构或子系统的一次性同步模式。因此,内核开发人员不断改进操作系统内核内的同步,以提高可扩展性,但冒着引入细微错误的风险。
- 我们展示了 NrOS,这是一种新的操作系统内核,具有更安全的同步方法,可以运行许多 POSIX 程序。NrOS 主要构建为一个简单的、顺序的内核,没有并发,使其更容易开发和推理其正确性。该内核使用节点复制跨 NUMA 节点进行扩展,这是一种受分布式系统中状态机复制启发的方案。NrOS 在每个 NUMA 节点上复制内核状态,并使用操作日志来保持副本之间的强一致性。内核可以安全地同时从其本地内核副本中读取数据,从而消除远程 NUMA 访问。
- 我们的评估表明,NrOS 可扩展到 96 个内核,其性能几乎总是在规模上占主导地位,在某些情况下是几个数量级,同时保留了顺序内核的大部分简单性。
5. Security and Privacy(安全和隐私)
Session Chairs: Sebastian Angel, University of Pennsylvania, and Malte Schwarzkopf, Brown University
Addra: Metadata-private voice communication over fully untrusted infrastructure
Ishtiyaque Ahmad, Yuntian Yang, Divyakant Agrawal, Amr El Abbadi, and Trinabh Gupta, University of California Santa Barbara
- 来自语音通话的元数据,例如谁与谁通信的知识,包含有关人们生活的丰富信息。事实上,它是民族国家等强大对手的主要目标。隐藏语音呼叫元数据的现有系统要么需要网络中受信任的中介,要么仅扩展到数十个用户。本文描述了 Addra 的设计、实现和评估,这是第一个语音通信系统,它在完全不受信任的基础设施上隐藏元数据并扩展到数万用户。在较高级别上,Addra 遵循一个模板,在该模板中,呼叫者和被呼叫者在不受信任的服务器上托管的私人邮箱中存入和检索消息。然而,Addra 改善了该架构中的消息延迟,这是语音呼叫的关键性能指标。第一的,它使呼叫者能够在两跳中将消息推送给被呼叫者,使用一种新的方式将邮箱分配给用户,类似于邮局向其客户分配邮政信箱的方式。其次,它在底层密码机制上进行了创新,并构建了一种新的私有信息检索方案 FastPIR,从而减少了处理邮箱不经意访问请求的时间。
- 在 AWS 上的 80 台机器集群上对 Addra 的评估表明,它可以为 32K 用户提供服务,消息延迟为 726 毫秒,比之前的相同威胁模型中的文本消息系统提高了 7✕。它在底层密码机制上进行了创新,并构建了一种新的私有信息检索方案 FastPIR,以减少处理对邮箱的不经意访问请求的时间。在 AWS 上的 80 台机器集群上对 Addra 的评估表明,它可以为 32K 用户提供服务,消息延迟为 726 毫秒,比之前的相同威胁模型中的文本消息系统提高了 7✕。它在底层密码机制上进行了创新,并构建了一种新的私有信息检索方案 FastPIR,以减少处理对邮箱的不经意访问请求的时间。在 AWS 上的 80 台机器集群上对 Addra 的评估表明,它可以为 32K 用户提供服务,消息延迟为 726 毫秒,比之前的相同威胁模型中的文本消息系统提高了 7✕。
Bringing Decentralized Search to Decentralized Services
Mingyu Li, Jinhao Zhu, and Tianxu Zhang, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Cheng Tan, Northeastern University; Yubin Xia, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China; Sebastian Angel, University of Pennsylvania; Haibo Chen, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University; Shanghai AI Laboratory; Engineering Research Center for Domain-specific Operating Systems, Ministry of Education, China
- 本文解决了当前去中心化服务和区块链应用程序生态系统中的一个关键缺失部分:缺乏去中心化、可验证和私人搜索。现有的去中心化系统,如 Steemit、OpenBazaar 和越来越多的区块链应用程序,为现有服务提供了替代方案。然而,他们继续依靠集中式搜索引擎和索引器来帮助用户访问他们寻找的内容并浏览应用程序。这种中心化引擎非常适合审查内容和侵犯用户隐私,破坏去中心化背后的一些关键原则。
- 为了解决这个问题,我们推出了 DeSearch,这是第一个保证去中心化服务和区块链应用程序搜索结果的完整性和隐私性的去中心化搜索引擎。DeSearch 使用受信任的硬件来构建一个工作网络,这些工作人员执行一系列小型搜索引擎任务(抓取、索引、聚合、排名、查询)。DeSearch 然后引入了见证机制,以确保完成的任务可以在不同的管道中重复使用,并使最终的搜索结果可以被最终用户验证。我们为两个现有的去中心化服务实施 DeSearch,这些服务处理超过 8000 万条记录和 240 GB 的数据,并表明 DeSearch 可以随着工作人员的数量水平扩展,并且每天可以处理 1.28 亿次搜索查询。
Finding Consensus Bugs in Ethereum via Multi-transaction Differential Fuzzing
Youngseok Yang, Seoul National University; Taesoo Kim, Georgia Institute of Technology; Byung-Gon Chun, Seoul National University and FriendliAI
- 以太坊是仅次于比特币的第二大区块链平台。在以太坊网络中,去中心化的以太坊客户端通过根据以太坊规范转换到相同的区块链状态来达成共识。共识错误是使以太坊客户端转换到不正确的区块链状态并且无法与其他客户端达成共识的错误。共识错误极为罕见,但可用于网络分裂和盗窃,从而导致以太坊生态系统中的可靠性和安全性关键问题。
- 我们描述了 Fluffy,一种用于在以太坊中查找共识错误的多事务差分模糊器。首先,Fluffy 变异并执行多事务测试用例,以发现使用现有的以太坊模糊器无法发现的共识错误。第二,Fluffy 使用多个现有的以太坊客户端,这些客户端独立地将规范实现为交叉引用预言机。
- 与最先进的模糊器相比,Fluffy 通过各种优化将模糊测试吞吐量提高了 510 倍,将代码覆盖率提高了 2.7 倍:进程内模糊测试、以太坊客户端的模糊测试以及减少错误的语义感知变异测试用例。Fluffy 在最受欢迎的 Geth 以太坊客户端中发现了两个新的共识错误,可在实时以太坊主网上加以利用。在我们向 Geth 开发人员报告错误四个月后,其中一个错误在主网上被触发,并导致使用过时版本的 Geth 的节点对以太坊区块链进行硬分叉。区块链社区认为这次硬分叉是自 2016 年臭名昭著的 DAO 黑客攻击以来最大的挑战。https://github.com/snuspl/fluffy为以太坊的安全做出贡献。
MAGE: Nearly Zero-Cost Virtual Memory for Secure Computation
Sam Kumar, David E. Culler, and Raluca Ada Popa, University of California, Berkeley
- 安全计算 (SC) 是一系列加密原语,用于在单方和多方设置中计算加密数据。SC 越来越多地被工业用于各种应用。在实际应用中使用 SC 的一个重大障碍是底层密码学的内存开销。我们开发了 MAGE,一种用于 SC 的执行引擎,可以有效地运行不适合内存的 SC 计算。我们观察到,由于其预期的安全保证,SC方案本质上是无视-their内存访问模式是独立的输入数据。使用此属性,MAGE 提前计算内存访问模式并使用它来生成内存管理计划。
- 这种内存管理的公式,我们称之为内存编程, 是分页的概括,它允许 MAGE 为 SC 提供高效的虚拟内存抽象。MAGE 的性能比 OS 虚拟内存系统高出一个数量级,并且在许多情况下,它以几乎相同的速度运行不适合内存的 SC 计算,就好像底层机器具有无限物理内存以适合整个计算一样。
Zeph: Cryptographic Enforcement of End-to-End Data Privacy
Lukas Burkhalter, Nicolas Küchler, Alexander Viand, Hossein Shafagh, and Anwar Hithnawi, ETH Zürich
- 随着越来越多的敏感数据被收集以获得有价值的见解,在数据分析框架中本地集成隐私控制的需求变得越来越重要。今天,隐私控制是由数据管理员强制执行的,他们可以完全访问明文数据。但是,最近发生的大量数据泄露事件表明,即使是广受信任的服务提供商也可能受到损害。此外,无法保证数据处理和处理符合所声称的隐私政策。这激发了对数据隐私的新方法的需求,该方法可以为用户提供强有力的保证和控制。
- 本文介绍了 Zeph,这是一个系统,使用户能够设置有关如何共享和处理其数据的隐私偏好。Zeph 以加密方式执行隐私政策,并确保第三方应用程序可用的数据符合用户的隐私政策。Zeph 实时执行遵守隐私的数据转换并扩展到数千个数据源,使其能够支持大规模的低延迟数据流分析。我们引入了一种混合加密协议,用于加密数据的隐私转换。
- 我们在 Apache Kafka 上开发了 Zeph 原型,以证明 Zeph 可以以低开销执行大规模隐私转换。我们引入了一种混合加密协议,用于加密数据的隐私转换。我们在 Apache Kafka 上开发了 Zeph 原型,以证明 Zeph 可以以低开销执行大规模隐私转换。我们引入了一种混合加密协议,用于加密数据的隐私转换。我们在 Apache Kafka 上开发了 Zeph 原型,以证明 Zeph 可以以低开销执行大规模隐私转换。
6. Correctness(正确性)
Session Chairs: Ryan Huang, Johns Hopkins University, and Manos Kapritsos, University of Michigan
DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols
Jianan Yao, Runzhou Tao, Ronghui Gu, Jason Nieh, Suman Jana, and Gabriel Ryan, Columbia University
- 众所周知,分布式系统由于不确定性而难以正确实施。找到分布式协议的归纳不变量是验证分布式系统正确性的关键步骤,但即使是简单的协议也需要很长时间。我们提出了 DistAI,这是一个数据驱动的自动化系统,用于学习分布式协议的归纳不变量。DistAI 通过模拟不同实例大小的分布式协议并记录状态作为样本来生成数据。基于观察到的不变量在实践中通常是简洁的,DistAI 从小的不变公式开始,并枚举所有样本的所有可能的最强不变量。然后它将这些不变量和所需的安全属性提供给 SMT 求解器,以检查不变量和安全属性的结合是否是归纳的。从小的不变公式和可能的最强不变式开始,避免大型 SMT 查询,提高 SMT 求解器性能。因为 DistAI 从可能最强的不变量开始,如果 SMT 求解器失败,DistAI 不需要丢弃失败的不变量,但知道单调削弱它们并与求解器再次尝试,重复该过程直到最终成功。我们证明了 DistAI 可以保证找到无∃-free 的归纳不变量,如果存在的话,可以在有限的时间内证明所需的安全属性。
GoJournal: a verified, concurrent, crash-safe journaling system
Tej Chajed, MIT CSAIL; Joseph Tassarotti, Boston College; Mark Theng, MIT CSAIL; Ralf Jung, MPI-SWS; M. Frans Kaashoek and Nickolai Zeldovich, MIT CSAIL
- 本文的主要贡献是 GoJournal,一个经过验证的并发日志系统,为存储应用程序提供原子性,以及 Perennial 2.0,一个正式指定和验证并发崩溃安全系统的框架。GoJournal 的目标是将代码日志的优势带到规范和证明中。Perennial 2.0 通过引入多种技术来规范 GoJournal 的规范并管理 GoJournal 实现证明中的复杂性,从而使这成为可能。提升谓词和崩溃框架使规范易于开发人员使用,逻辑原子崩溃规范允许在 GoJournal 中进行模块化推理,尽管存在复杂的并发和崩溃交错,但仍使证明易于处理。
- GoJournal 在 Go 中实现,Perennial 在 Coq 证明助手中实现。在验证 GoJournal 时,我们发现了一个严重的并发错误,尽管 GoJournal 有很多单元测试。我们构建了一个名为 GoNFS 的功能性 NFSv3 服务器来使用 GoJournal。性能实验表明,GoNFS 提供了与导出 ext4 文件系统的 Linux NFS 服务器相似的性能(例如,在 NVMe 磁盘上的多个基准测试中至少有 90% 的吞吐量),这表明 GoJournal 是一个具有竞争力的日志系统。我们还使用 GoJournal 的规范验证了一个简单的 NFS 服务器,这证实它们有助于应用程序验证:证明的重要部分不必考虑并发性和崩溃。
STORM: Refinement Types for Secure Web Applications
Nico Lehmann and Rose Kunkel, UC San Diego; Jordan Brown, Independent; Jean Yang, Akita Software; Niki Vazou, IMDEA Software Institute; Nadia Polikarpova, Deian Stefan, and Ranjit Jhala, UC San Diego
- 我们提出了Storm,这是一个 Web 框架,允许开发人员通过编译时执行集中指定的数据相关安全策略来构建 MVC 应用程序。Storm使用安全类型 ORM来确保安全性,该ORM通过描述底层操作产生和使用的数据以及允许访问该数据的用户的逻辑断言来细化 MVC API 每一层的(类型)抽象。为了评估Storm的安全保证,我们使用 Labeled IO (LIO) IFC 框架构建了一个经过正式验证的参考实现。我们展示了案例研究和端到端应用程序,展示了Storm 允许开发人员指定不同的策略,同时将受信任的代码集中到应用程序的 1% 以下,并以适度的类型注释开销静态强制安全性,并且没有运行时成本。
Horcrux: Automatic JavaScript Parallelism for Resource-Efficient Web Computation
Shaghayegh Mardani, UCLA; Ayush Goel, University of Michigan; Ronny Ko, Harvard University; Harsha V. Madhyastha, University of Michigan; Ravi Netravali, Princeton University
- 当今的网页通常包含大量 JavaScript 代码,以便为用户提供动态体验。这些脚本通常会使页面加载缓慢,部分原因是浏览器处理 JavaScript 内容的方式效率低下:浏览器通过在页面中的任何框架上串行执行所有脚本,使 Web 开发人员可以轻松地推断页面状态,但结果是,无法利用即使在低端手机上也很容易使用的多个 CPU 内核。
- 在本文中,我们展示了如何在不需要重写页面或修改浏览器的情况下解决这种低效率问题。我们的解决方案 Horcrux 的关键是考虑网页加载固有的非确定性以及浏览器 API 对并行性的限制。 Horcrux 兼容的 Web 服务器对它们所服务的任何框架上的所有 JavaScript 代码执行离线分析,以保守地识别每个 JavaScript 函数的页面状态的联合,该函数可以跨该页面的所有负载访问该页面状态。 Horcrux 的 JavaScript 调度程序然后使用此信息在客户端明智地并行化 JavaScript 执行,以便最终状态与串行执行相同,同时最大限度地减少协调和卸载开销。在涵盖发达和新兴地区的 Web 工作负载的各种页面、电话和移动网络中,Horcrux 将浏览器计算延迟的中位数减少了 31-44%,并将页面加载时间减少了 18-37%。
SANRAZOR: Reducing Redundant Sanitizer Checks in C/C++ Programs
Jiang Zhang, University of Southern California; Shuai Wang, HKUST; Manuel Rigger, Pinjia He, and Zhendong Su, ETH Zurich
- Sanitizers通过插入在程序执行期间经过验证的检查来检测不安全的操作,例如无效的内存访问。尽管它们广泛用于调试和漏洞发现,但清理程序检查通常会导致高运行时成本。成本高的一个重要原因是,正如我们在本文中观察到的,许多消毒检查是多余的——重复检查相同的安全属性——导致不必要的计算资源浪费。为了更有效地利用Sanitizers,我们推出了 SanRazor,这是一种实用工具,旨在有效检测和删除多余的Sanitizers检查。 SanRazor 采用了一种新颖的混合方法——它同时捕获检查的动态代码覆盖率和静态数据依赖性,并使用提取的信息执行冗余检查分析。
- 我们对 SPEC 基准的评估表明,SanRazor 可以显着降低Sanitizers的开销,从 AddressSanitizer 的 73.8% 到 28.0-62.0%,以及 UndefinedBehaviorSanitizer 的 160.1% 到 36.6-124.4%(取决于应用的减少方案)。我们对来自 10 个常用程序的 38 个 CVE 的进一步评估表明,SanRazor 减少的检查足以检测 38 个 CVE 中的至少 33 个。此外,通过将 SanRazor 与现有的Sanitizers减少工具尽快结合,我们通过将运行时成本降低到仅 7.0% 并在安全性的合理权衡下显示出协同效应。
7. Graph Embeddings and Neural Networks(图嵌入和神经网络)
Session Chairs: Moshe Gabel, University of Toronto, and Joseph Gonzalez, University of California, Berkeley
Dorylus: Affordable, Scalable, and Accurate GNN Training with Distributed CPU Servers and Serverless Threads
John Thorpe, Yifan Qiao, Jonathan Eyolfson, and Shen Teng, UCLA; Guanzhou Hu, UCLA and University of Wisconsin, Madison; Zhihao Jia, CMU; Jinliang Wei, Google Brain; Keval Vora, Simon Fraser; Ravi Netravali, Princeton University; Miryung Kim and Guoqing Harry Xu, UCLA
- 图神经网络 (GNN) 支持对结构化图数据进行深度学习。有两个主要的 GNN 训练障碍:1)它依赖于具有许多 GPU 的高端服务器,购买和维护成本高昂,2)GPU 上的有限内存无法扩展到今天的十亿边图。本文介绍了 Dorylus:一个用于训练 GNN 的分布式系统。独特的是,Dorylus 可以利用无服务器计算以低成本提高可扩展性。
- 指导我们设计的关键见解是计算分离。计算分离使得构建深度、有界异步管道成为可能,其中图和张量并行任务可以完全重叠,有效地隐藏了 Lambda 引起的网络延迟。在数千个 Lambda 线程的帮助下,Dorylus 将 GNN 训练扩展到十亿边的图。目前,对于大型图形,CPU 服务器提供的每美元性能优于 GPU 服务器。与仅使用 CPU 服务器进行训练相比,仅在 CPU 服务器上使用 Lambda 可提供高达 2.75✕ 的每美元性能。具体来说,对于大规模稀疏图,Dorylus 比 GPU 服务器快 1.22✕,便宜 4.83✕。与现有的基于采样的系统相比,Dorylus 的速度提高了 3.8✕,成本降低了 10.7✕。
GNNAdvisor: An Adaptive and Efficient Runtime System for GNN Acceleration on GPUs
Yuke Wang, Boyuan Feng, Gushu Li, Shuangchen Li, Lei Deng, Yuan Xie, and Yufei Ding, University of California, Santa Barbara
- 作为基于图的深度学习的新兴趋势,图神经网络 (GNN) 以其生成高质量节点特征向量(嵌入)的能力而著称。然而,现有的一刀切 GNN 实现不足以赶上不断发展的 GNN 架构、不断增加的图大小和多样化的节点嵌入维度。为此,我们提出GNNAdvisor,一种自适应且高效的运行时系统,可在 GPU 平台上加速各种 GNN 工作负载。首先,GNNAdvisor 从 GNN 模型和输入图中探索和识别几个与性能相关的特征,并将它们用作 GNN 加速的新驱动力。其次,GNAdvisor 实现了一种为 GNN 计算量身定制的新颖高效的 2D 工作负载管理,以提高不同应用程序设置下的 GPU 利用率和性能。第三,GNAdvisor 根据 GPU 内存结构和 GNN 工作负载的特点,通过优雅地协调 GNN 的执行,利用 GPU 内存层次结构进行加速。此外,为了实现自动运行时优化,GNAdvisor 集成了一个轻量级分析模型,用于有效的设计参数搜索。
Marius: Learning Massive Graph Embeddings on a Single Machine
Jason Mohoney and Roger Waleffe, University of Wisconsin–Madison; Henry Xu, University of Maryland, College Park; Theodoros Rekatsinas and Shivaram Venkataraman, University of Wisconsin–Madison
- 我们提出了一种新框架,用于在单台机器上计算大规模图的嵌入。图嵌入是图中每个节点(和/或边类型)的固定长度向量表示,并且已成为在图上应用现代机器学习的事实上的方法。我们发现当前用于学习大规模图嵌入的系统受到数据移动的瓶颈,这导致资源利用率低下和训练效率低下。这些限制需要最先进的系统来在多台机器上分配训练。我们提出了 Marius,这是一种用于有效训练图嵌入的系统,该系统利用分区缓存和缓冲区感知数据排序来最小化磁盘访问并将数据移动与计算交错以最大化利用率。我们在各种基准测试中将 Marius 与两个最先进的工业系统进行比较。
- 我们证明了 Marius 达到了相同水平的准确度,但速度提高了一个数量级。我们还表明,Marius 可以将训练扩展到超出单台机器 GPU 和 CPU 内存容量一个数量级的数据集,从而能够在具有 16 GB GPU 内存的单台机器上训练具有超过 10 亿条边和 550 GB 总参数的配置和 64 GB 的 CPU 内存。Marius 在 www.marius-project.org 上是开源的。支持在具有 16 GB GPU 内存和 64 GB CPU 内存的单台机器上训练具有超过 10 亿条边和 550 GB 总参数的配置。Marius 在 www.marius-project.org 上是开源的。支持在具有 16 GB GPU 内存和 64 GB CPU 内存的单台机器上训练具有超过 10 亿条边和 550 GB 总参数的配置。Marius 在 www.marius-project.org 上是开源的。
P3: Distributed Deep Graph Learning at Scale
Swapnil Gandhi and Anand Padmanabha Iyer, Microsoft Research
- 图神经网络 (GNN) 在最近获得了极大的关注,并成为深度学习中增长最快的子领域之一。虽然已经提出了几种新的 GNN 架构,但真实世界图的规模(在许多情况下有数十亿个节点和边)在模型训练期间构成了挑战。在本文中,我们介绍了P3,这是一个专注于将 GNN 模型训练扩展到分布式设置中的大型真实世界图的系统。我们观察到,训练 GNN 的可扩展性挑战与训练经典深度神经网络和分布式图处理的挑战有着根本的不同;并且常用的技术(例如图的智能分区)不会产生预期的结果。基于这一观察,P3提出了一种新的分布式 GNN 训练方法。我们的方法有效地消除了高通信和分区开销,并将其与新的基于流水线推挽并行的执行策略相结合,以实现快速模型训练。P3公开了一个简单的 API,该 API 捕获了许多不同类别的 GNN 架构以供通用。当进一步结合简单的缓存策略时,我们的评估表明P3能够比现有的最先进的分布式 GNN 框架高出 7✕。
之前做的高速存储的性能优化;现在做的是多AZ的数据分布优化;后面的话可能考虑是数据分层、数据交换或者这种混合架构的性能优化,可能还要后面系统测试再看看问题

- 背景
- 构建对象存储服务(Object storage Service)、文件存储服务(File storage Service)、表存储(Tablestore)等横向云存储服务
- 利用分散存储、支持繁重的写和范围查询工作负载,以及平衡可伸缩性、可用性和资源使用
- 结合了LSM树和bw树的优点,并利用了硬件技术的进步
- 可收缩的页面映射表,清晰的系统和用户状态分离,快速恢复,写放大减少,高效的垃圾收集,轻量级的分区拆分和合并。

人类总会选择最安全、最中庸的道路前进,群星就会变成遥不可及的幻梦。— 小夫
第一个是基于LSM-tree的写性能比较好
第二个是我们cache设的比较小,导致所有kv的读性能较低
第三个是我们用的盘读写性能差不多,2900M/s 读带宽,2000M/s 写带宽
1) The write performance of LSM-tree-based KV store is very good due to converting small random writes into sequential writes effectively. We find that lots of papers about LSM-tree-based KV stores also show that the throughput of YCSB workload A is the same of better than the YCSB workloads B and C, such as WiscKey, UniKV, Remix, AC-key and so on. In addition, Wiredtiger has better read performance than writing, and the throughput of YCSB workload B or C is significantly better than A.
2) To show the optimization effect of read performance, the cache of KV stores is set to a small value (about 256M) and is cleared before the test of each YCSB workload, resulting in low read performance of all KV stores. This is illustrated in the db_bench test (Section 4.2), and we explain this briefly in the YCSB test, please see modification #3. In addition, we also test the performance in different cache sizes. We get a conclusion similar to Fig. 14 and TridentKV performs well.
3) The NVMe SSD used in the paper has a similar read/write bandwidth of 2900 M/s and 2000 M/s.