
大模型相关调研
说那六贼,一个唤做眼看喜,一个唤做耳听怒,一个唤做鼻嗅爱,一个唤作舌尝思,一个唤作意见欲,一个唤作身本忧 —— 老吴
问题
- 当前的问题:
- lustre上训练有时起不来,有时会卡住,ceph训练比cache慢
- 大模型参数卸载到主存或者磁盘上
- checkpoint 怎样快速的保存
- 整体规划
- NLP榜单登顶,主要涉及到算法,如何支持超过2000亿参数的模型训练
- 在顶会发表paper
- 重构整个训练及推理框架,6个月后开源
下一步计划:
分析使用lustre和ceph相关的问题
共享资料,分析啊现有的优化方法,分析现在大模型的训练瓶颈,寻找优化点
根据分析结果确定优化路径,时间点
第一代sensetime-LM训练框架
运行配置
环境搭建(集群1424,分区Model)
不能连外网 + 换了新仓库
- 运行环境(cuda-11.3,.bashrc,.local)
- 拷贝conda环境:/mnt/cache/share/spring/conda_envs/miniconda3
- 修改.local:直接复制/mnt/cache/share_data/zhanmingjie/.local_zhanmingjie_2021121501
- 修改.bashrc
- 直接复制/mnt/cache/share_data/zhanmingjie/.bashrc
- 修改cuda路径:/mnt/cache/share_data/zhanmingjie/cuda-11.3
- 修改.local路径:.local
- source ~/.bashrc
- pypi依赖安装
- regex deepspeed nltk numpy pandas sentencepiece boto3 torch tqdm jieba pybind11
- pypi新仓库 https://pkg.sensetime.com/repository/pypi-proxy/simple/
- pip install -i https://pkg.sensetime.com/repository/pypi-proxy/simple/ –trusted-host pypi.opencloud.sensetime.com regex
- conda依赖安装:nvidia-apex
- export TORCH_CUDA_ARCH_LIST=”compute capability”
- conda新仓库:https://opencloud.sensetime.com/#/registry/conda
- conda install -c conda-forge nvidia-apex
数据集:/mnt/cache/share_data/zhanmingjie/cpm-2-t5-data_8/…
运行脚本: src/scripts
- 当前问题:Model分区任务过多,没有资源
集群lg,分区pat_dev
环境:conda,cuda-11.3,apex,.bashrc,.local
当前问题:数据集过大,磁盘限额;放在ceph或者lustre,影响性能
预训练运行流程
- srun -p Model -N 8 –job-name=xm_10000 –gres=gpu:8 –cpus-per-task=64 –quotatype=spot bash pretrain_enc_dec_11b_fp32.sh
- slurm使用 https://confluence.sensetime.com/pages/viewpage.action?pageId=178346269
- –partition=Test:提交任务到 Test 分区,也可以简写为 -p Test
- –mpi=pmi2:提交 MPI 任务时的 MPI 类型,IntelMPI、Mvapich2、OpenMPI都可以使用 pmi2
- –gres=gpu:4:单个节点使用的 GPU 个数,如果不需要 GPU,则忽略该项
- –ntasks-per-node=4:单个节点最多的进程个数。在提交 SenseNet 时,每个进程占一个 GPU,所有应该和上面的 -gres 参数值保持一致
- -n12:作业总的进程数,Slurm 会根据总进程数和 –ntasks-per-node 来决定具体分配多少个节点,然后根据 -gres 决定每个节点分配多少个 GPU
- –job-name=HELLO:可选项,指定作业名称
- –kill-on-bad-exit=1: 可选项,若作业中某个进程意外终止,则终止整个作业。默认情况下单个进程终止不会停止整个作业
python -m torch.distributed.launch --nnodes 8 --node_rank 2 --nproc_per_node 8 --master_addr SH-IDC1-10-142-5-32 --master_port 6009 ../../../CPM-2-Pretrain/src/pretrain_enc_dec.py --use-new-lr --min-lr 0.0000006 --model-config ../../../CPM-2-Pretrain/src/configs/model/enc_dec_11b_config.json --model-parallel-size 1 --batch-size 48 --enc-seq-length 512 --dec-seq-length 256 --train-iters 300000 --save /mnt/lustre/lukai1/tmp/checkpoint/cpm-2-11b_n8_fp32_zero3_b48_lr2e6_20220112 --log-file /mnt/lustre/lukai1/tmp/log_11b_n8_fp32_zero3_b48_lr2e6_20220112.txt --load /mnt/lustre/lukai1/tmp/checkpoint/cpm-2-11b_n8_fp32_zero3_b48_lr2e6_20220112 --data-path /mnt/cache/share_data/zhanmingjie/cpm-2-t5-data_4/mix_cpm2_t5_document --data-impl mmap --split 950,30,20 --distributed-backend nccl --lr 0.000002 --no-load-optim --lr-decay-style linear --weight-decay 1e-2 --clip-grad 1.0 --warmup 0.01 --tokenizer-path ../../../CPM-2-Pretrain/src/bpe_cn --save-interval 1000 --eval-interval 500 --eval-iters 25 --log-interval 100 --checkpoint-activations --deepspeed-activation-checkpointing --deepspeed --deepspeed_config ../../../CPM-2-Pretrain/src/configs/deepspeed/ds_cpm2_11b_fp32.json - 参数脚本:cmd_pretrain_enc_dec_11b.sh
sensetime-LM代码
- CPM-2-Finetune:他们的代码
- CPM-2-Pretrain:他们的代码,deepspeed还未使用
- data模块
- DeepSpeedExamples
- Megatron-LM-v1.1.5-ZeRO3
- megatron-new
- data
- T5-dataset
- 调用了 helpers.cpp自己的mmap
- T5-dataset
- data
- megatron-new
- Megatron-LM-v1.1.5-ZeRO3
CPM-2-Pretrain
pretrain_enc_dec:主流程
def main(): # Disable CuDNN. torch.backends.cudnn.enabled = False # Timer. timers = Timers() # Arguments. args = get_args() os.makedirs(args.save, exist_ok=True) # Pytorch distributed. initialize_distributed(args) if torch.distributed.get_rank() == 0: print('Pretrain Enc-Dec model') print_args(args) with open(os.path.join(args.save, "args.json"), "w") as f: json.dump(vars(args), f) # Random seeds for reproducability. set_random_seed(args.seed) # setup tokenizer tokenizer = EncDecTokenizer(os.path.join(args.tokenizer_path, 'vocab.txt')) with open(args.deepspeed_config, "r") as f: ds_config = json.load(f) args.gradient_accumulation_steps = ds_config["gradient_accumulation_steps"] args.zero_stage = ds_config['zero_optimization']['stage'] # Model, optimizer, and learning rate. model, optimizer, lr_scheduler = setup_model_and_optimizer(args, tokenizer.vocab_size) optimizer.cur_scale = 4096 if torch.distributed.get_rank() == 0: print(args.iteration) # 数据集读取和划分 train_data_iterator, val_data_iterator, test_data_iterator = \ build_train_valid_test_data_iterators( train_valid_test_dataset_provider, args, tokenizer) #训练 iteration = 0 if args.train_iters > 0: iteration, skipped = train(tokenizer, model, optimizer, lr_scheduler, train_data_iterator, val_data_iterator, timers, args) prefix = 'the end of training for val data' evaluate_and_print_results(tokenizer, prefix, val_data_iterator, model, args, timers, False) #模型保存 checkpoint if args.save and iteration != 0: save_checkpoint(iteration, model, optimizer, lr_scheduler, args) if args.do_test: # Run on test data. prefix = 'the end of training for test data' evaluate_and_print_results(tokenizer, prefix, test_data_iterator, model, args, timers, True)from data.enc_dec_dataset import build_train_valid_test_datasets
- train_valid_test_dataset_provider调用
train_ds, valid_ds, test_ds = build_train_valid_test_datasets( tokenizer=tokenizer, data_prefix=args.data_path, data_impl=args.data_impl, splits_string=args.split, train_valid_test_num_samples=train_val_test_num_samples, enc_seq_length=args.enc_seq_length, dec_seq_length=args.dec_seq_length, seed=args.seed, skip_warmup=(not args.mmap_warmup))- data_impl: [‘lazy’, ‘cached’, ‘mmap’, ‘infer’]
- warmup:训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练
数据集

data模块
读取数据集,生成训练、验证、测试数据
enc_dec_dataset.py:数据集读取和格式处理
indexed_dataset.py:数据格式处理,包括np mmap 形式读取
helpers.cpp:自己mmap实现
dataset_utils.py:compile_helper
enc_dec_dataset: build_train_valid_test_datasets
get_indexed_dataset_:读取三种数据context,target,target_offset
make_indexed_dataset
indexed_dataset :make_dataset
infer:infer_dataset_impl,读取并根据magic,选择cached或者mmap
lazy:IndexedDataset
read_index(),read_data()
def read_index(self, path): with open(index_file_path(path), 'rb') as f: magic = f.read(8) assert magic == self._HDR_MAGIC, ( 'Index file doesn\'t match expected format. ' 'Make sure that --dataset-impl is configured properly.' ) version = f.read(8) assert struct.unpack('<Q', version) == (1,) code, self.element_size = struct.unpack('<QQ', f.read(16)) self.dtype = dtypes[code] self._len, self.s = struct.unpack('<QQ', f.read(16)) self.doc_count = struct.unpack('<Q', f.read(8)) self.dim_offsets = read_longs(f, self._len + 1) self.data_offsets = read_longs(f, self._len + 1) self.sizes = read_longs(f, self.s) self.doc_idx = read_longs(f, self.doc_count) def read_data(self, path): self.data_file = open(data_file_path(path), 'rb', buffering=0)
cached:IndexedCachedDataset(IndexedDataset)
- 封装了cache_index字典,预取
self.cache_index = {} def prefetch(self, indices): if all(i in self.cache_index for i in indices): return if not self.data_file: self.read_data(self.path) indices = sorted(set(indices)) total_size = 0 for i in indices: total_size += self.data_offsets[i + 1] - self.data_offsets[i] self.cache = np.empty(total_size, dtype=self.dtype) ptx = 0 self.cache_index.clear() for i in indices: self.cache_index[i] = ptx size = self.data_offsets[i + 1] - self.data_offsets[i] a = self.cache[ptx: ptx + size] self.data_file.seek(self.data_offsets[i] * self.element_size) self.data_file.readinto(a) ptx += size if self.data_file: # close and delete data file after prefetch so we can pickle self.data_file.close() self.data_file = Nonemmap:MMapIndexedDataset (IndexedDataset)
- 主要成员:_path, _index, _bin_buffer, _bin_buffer_mmap
self._bin_buffer_mmap = np.memmap(data_file_path(self._path), mode='r', order='C') self._bin_buffer = memoryview(self._bin_buffer_mmap)- memoryview:函数返回给定参数的内存查看对象(memory view),所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问
- 对内存地址的直接访问,char *p = data;
- 主要函数:_do_init,write,get,__del__,__setstate__等等
- get:从数据集中检索单个项,并带有只返回该项的一部分的选项。 Get (idx)与[idx]相同,不支持切片
def get(self, idx, offset=0, length=None): ptr, size = self._index[idx] if length is None: length = size - offset ptr += offset * np.dtype(self._index.dtype).itemsize np_array = np.frombuffer(self._bin_buffer, dtype=self._index.dtype, count=length, offset=ptr) return np_array- frombuffer:将缓冲区转化为为一维数组
get_train_valid_test_split_:从逗号或’/’分隔的字符串列表,获取数据集split
build_dataset:EncDecDataset 数据集处理
- _build_index_mappings
CPM-2-Pretrain模型
CPM-2: Large-scale Cost-effective Pre-trained Language Models
AI Open会议,清华大学计算所,pre-trained language models
代码:https://github.com/TsinghuaAI/CPM-2-Pretrain
背景及问题:训练更大的模型是深度学习的一个重要研究方向,近年来,预训练已成为开发大规模神经网络的主流技术。预训练语言模型(PLMs)的规模突飞猛进,这些大规模plm的效率问题限制了它们在现实场景中的使用
- 预训练:其做法一般是将大量低成本收集的训练数据放在一起,经过某种预训方法去学习其中的共性,然后将其中的共性“移植”到特定任务的模型中,再使用相关特定领域的少量标注数据进行“微调”,这样的话,模型只需要从”共性“出发,去“学习”该特定任务的“特殊”部分即可
- 使用 PLM 的成本随着模型大小的增长而迅速增加,并且对于大多数用户和研究人员来说变得无法承受。主要成本包括:
- 预训练计算量大:超大型模型需要数周的数千个 GPU 的预训练
- 微调模型的存储成本大:超大模型通常需要数百 GB 来存储,我们需要存储与下游任务一样多的模型
- 推理设备要求高:超大型模型推理通常需要多块GPU,计算资源有限,难以使用这些模型
优化措施
- 使用knowledge inheritance方法(知识继承):是利用现有PLM的知识来帮助新模型的预训练
- 使用prompt tuning (提示调优)而不是微调fine-tuning 来减少特定于任务的参数的存储
- 设计了一个高性能、内存高效的推理框架INFMOE,并采用了动态调度的卸载策略
设计:CPM-2-Pretrain
基于优化后的PLM流程,开发了两种大规模成本-高效的预训练语言模型(Cost-efficient Pre-trained language Models, CPM-2),一种是包含110亿个参数的中英双语模型,另一种是包含198亿个参数的专家混合模型 Mixture-of-Experts (MoE)
模型:由双向编码器和单向解码器组成的标准Transformer架构
背景:加入Attention机制的Seq2seq模型(Encoder–Decoder 结构)在各个任务上都有了提升,现在的seq2seq模型指的都是结合RNN和attention的模型
google提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩
编码/解码器:a variant of Masked Language Model (MLM)
并行训练:将attentiom和前向层沿宽度维度(width dimension)进行划分,最后将一个模型的分区分布在4个gpu上
为了减少内存需求和加快训练前的速度,我们使用mixed-precision training、gradient checkpointing和ZERO-stage-1
对于CPM-2-MoE,将每个Transformer块的前馈层扩展到多个experts 。在向前传递过程中,对于每个token ,根据其当前隐藏状态选择一个具有门控功能的experts。另外使用BASE的规划方法来平衡experts 选择层
- 背景:多专家模型Mixture-of-Experts,MOE,略
数据处理:分词,清洗,标准化,特征提取,建模
- 通过sentencepiece 方法减少句子冗余
- sentencepiece 分词器会在分词序列中插入许多多余的空白标记“_”,这使得序列变得更长。使用WoBERT 的方法,我们用一个简单的前缀匹配替换了句子标记器,并删除了空白插入。新实现的分词器比句子分词器更有效、更易于使用
Pre-Training with Knowledge Inheritance
- 三阶段:Chinese pre-training, bilingual(双语) pre-training, and MoE pre-training
- 与从头开始的训练模型相比,具有知识继承的多阶段训练可以显著降低计算成本
- Chinese pre-training:只使用中文文本作为训练数据。该模型可以集中学习汉语信息,具有很好的推广到其他语言的基础
- bilingual pre-training:在这一阶段,进一步从中文阶段对模型进行预训练中英文文本。优化包括前缀初始化,英中1:2
- MoE pre-training :多次复制双语阶段的模型来初始化MoE模型。对于门控网络,采用随机投影作为局部敏感哈希函数,在这一阶段不更新门控网络
INFMOE: Memory-Efficient Inference Framework for MoE Layer
- PyTorch和TensorFlow是工业和学术界广泛使用的深度学习框架,用于训练和推理。还有许多其他框架,比如TensorRT和ONNX Runtime,它们是专门为不同设备上的高效模型推理而设计的。但由于各种原因,目前还不适合对MoE层进行有效的推理
- https://github.com/TsinghuaAI/InfMoE
第二代NLP/SenseLM训练框架
- Transfer Learning in NLP
运行配置
测试环境:1424集群
- 模型文件夹:/mnt/cache/ladata/yangdong1/models,可以在里面找模型。
- TFDS数据集文件夹:export TFDS_DATA_DIR=/mnt/cache/ladata/yangdong1/tensorflow_datasets,理论上有了它就不用联网了。当然实际加载数据还是按照 FLAN 的 seqio 任务名来的。
- 加完 prompt 的数据集缓存文件夹:/mnt/cache/ladata/yangdong1/cache,可以极大提升预处理速度。现在已经预处理了所有能下载到的 FLAN 数据。
- 1424 集群未联网,t5 库会强制用到 tf.io.gfile 导致 T5 tokenizer 无法加载。我们只需要把 t5 库中的 t5.data.util.py 中的 DEFAULT_SPM_PATH 改成缓存过的 <本仓库路径>/tokenizer_xxl/spiece.model 即可
运行脚本
python -m torch.distributed.launch --nnodes ${NUM_WORKERS} --node_rank ${NODE_RANK} --nproc_per_node ${NUM_GPUS_PER_WORKER} --master_addr ${MASTER_ADDR} --master_port ${MASTER_PORT} run.py --deepspeed experiments/${SLURM_JOBID}/deepspeed_config.json --model_name_or_path ./models --per_device_train_batch_size 16 --per_device_eval_batch_size 32 --output_dir experiments/${SLURM_JOBID}/model --learning_rate 0.001 --lr constant --max_source_length 1024 --max_target_length 256 --do_train --do_eval --num_train_epochs 100 --max_steps 50000 --dataset_name glue_mix.flan --save strategy steps --save_steps 500 --save_total_limit 1 --gradient_checkpointing true --gradient_accumulation_steps 8 --logging_steps 8 --eval_steps 1000 --evaluation_strategy steps --max_eval_samples 10240 --overwrite_output_dir True
代码分析
主要建立在 Huggingface/ transformers
- 使用 DeepSpeed 进行分布式训练
- 基于seqio的IO和评价框架。支持在不同的数据集及其混合物上进行预训练/微调模型,并在各种基准上进行评估,例如GLUE、SuperGLUE、CLUE(WIP)等
以 Huggingface 格式加载/训练/保存语言模型
- Prompt tuning & transfer
- Finetuned Language Models Are Zero-Shot Learners,ICLR‘22,Google Research
- 微调语言网络 (fine-tuned language net, FLAN)
- Multitask prompted training enables zero-shot task generalization,Huggingface
- Finetuned Language Models Are Zero-Shot Learners,ICLR‘22,Google Research
- 主要流程
- get_split:数据集的读取和处理
数据集
- 统一NLP数据集text-to-text格式,使用tensorflow_datasets和seqio框架以基于任务的方式处理数据集,统一了预处理、后处理和自动计算
- 任务Tasks
- T5-style数据集: super_glue_cb_v102, starts with the name of the task, followed by concatenating the inputs)
- FLAN指令调优数据集:an instruction prompt style (describe the task in natural instructions, and concatenate the inputs in natural language).
- 混合数据:定义了几个数据集混合,将相似的任务聚合在一起进行训练
SuperGLUE 基准测试
训练主流程:于Huggingface/ transformers一致,参考transformers文档
- ModelArguments,DataTrainingArguments,Seq2SeqTrainingArguments
数据模块:
- seqio: IO & evaluation framework,用于训练和评测数据集
- Load/Train/Save Language models in Huggingface format,用于模型
- The tokenizer is responsible for all the preprocessing the pretrained model expects, and can be called directly on a single string (as in the above examples) or a list. It will output a dictionary that you can use in downstream code or simply directly pass to your model using the ** argument unpacking operator.
- 负责预训练模型中所有预处理,并且可以直接在单个字符串或列表上调用
- 输出一个字典,可以在下游代码中使用该字典,或者使用 参数解包运算符直接传递给模型
- tokenizer,return_tensors支持 “pt” 或者 “tf”
- The model itself is a regular Pytorch nn.Module or a TensorFlow tf.keras.Model (depending on your backend) which you can use normally. This tutorial explains how to integrate such a model into a classic PyTorch or TensorFlow training loop, or how to use our Trainer API to quickly fine-tune on a new dataset.
- The tokenizer is responsible for all the preprocessing the pretrained model expects, and can be called directly on a single string (as in the above examples) or a list. It will output a dictionary that you can use in downstream code or simply directly pass to your model using the ** argument unpacking operator.
知识补充—NLP模型发展
榜单
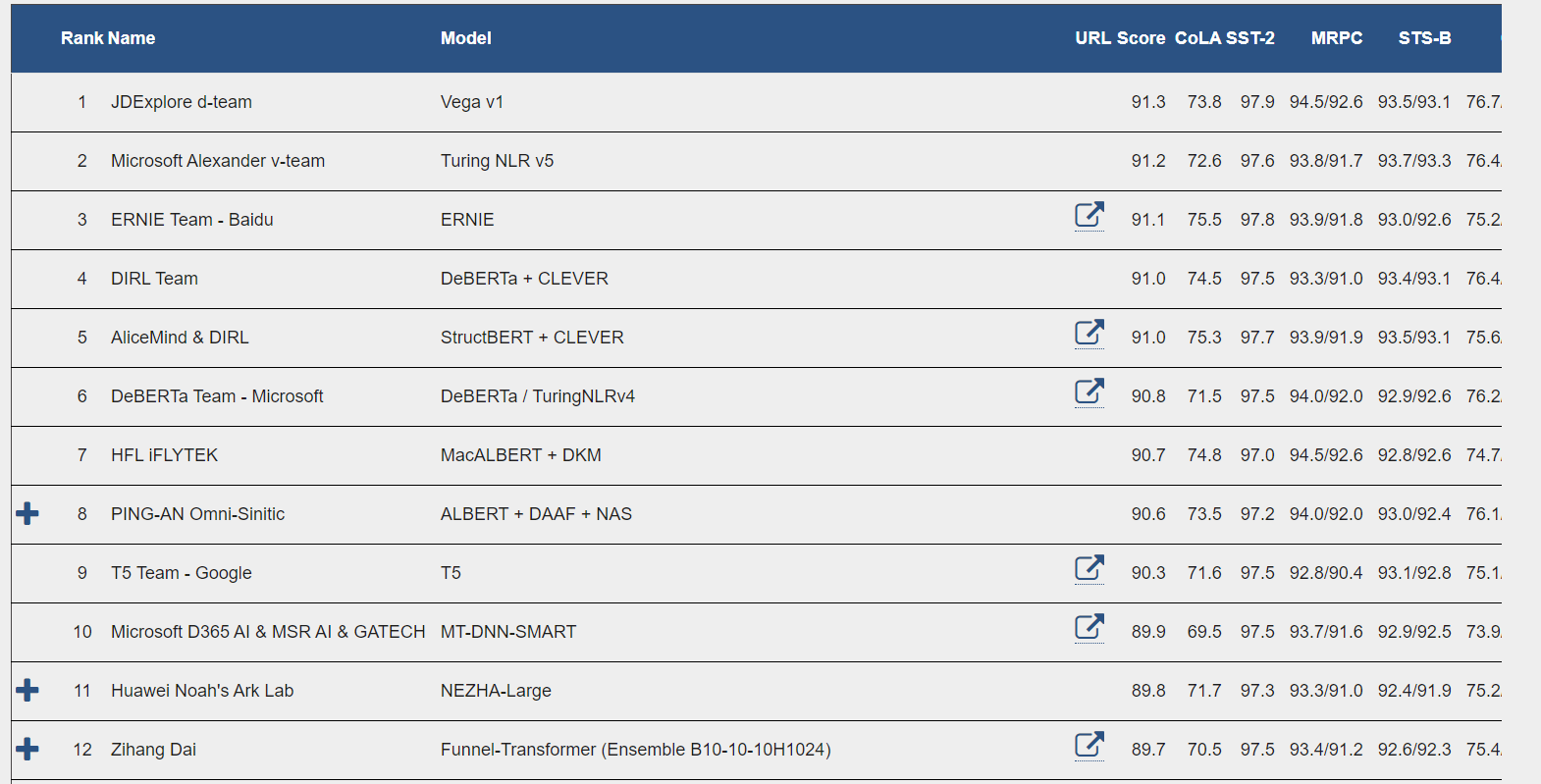
https://gluebenchmark.com/leaderboard,通用语言理解评估(GLUE)基准中的 11 项任务
https://paperswithcode.com/sota/question-answering-on-squad11,SQuAD1.1数据集
https://sites.research.google/xtreme
JDExplore Dream Team,京东探索研究院联合悉尼大学、武汉大学以及北京航空航天大学
- vega v1:采用了“预训练-微调”范式,依托于多个重要预训练的技术创新实现突破,例如采用了高效节能的并行化训练框架以及数据利用方法,使用了数十亿参数量的创新模型架构、更好的自监督信号以及多粒度句子级表征等
- Microsoft Turing 和 Microsoft Research : T-ULRv5
- 3、百度:ERNIE;4、DIRL;5、阿里达摩院 & DIRL;6、Microsoft ;7、HFL 科大讯飞;8、平安科技;9、谷歌T5;10、Microsoft ;11、华为诺亚方舟;12、谷歌研究院Zihang Dai…
研究范式
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing, 46页
- CMU,刘鹏飞
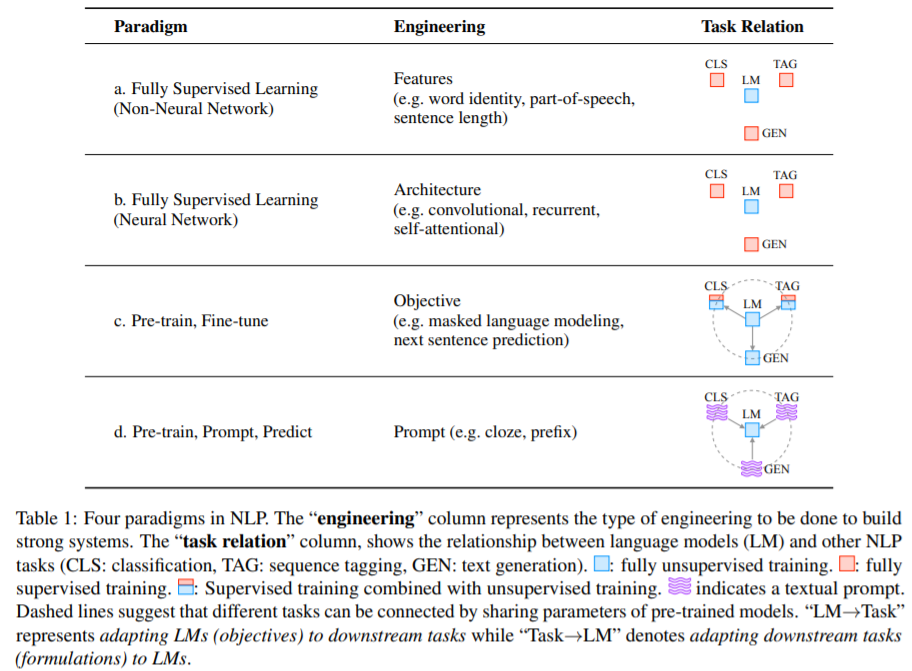
- 第一范式[有监督机器学习]:2011-2013 年之前,主要以特征工程+有监督机器学习为主
- 研究者把基于全监督学习的不涉及神经网络的机器学习模型方法当作最早的自然语言处理研究范式。许多经典的机器学习模型在自然语言处理领域取得了广泛而有效的应用,比如决策树、逻辑回归、支持向量机等模型用于情感分析、垃圾邮件识别、主题分类等文本分类问题。机器学习模型又根据对数据集和标签之间关系的看法不同,分为生成模型和判别模型。生成模型研究的是数据集和标签之间的联合概率分布,比如简单贝叶斯模型;而判别模型把标签看作给定数据集的条件概览进行预测,比如最大熵模型、条件随机场、支持向量机等
- 在机器学习模型的范式下,为了得到有效的自然语言处理模型,特征工程起到了很大的作用。研究者需要从原始数据中选取合适的特征来表征数据对象,从而让模型可以从有限的数据中学习到有用的信息。特征的定义需要用到领域知识,因此特征工程是一项需要人工参与的工作
第二范式[神经网络模型]:2011-2013 年,随着神经网络在 NLP 领域的突破(Embedding),NLP 开始进入架构工程,好的架构可以学到更好的特征
- 通过训练不同架构的神经网络模型可以解决分类、序列标注、生成等许多自然语言处理任务。此时,我们不需要再人工选择特征,因为神经网络模型可以在训练过程中自己学习到特征,此时工程层面的重点由特征工程转为架构工程,人需要选择神经网络模型层次的架构,要考虑诸如卷积、递归、自注意等不同神经网络层之间的组合
- 第三范式[预训练、微调 / pre-train, fine-tune]:2017-2019 年,随着基于大规模生语料的预训练语言模型的出现,自然语言处理的研究逐渐转变为“预训练+微调”范式,即将PLM应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对PLM本体进行调整。进入目标工程,重点在于如何设计预训练和微调阶段的目标函数
- 在该范式下,首先要有通过针对大量语料进行不同预训练任务的训练而得的语言模型。标准语言模型可以通过前文预测下一个单词的概览,进而预测一段文本的概览,通过使一段来自语料库文本中的语段被预测的概览最大化,可实现对语言模型的训练。这种情况下,语言模型的训练基本是通过“自回归”的方式预测的,即每次预测一段文本中的一个词,通常预测顺序是从左向右的
- 除此之外,语言模型还可以通过对输入文本设置干扰,然后通过预测给定干扰文本的原始文本来的条件概率进行训练,比如通过设置掩码来设计预训练任务的BERT模型。设置干扰的方式除了有BERT用到的设置掩码的方式,还有替代、删除、顺序重排、句子串联等操作
- 在“预训练+微调”范式中,语言模型的结构是在预训练阶段就已经确定下来的,通过将不同的预训练任务在大量语料上训练,语言模型本身对语言有一定的“理解”甚至“生成”能力。当然,这种所谓的“理解”能力只是指语言模型可以对所观测到的文本数据的概率进行预测,离语言认知层面的“理解”还有很大差距。通过对加入一些额外的参数,可以把预训练的语言模型应用到不同的下游任务中,并且根据具体的任务设置目标函数,对整个模型的参数进行微调
- 在该范式中,需要人为参与的重点是目标函数的设计与选择,在语言模型的预训练阶段和微调阶段,都需要考虑如何设计和选择目标函数。目标函数是根据具体的预训练任务和下游任务来确定的。因此,在这一阶段,目标函数工程是起到至关重要作用的。此外,“预训练+微调”范式的预训练阶段采用的是无监督学习模式,在针对不同下游任务的微调阶段,采用的仍是监督学习模式
- 第四范式[预训练、提示和预测 / pre-train, prompt, predict **]:2021 年开始,随着提示学习 Prompt learning 在NLP中运用,预训练+Prompt+预测成为新宠,进入提示工程**。在这种范式中,不是通过目标工程使预先训练的 LM 适应下游任务,而是重新制定下游任务,使其看起来更像是在 Prompt 的帮助下在原始 LM 训练期间解决的任务
- 在该范式下,不再通过微调把预训练模型应用于下游任务,而是认为语言模型在大规模语料的训练学已经学习到了足够多的内容来解决下游任务,而我们要做的是通过设计文本的“提示”,来帮助语言模型理解下游任务的要求。换句话说,我们通过对下游任务进行形式改造,让它看起来更像语言模型在预训练阶段完成过的任务
- 比如,在进行情感识别的任务时,给出一段社交媒体文本来预测情感标签。比如输入文本为“我今天又没赶上公交。”我们通过在这段输入文本后面添加一段提示文本“我感到十分____。”,让语言模型来预测横线部分的词。这样,我们就把一个分类任务转换成了一个语言模型在预训练阶段就见到过的任务。同样的,我们也可以用相似的办法把机器翻译任务转变为类似的形式,比如输入文本依然为“我今天又没赶上公交。”,下游任务是把它翻译成英语,即让模型返回一段英语输出文本。可以设计一个提示“Chinese: 我今天又没赶上公交。English: _________”,让语言模型用对应的英语翻译来填充横线部分。通过设计合适的提示,我们可以改变语言模型的行为,从而让语言模型在没有下游任务训练的情况下自身就可以产生正确的输出
- “提示学习”方法的优势是可以在给定一系列合适提示的条件下,完全通过无监督学习训练而得的语言模型就可以用了解决大量的下游任务,这样就可以实现少样本甚至零样本学习。很显然,在该范式下,需要人工参与的工程部分是提示工程,即设计最合适的提示让语言模型可以理解要解决的任务
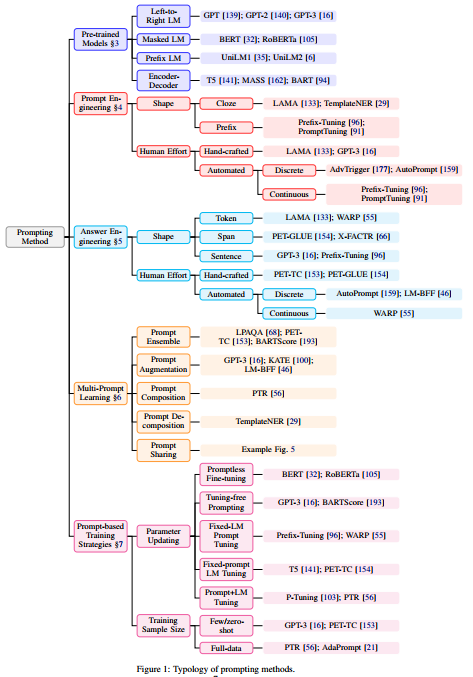
Prompt扩展:迁移Prompt,Multi-Prompt Learning
模型优化
重点模型:Seq2seq、Transformer、ELMo、GPT系列、BERT、RoBERTa、Megatron、T5、Tuning
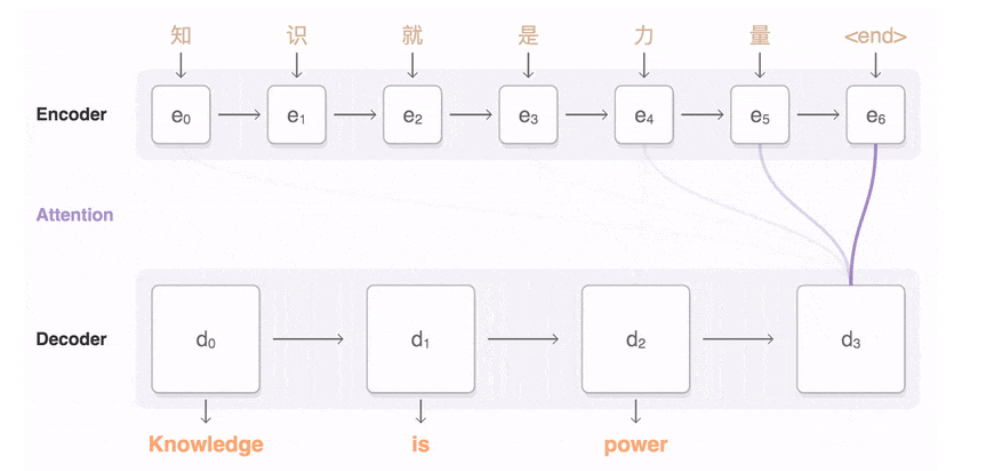
Encoder–Decoder 和 Seq2seq架构:最常见的编码解码框架,Seq2seq加入Attention机制在各个任务上都有了提升,现在的seq2seq模型指的都是结合RNN和attention的模型
- Sequence to Sequence Learning with Neural Networks,NeurIPS’14,google
基于cnn和lstm框架:第二范式
- 代表:ESIM、BiMPM、DIIN、Cafe、QANet和DrQA等
- 主题模型、条件随机场、词向量、Gated RNN、CNN、RNN-based seq2seq、非RNN的seq2seq
- 发展方向:神经网络调参优化,修仙拜佛,陷入发展瓶颈
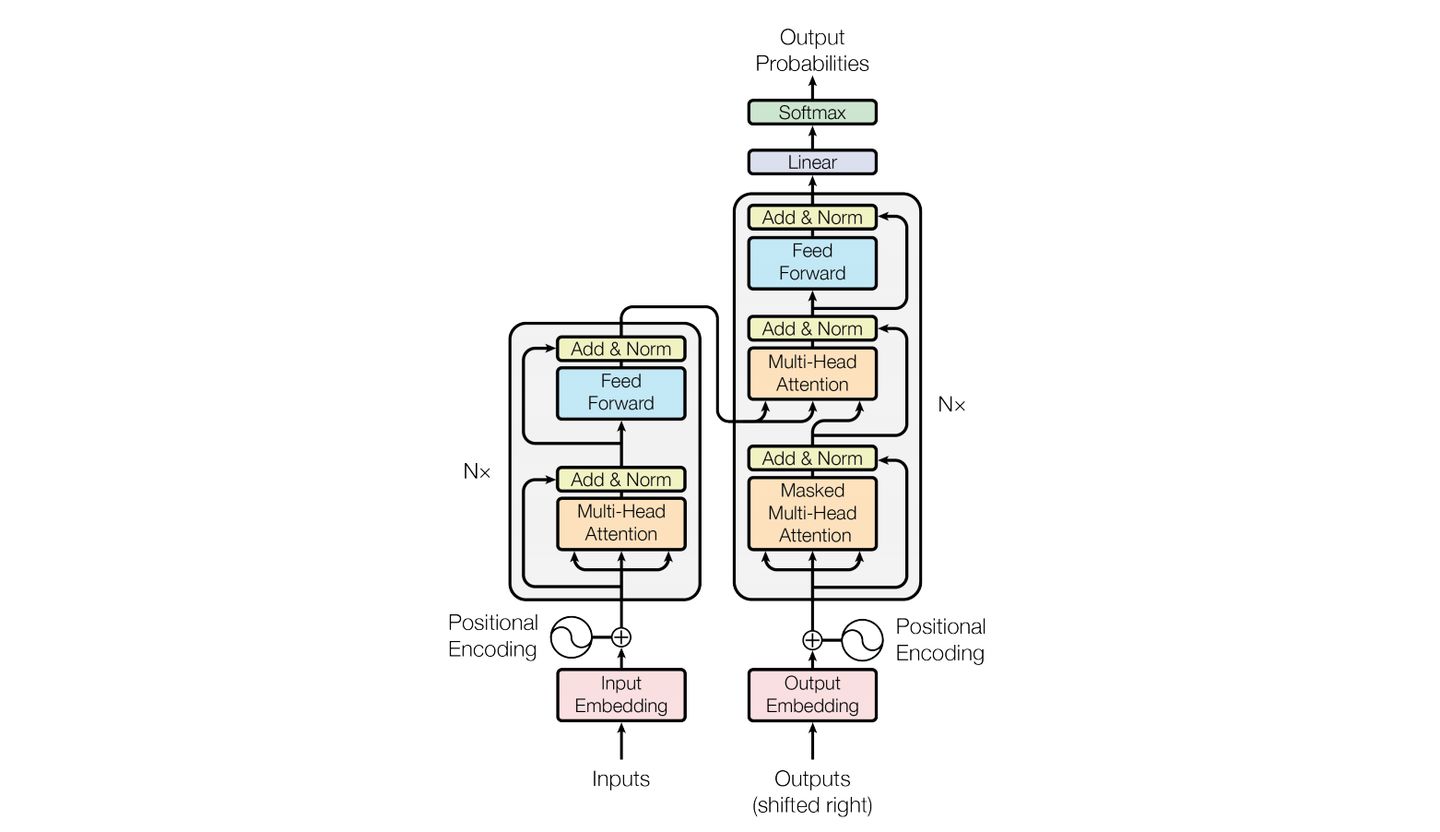
Transformer模型:非RNN的seq2seq代表,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩
- Attention Is All You Need,NeurIPS’17,google
ELMo:预训练词向量,开始使用预训练模型
- Deep contextualized word representations,2018,华盛顿大学
OpenAI GPT(Generative Pre-Training)系列:只有pre-training,由OpenAI提出的非常强大的预训练语言模型,介绍https://zhuanlan.zhihu.com/p/350017443
- GPT-1:无监督学习,Improving Language Understanding by Generative Pre-Training,2018
- GPT-2:多任务学习,Language Models are Unsupervised Multitask Learners,2019
- GPT-3:海量参数,Language Models are Few-Shot Learners,NeurIPS’20
模型 发布时间 参数量 预训练数据量 GPT 2018 年 6 月 1.17 亿 约 5GB GPT-2 2019 年 2 月 15 亿 40GB GPT-3 2020 年 5 月 1,750 亿 45TB Bert 2018年 1亿 / 3亿 13GB BERT模型:第三范式代表,google
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,ACL’18 best paper,google
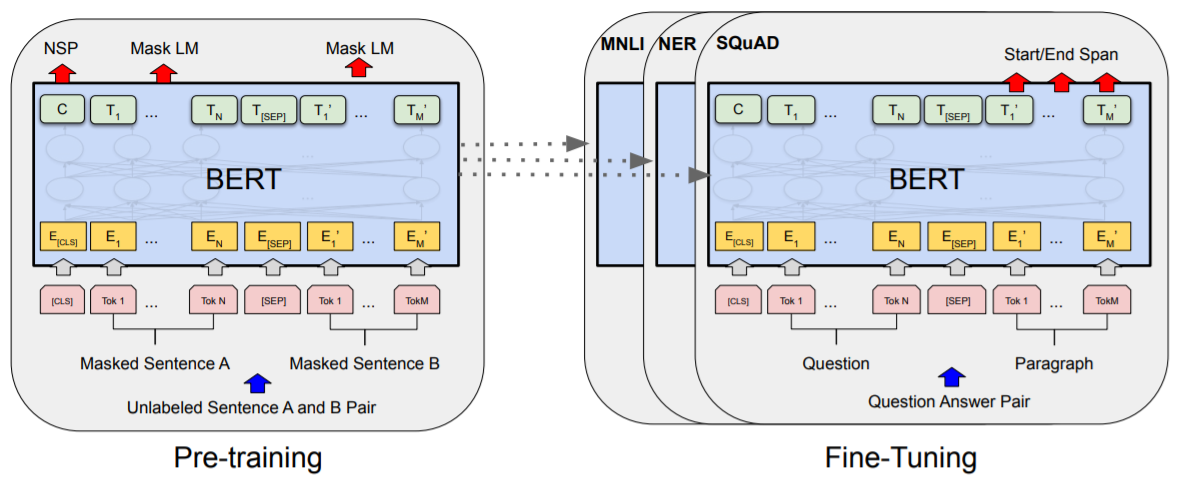
- 更多的数据与更长的训练:OpenAI当时训练GPT用了将近1个月的时间,而如果用同等的硬件条件来训练BERT估计需要1年的时间。google用了16个自己的TPU集群(一共64块TPU)来训练大号版本的BERT,一共花了4天的时间
Bert的优化:RoBERTa、XLNet、UniLM
- RoBERTa: A Robustly Optimized BERT Pretraining Approach,Facebook
- Xlnet:generalized autoregressive pretraining for language understanding,NeurIPS’19,CMU && google,Zihang Dai
- UniLM: Unified Language Model Pre-training for Natural Language Understanding and Generation, NeurIPS’19, Microsoft
T5:google,把所有的NLP问题都可以定义成“text-to-text”问题,即“输入text,输出text,一个模型干所有”。贡献了个语料库C4(Colossal Clean Crawled Corpus),750GB
Megatron系列,威震天,NVIDIA
- 分布式训练Megatron-LM框架: Training Multi-Billion Parameter Language Models Using Model Parallelism,2019
3D 并行系统:基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行,可复现GPT-3
Turing-NLG 和 MT-NLG:Microsoft && NVIDIA
- Turing-NLG,170亿参数,2020
- 使用DeepSpeed(分布式训练,ZeRO拆和卸载),Megatron技术
- [SC ‘21] ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- [ATC ‘21] ZeRO-Offload: Democratizing Billion-Scale Model Training
- [SC ‘20] ZeRO: Memory Optimizations toward Training Trillion Parameter Models
- 使用DeepSpeed(分布式训练,ZeRO拆和卸载),Megatron技术
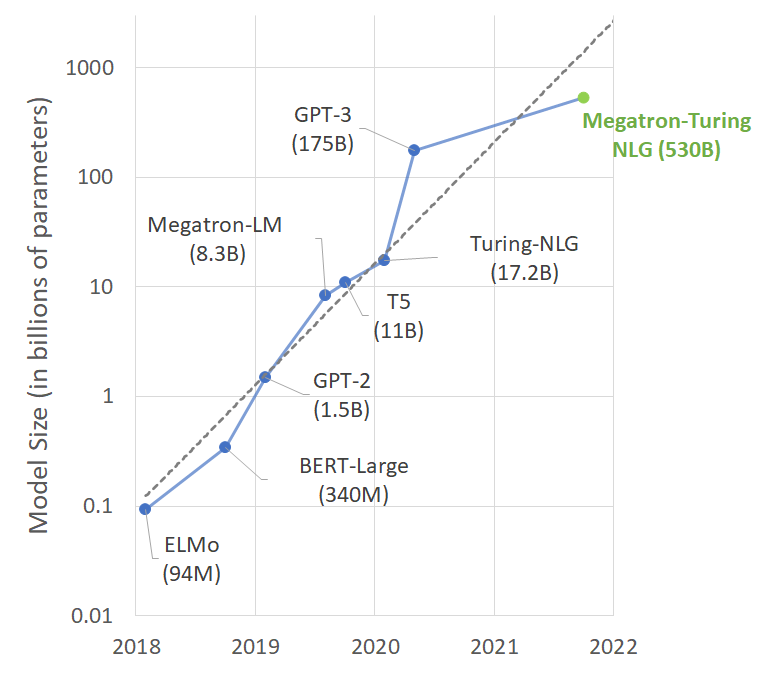
- MT-NLG,5300亿参数,2021
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
- 迄今为止训练的最大和最强大的单片 Transformer 语言模型,具有 5300 亿个参数,是GPT-3的3倍
- 软件系统: NVIDIA Megatron-LM和 Microsoft DeepSpeed,创建了一个高效且可扩展的 3D 并行系统
- 硬件系统:模型训练是在基于英伟达 DGX SuperPOD 的 Selene 超级计算机上以混合精度完成的。这台超级计算机由 560 个 DGX A100 服务器构建而成,采用完整的胖树拓扑(FatTree)加 HDR InfiniBand 联网配置。每个 DGX A100 包含 8 个英伟达 A100 80GB Tensor Core GPU,通过 NVLink 与 NVSwitch 实现完全互连。微软也在 Azure NDv4 云超级计算机中采用了类似的参考架构。
- 研究人员分别在 Selene 上使用 280、350 以及 420 台 DGX A100 服务器试验批次大小为 1920 的 5300 亿参数模型的端到端吞吐量,并观察到其迭代时间分别为 60.1 秒、50.2 秒以及 44.4 秒;这些结果各自对应每 GPU 每秒 126、121 以及 113 万亿次计算
- Turing-NLG,170亿参数,2020
- GPT-3:使用prompt ,第四范式,OpenAI
- Language Models are Few-Shot Learners,NeurIPS’20,31个作者
- 最大的创新是可以用 prompt 直接前向做下游任务,从而不引进新的参数,本质是通过挖掘预训练语言模型的知识做下游任务
- 第四范式的发展:那么如何用较小的预训练模型充分发挥预训练语言模型作为语言模型的作用,做下游任务
- 最新论文列表: https://github.com/thunlp/PromptPapers
- FLAN:微调语言网络 (fine-tuned language net),多任务的Prompt、指令泛化,Google
- Finetuned Language Models Are Zero-Shot Learners,ICLR‘22,Google Research
- Prompt tuning都是针对一个任务的,比如做个情感分析任务的prompt tuning,精调完的模型只能用于情感分析任务,
- Instruction Tuning:多任务精调,可以用于其他任务的zero-shot
- 贡献FLAN指令调优数据集
- Multitask prompted training enables zero-shot task generalization
- Huggingface / Transformers 开源框架,Huggingface(抱抱脸)一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏
知识补充—分布式训练发展
Megatron学习
doing
DeepSpeed学习
doing
语料库及其使用
- https://gitlab.bj.sensetime.com/nlp/SenseLM
- 语料库基于seqio格式分为两种,task,mix
- 任务:T5 datasets,FLAN instruction tuning datasets
- 混合数据集:几个数据集混合,将相似的任务聚合在一起进行训练
数据集
- SuperGLUE Tasks:AX-b,AX-g,BoolQ,CB,COPA,MultiRC,ReCoRD,RTE,Wsc,Wic
- GLUE Tasks:glue_mrpc,glue_qqp,CoLA,MNLI,QNLI,WNLI,SST2,STSB
- WSC273,Natural Questions,trivia_qa,Arc,Math Dataset,aeslc,CoQA,samsum,dart,true_case,fix_punct,SNLI,TREC,PIQA,OpenbookQA,Hellaswag
T5格式
SGLUE_T5_TASKS = [ "super_glue_boolq_v102", "super_glue_cb_v102", "super_glue_copa_v102", "super_glue_multirc_v102", "super_glue_record_v102", "super_glue_rte_v102", "super_glue_wic_v102", "super_glue_wsc_v102_simple_eval", ]FLAN格式
"sglue_prompted_mix" "sglue_noisy_prompted_mix" "sglue_dpr_prompted_mix" "sglue_dpr_wsc_prompted_mix"混合数据集
- "glue_mix" : ... - "ft_squad_mix": ... - "ft_paraphrase_similarity_mix": ... - "ft_sentiment_mix": ... - "ft_closedbook_qa_mix": ... - "ft_translation_mix": ... - "ft_summarization_mix": ...数据集的使用 SeqIO,google
SeqIO: Task-based datasets, preprocessing, and evaluation for sequence models
并非Biopython,Bio.SeqIO从文件读取序列和向文件写入序列SeqIO:支持在各种数据集及其混合集上预训练/微调模型,并在各种基准上进行评估,例如 GLUE、SuperGLUE、CLUE(WIP) 等
- 定义一个
Task(和可选的一个Mixture) - 使用
FeatureConverter定义模型架构(或使用现有的) - 使用函数
seqio.get_dataset获取tf.data.Dataset实例
- 定义一个
使用
seqio.TaskRegistry.add创建Task,Task包含:- a raw data source
- one or more preprocessing steps
- a vocabulary to tokenize/detokenize each preprocessed feature for the model
- a postprocessor to convert detokenized model outputs into a format for evaluation
- one or more metrics to evaluate with
Task in huggingface/transformers
- task创建
# Task names: # Zero-shot version: f'{t_name}_type_{idx}' # One-shot version: f'{t_name}_type_{idx}_one_shot' # Multi-shot version: f'{t_name}_type_{idx}_multi_shot' # Zero-shot version of the task. zero_shot_task_name = utils.ZeroshotEvalTaskName.get(t_name, idx) seqio.TaskRegistry.add( zero_shot_task_name, source=config.source, preprocessors=config.preprocessors + # Format inputs and outputs according to the patterns. This should be # the same for all tasks. preprocessors.get_flan_formatter(inputs_pattern, targets_pattern) + # Tokenization for the prefix-LM. This should be the same for all tasks. preprocessors.FLAN_TOKENIZE, postprocess_fn=config.postprocess_fn, output_features=FLAN_OUTPUT_FEATURES, metric_fns=config.metric_fns)- data source
# =============================== BoolQ ======================================== @seqio.map_over_dataset def _process_boolq(example): one_hot = tf.one_hot(tf.cast(tf.math.maximum(example['label'], tf.zeros((), dtype=tf.int64)), tf.int32), 2) options = tf.constant(['no', 'yes']) return { 'title': example['idx'], 'idx': example['idx'], 'text': example['passage'], 'question': example['question'], 'options': options, 'answer': tf.boolean_mask(options, one_hot)[0], } TASK_CONFIGS['bool_q'] = _TaskConfig( source=seqio.TfdsDataSource( tfds_name='super_glue/boolq:1.0.2', splits={ 'train': f'train', 'validation': f'validation', 'test': 'test', }), preprocessors=[ _process_boolq, preprocessors.format_options, ], postprocess_fn=None, metric_fns=glue_utils.get_super_glue_metric('boolq'), )- 数据源:seqio定义
dataset_provider类将多种格式的原始数据加载为tf.data.Dataset,现有的实现包括:TfdsDataSource:用于从TensorFlow Datasets加载TextLineDataSource:用于从文本文件(例如 tsv)加载TFExampleDataSource:用于从文件(例如FRecord文件)加载FunctionDataSource:用于提供一个自定义函数,该函数返回tf.data.Dataset
- 使用
seqio.get_mixture_or_task(mixture_or_task_name)访问registry得到dataset_provider,然后调用get_dataset构建tf.data.Dataset
train_dataset_provider = seqio.get_mixture_or_task(data_args.dataset_name) eval_dataset_provider = seqio.get_mixture_or_task(data_args.eval_dataset_name) raw_datasets = { 'train': get_split(train_dataset_provider, "train"), 'validation': get_split(eval_dataset_provider, 'validation'), 'test': get_split(eval_dataset_provider, 'test'), }get_split函数使用get_dataset
def get_split(provider, split_name, shard=False): arg_dict = {} if isinstance(provider, seqio.Mixture): arg_dict["copy_pretokenized"] = True not_cached = [t.name for t in provider.tasks if t.cache_dir is None] arg_dict["use_cached"] = len(not_cached) == 0 if not_cached and is_master: logger.warning(f"The following tasks are not cached: {not_cached}") else: arg_dict["use_cached"] = provider.cache_dir is not None if provider.cache_dir is None: logger.warning(f"The following tasks are not cached: {provider.name}") if shard and training_args.local_rank != -1: # is distributed training arg_dict["shard_info"] = seqio.ShardInfo(index=torch.distributed.get_rank(), num_shards=torch.distributed.get_world_size()) ds = provider.get_dataset( sequence_length={"inputs": data_args.max_source_length, "targets": data_args.max_target_length}, split=split_name, shuffle=False, num_epochs=int(training_args.num_train_epochs) if split_name == 'train' else 1, **arg_dict ) return ds.shuffle(training_args.seed) if split_name == 'train' else dsget_dataset&&tfds_dataset.load
def get_dataset( self, split: str, shuffle: bool = True, seed: Optional[int] = None, shard_info: Optional[ShardInfo] = None ) -> tf.data.Dataset: return self.tfds_dataset.load( split, shuffle_files=shuffle, seed=seed, shard_info=shard_info)- 默认是从
download: bool = True从网上下载,但是可以设置目录data_dir- TFDS数据集文件夹:
export TFDS_DATA_DIR=/mnt/cache/ladata/yangdong1/tensorflow_datasets - https://www.tensorflow.org/datasets
- TFDS数据集文件夹:
使用
seqio.MixtureRegistry.add函数创建混合任务Mixture- 略
检索数据库
- NLP目标
- 设计高效数据库构建方式,支持几T至几百T的检索数据库
- 设计高速检索策略,支持模型训练时高频读取数据库
Retro 具体实现
- 对数据库的操作:Nearest neighbour retrieval,NN
- KNN,近似K最近邻搜索Approximate K-Nearest Neighbor Search
- ScaNN 库

- 数据库规模:Wikipedia 215G,MassiveText 93TB

- 网上的一个开源实现,https://github.com/lucidrains/RETRO-pytorch
- using rotary embeddings for relative positional encoding, as well as Faiss library instead of Scann.
- RoFormer: Enhanced Transformer with Rotary Position Embedding,追忆科技,为Transformer结构设计了新的旋转式位置编码(Rotary Position Embedding,RoPE)
- Autofaiss 库搭建KNN 索引
- 训练中对数据库的操作
text_folder_to_chunks_:text转成chunks
chunks_shape = (max_chunks, chunk_size + 1) seqs_shape = (max_seqs,) doc_ids_shape = (max_chunks,) with memmap(chunks_memmap_path, shape = chunks_shape, dtype = np.int32, mode = 'w+') as chunks_memmap\ , memmap(seqs_memmap_path, shape = seqs_shape, dtype = np.int32, mode = 'w+') as seqs_memmap\ , memmap(doc_ids_memmap_path, shape = doc_ids_shape, dtype = np.int32, mode = 'w+') as doc_ids_memmap: for path in paths: print(f'processing {path}') chunks, seq = doc_text_to_chunks_and_seq_indices( doc_text = path.read_text(), chunk_size = chunk_size, seq_len = seq_len ) doc_chunk_len = chunks.shape[0] doc_seq_len = seq.shape[0] chunks_memmap[total_chunks:(total_chunks + doc_chunk_len)] = chunks.numpy() seqs_memmap[total_seqs:(total_seqs + doc_seq_len)] = seq.numpy() + total_chunks doc_ids_memmap[total_chunks:(total_chunks + doc_chunk_len)] = np.full((doc_chunk_len,), total_docs) total_chunks += doc_chunk_len total_seqs += doc_seq_len total_docs += 1 return dict( chunks = total_chunks, docs = total_docs, seqs = total_seqschunks_to_precalculated_knn_:计算KNN memmap路径,得到faiss索引knn_chunks_from_seq_chunks:检索查找目标块
- using rotary embeddings for relative positional encoding, as well as Faiss library instead of Scann.
最近邻搜索(Nearest Neighbor Search)https://leovan.me/cn/2020/08/nearest-neighbor-search/
- 是指在一个确定的距离度量和一个搜索空间内寻找与给定查询项距离最小的元素。更精确地,对于一个包含 N 个元素的集合 X={x1,x2,⋯,xn},给定查询项 q 的最近邻 NN(q)=argmin dist(q,x),其中 dist(q,x) 为 q 和 x 之间的距离。由于[维数灾难,我们很难在高维欧式空间中以较小的代价找到精确的最近邻。近似最近邻搜索(Approximate Nearest Neighbor Search)则是一种通过牺牲精度来换取时间和空间的方式从大量样本中获取最近邻的方法。
- 精确搜索:Brute-force Search,暴力搜索;k-Dimesion Tree,k-D Tree;Ball 树
- 近似搜索
- 基于hash:局部敏感哈希(Local Sensitive Hash, LSH),哈希学习(Learning to Hash, L2H)等
- 矢量量化(Vector Quantization):矢量量化以乘积量化(Product Quantization,PQ),IVFADC,QPQ
- 基于图:NSW(Navigable Small World),HNSW(Hierarchical Navigable Small World),HNSW(Hierarchical Navigable Small World)
Faiss库,Facebook AI,https://github.com/facebookresearch/faiss
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。Faiss用C++编写,并提供与Numpy完美衔接的Python接口
Autofaiss 库:使用Faiss高效索引、二分搜索和启发式算法,Autofaiss 可以在 3 小时内在低内存量 (15 GB) 中自动构建大型(2 亿向量,1TB)KNN 索引,延迟为毫秒级(10 毫秒)
ScaNN 库,google,https://github.com/google-research/google-research/tree/master/scann
- 向量相似搜索库
思考:What can we do?
- 他们的工作也是正起步阶段,尚不明确要做成什么样子(Megatron-DeepSpeed,DeepSpeed尝试)
- 他们不知道做什么,也不知道要我们做什么,可能要一同研究
- 我们的工作不明确,后续计划?
- IO成为瓶颈?:分析流程,测试瓶颈
- 问题:数据集怎么办,他们代码随时会改
- 大模型并行训练和卸载?
- 问题:训练流程和方法尚不明确,要由他们主导
- Ceph / Lustre会影响性能:优化ceph/lustre的使用
- 问题:会不会用到Ceph/lustre?
- IO成为瓶颈?:分析流程,测试瓶颈