
Auto
ACSTS: Automatic Cloud Storage Tuning System using Reinforcement Learning
我必须考虑,这会不会是我此生仅有的机会 — 达纳德·许
主题
强化学习:ACSTS: Automatic Cloud Storage Tuning System using Reinforcement Learning
负载变化+迁移学习:ACSAT: Adaptive Cloud Storage Auto-Tuning System using Transfer Learning
AutoML中经验:Auto-of-Auto: Automatic Cloud Storage Tuning with AutoML
冲!
- 目标会议:DAC 2021,11/15,11/22
- 三部分 (10/29,还剩15~22天)
- Abstract + Introduce + Related Work:2页 (98%)
- 差abstract
- Design + Implementation:2页 (30%)
- 参数选择完成
- 写完代码,收敛困难
- 模型优化:分布式A3C?
- 学习:https://github.com/hibayesian/awesome-automl-papers
- 训练优化:?
分段式 + 参数复用- 分布式训练 + 状态机
- Evaluation + Conclusion + References:2页 (0%)
- Abstract + Introduce + Related Work:2页 (98%)
- NEXT:训练优化 + 创新思考
Abstract
Cloud storage systems with the immense number of configurations and unpredictable workloads pose higher requirements to configuration tuning. Traditional auto-tuning strategies expose great limitations in the face of these requirement, including local optimum, poor adaptability and evaluation pitfalls in evaluatio. In this paper, we present ACSTS, an automatic cloud storage tuning system based on deep reinforcement learning. ACSTS constructs Parameter Model to identifies important configuration parameters in high-dimensional continuous space. Besides, ACSTS utilizes Twin-Delayed Deep Deterministic Policy Gradient to find optimal configurations under dynamic workloads. Finally, ACSTS adopts a careful performance evaluation strategy to avoid pitfalls. ACSTS is implemented on Park and is used in the real-world system Ceph. The evaluation results show that ACSTS improves the performance of Ceph by 2x~2.5x.
Cloud storage systems with the immense number of configurations and unpredictable workloads pose higher requirements to configuration tuning. Traditional auto-tuning strategies expose great limitations in cloud environment, including local optimum, poor adaptability and evaluation pitfalls. In this paper, we present ACSTS, an automatic cloud storage tuning system based on deep reinforcement learning. ACSTS constructs Parameter Model to identifies important parameters in high-dimensional continuous space. Besides, ACSTS utilizes reinforcement learning to find optimal configurations under dynamic workloads. Finally, ACSTS adopts a careful performance evaluation strategy to avoid pitfalls. The results show that ACSTS can recommend optimal configurations and improve the performance.
ACSTS is implemented on Park and is used in the real-world system Ceph.
The evaluation results show that ACSTS improves the performance of Ceph by 2x~2.5x.
Introduce
- (云存储)
【背景】
云存储已经成为最广泛接受的基础设施服务之一,为存储大规模数据提供了成本效益高、高度可扩展和可靠的平台。随着数据的爆炸式增长,
云存储越来越复杂,不同负载不同应用
默认的配置参数往往不能保证集群资源的充分利用和系统的高吞吐率,因此需要调整参数配置从而提高系统在吞吐量、能耗、运行时间等方面的性能。
Default parameters cannot ensure full utilization of cluster resources or high throughput. Therefore, you need to adjust parameter Settings to improve system performance in terms of throughput, power consumption, and running time
这需要操作人员,费时费力,
Default settings provided by developers are often sub-optimal for specific user cases.
Auto-tuning with black-box optimization have shown promising results in recent years, thanks to its obliviousness to systems’ internals. 但是在云存储系统中,:
- 参数
Cloud storage has become one of the most widely acceptable infrastructure services by providing cost-effective, highly scalable and reliable platforms for storing large scale data. Construction of a complex cloud storage system comes with many design choices, producing a large number of configurable parameters. Superior configuration settings can provide significant gains in performance and high quality of service (QoS). However, with the explosive growth of data, cloud storage systems are becoming more and more complex, and it’s diffictlt for cloud operators to change the storage configurations to better support different user cases. Providing an automatic configuration tuning solution for cloud storage systems is in demand.
Cloud storage systems have the following characteristics, which bring higher requirements and challenges to determin the near-optimal configurations. 1) Larger parameter spaces. Cloud storage systems often have multiple layered and highly modular software architectures, span large networks and distributed environments consisting of heterogeneous storage devices. Cloud storage systems has hundreds or even thousands of tunable parameters. For example, as a representative cloud storage system, Ceph comes with 1536 parameters in the latest version, near three times larger than the original version. Worse, these parameters can take on a wide variety of values, including bool, continuous, discrete, and so on. Searching optimal settings in such enormous and complex parameter space is challenging. 2) More unpredictable workloads. In a cloud environment, workloads are varied and unpredictable because of the large number of users and data. The optimal settings are dependent on hardware and workload characteristics and a good configuration for one workload may perform poorly for others. 3) More difficult evaluation. Evaluation results often contain stochastic noises that become much noticeable in cloud environments. Taking the average of multiple tests is the conventional approach to deal with noise. But in cloud storage systems, evaluating a single configuration can take many minutes or even hours, making such approaches unbearably time-consuming.
In recent years, there are many researches on automatic tuning of storage system based on statistical reasoning and machine learning technology. Examples include Genetic Algorithms (GA), Simulated Annealing (SA), Bayesian Optimization (BO), Deep Q-Networks (DQN), Random Search (RS), etc. However, these technologies show great limitations in the cloud storage environment. In the experiments of automatic configuration tuning using Bayesian Optimization \cite{carver} in Ceph, three observations on auto-tuing of cloud storage are obtained, which can well illustrate the problems:
- 面对庞大的参数空间,Auto-tuning 可能导致局部最优的结果
- Auto-tuning may lead to local optimum tuning results in the face of huge parameter spaces.
Causing system performance changes not simply linear to the parameter value. Such irregular and multi-peak correlations make it hard to achieve global optimal performance and fall into local optima.
One of the more popular ones is black-box auto-tuning \cite{sapphire,carver,black} due to its obliviousness to a system’s internals.
面对动态的负载,Auto-tuning 通常推荐的参数是不同重复使用的
- Auto-tuning usually recommends nontransferable tuning configurations in the face of dynamic workloads.
- 面对庞大的参数空间,Auto-tuning 可能导致局部最优的结果
The evaluation process in auto-tuning may easily incur subtle pitfalls, whcih will lead to suboptimal results.
这里的陷阱除了来着噪声导致测试不准确以外
有些参数(例如cache大小)的调整并不能立即影响性能,而会在更长
这些参数的需要谨慎评估,
- 局部最优,庞大
传统强化学习不能应对
传统
观察1:参数联系。云环境常常是分层,很多参数之间错综复杂,很多。
观察2:不可复用。
观察3:测试陷阱。我们的测试发现,很多参数调整后并不能立即对性能产生影响,很多
In this paper,
Determining the near-optimal configurations is challenging in the complex cloud storage environment.
Cloud systems are becoming more and more complex and can be adopted to suit various types of use cases and users make use of cloud resources in very distinct ways.
Cloud storage services provide cost-effective, highly scalable and reliable platforms for storing large scale enterprise data due to the underlying object-based storage technology (e.g OpenStack Swift [4], Ceph [26], Amazon S3, etc.).
由于复杂的云环境,包括负载和设备的变化,很困难这里的技术解决方案的主要动机是试图回答云操作人员如何更改存储配置以更好地支持这些特定的访问模式的问题。Often, storage systems are deployed with default configurations, rendering them sub-optimal. Finding optimal configurations is difficult due to the numerous combinations of parameters and parameter sensitivity to workloads and deployed environments
默认的配置参数往往不能保证集群资源的充分利用和系统的高吞吐率,因此需要调整参数配置从而提高系统在吞吐量、能耗、运行时间等方面的性能。
Storage systems come with a large number of configurable parameters that control their behavior.
【困难】
Determining the optimal configurations is challenging in a complex cloud storage environment.
庞大的参数空间:参数众多,不好的参数带来性能。。
- 庞大且复杂的参数空间:参数多,传统的黑盒
- 干扰因素很多
- 变化莫测的负载和请求
传统的方法主要包括:黑盒;贝叶斯;强化学习
观察1:不同环境下参数的作用差距很大
?
观察2:有些参数不能立即起作用
?
【我们的办法】
Storage systems come with a large number of configurable parameters that control their behavior. Tuning such parameters can provide significant gains in performance, but is challenging due to huge spaces and complex, non-linear system behavior. Auto-tuning with black-box optimization have shown promising results in recent years, thanks to its obliviousness to systems’ internals. However, previous work all applied only one or few optimization methods, and did not systematically evaluate them. Therefore, in this thesis, we first apply and then perform comparative analysis of multiple black-box optimization techniques on storage systems from various aspects such as their ability to find near-optimal configurations, convergence time, and instantaneous system throughput during auto-tuning, etc. We also provide insights into the efficacy of these automated black-box optimization methods from a system’s perspective.
Most storage systems come with large set of parameters to directly or indirectly control a specific set of metrics that may include performance, energy, etc. Often, storage systems are deployed with default configurations, rendering them sub-optimal. Finding optimal configurations is difficult due to the numerous combinations of parameters and parameter sensitivity to workloads and deployed environments. Construction of such a complex system comes with many design choices, producing a large number of configurable parameters [30]. Figure 1 depicts the number of Ceph parameters grows drastically to over 1500, near three times larger than the original version. But storage systems are often deployed with default settings provided by developers, rendering to be suboptimal for specific user cases
Related Work
It is difficult to understand the impact of one parameter let alone the interactions between multiple one. In addition, c
【存储系统自动调参】
SAPPHIRE、Cao、impact
很多研究
针对存储系统参数调优问题研究,很多基于机器学习和统计推理技术的自动调优系统被提出,
In recent years, several studies were made to automate the tuning of all kinds of computer systems.
统计推理和机器学习技已经用于存储系统参数调优的研究
最近几年,有些工作已经尝试使用RL的方法用于系统的自动调优,主要集中于数据库方向的CDBTune和QTune。在存储系统调优中,相关工作才刚刚起步阶段
In recent years, several researches utilized RL model to build auto-tuning systems, mainly in the database area, such as CDBTune and QTune. The researches on RL-based atuo-tuning for storage systems are just in the exploratory stage. Capes adopts Deep Q-Networks (DQN) in optimizing performance for Lustre. Unfortunately, DQN is a discrete-oriented control algorithm, which means the actions of output are discrete. However, Capes does not work in the real storage systems, because configuration combinations in real-world system are high-dimensional and the values for many of them are continuous.
这类方法是最近数据库调参的热门方向,主要包括SIGMOD18的工作CDBTune[6]和VLDB19的QTune[7]工作
存储系统自动调参,Cao
several researches utilized RL model to solve the database problems.
Many studies have built systems to automate the tuning of storage systems. Cao et al. provided a comparative study of applying multiple black-box optimization algorithms to auto-tune storage systems. Genetic Algorithm is adopted by Babak et al. to optimize the I/O performance of HDF5 applications. A simulated annealing approach to the network design problem with variational inequality constraints. Among these algorithms, Bayesian Optimization is the most mature and widely used. SAPPHIRE uses BO to find near-optimal configurations for Ceph. In addition, BO has also been widely applied to auto-tuning for databases and Cloud VMs. However, these 传统的机器学习算法在云存储
Simulated Annealing
Random Search
A simulated annealing approach to the network design problem with variational inequality constraints
在这些算法中,贝叶斯算法是发展最成熟应用最广的。
Simulated Annealing (SA), Genetic Algorithms (GA), Bayesian Optimization (BO), Random Search (RS)
Cao 等人把
and Deep Q-Networks (DQN).
Several researchers have built systems to automate storage-system tuning. Strunk et al. [63] applied Genetic Algorithms (GAs) to automate storage-system provisioning. Babak et al. [4] used GAs to optimize the I/O performance of HDF5 applications. GAs have also been applied to storage-recovery problems [32]. Deep Q-Networks have been successfully applied in optimizing performance for Lustre [40]. More recently, Madireddy et al. applied a Gaussian process-based machine learning algorithm to model Lustre’s I/O performance and its variability [44]. Our own previous work [11] provided a comparative study of applying multiple optimization algorithms to auto-tune storage systems. However, many auto-tuning algorithms have scalability issues in highdimensional spaces [61], which is one of the motivations for Carver. Selecting the important subset of parameters could reduce the search space dramatically, which would then benefit either auto-tuning algorithms or manual tuning by experts.
Black-box optimization techniques include Genetic Algorithms (GA), Simulated Annealing(SA) and Bayesian Optimization (BO) model the storage system as a black box, iteratively try different configurations and adjust configurations based on the evaluation results in each round. Reinforcement Learning
In this section, we describe the related auto-tuning studies. In recent years, several studies were made to automate the tuning of all kinds of computer systems [?]. Jian et al. [?] use neural networks to optimize the memory allocation of database instances, by adjusting buffer pool sizes dynamically according to the miss ratio. Ashraf et al. [?] perform a cost-benefit analysis to achieve long-horizon optimized performance for clustered NoSQL DBMS in the face of dynamic workload changes. Ana et al. [?] try to recommend near-optimal cloud VM and storage hardware configurations for target applications based on sparse training data. Black-box optimization are used, as they view the system in terms of its inputs and outputs and assume obliviousness to the system internals. Methods like Simulated Annealing [9], Genetic Algorithms [2], Reinforcement Learning [37], and Bayesian Optimization [17, 26] are implemented to find near-optimal configurations. Zhen et al. [5, 7, 8] tries to auto-tune storage systems to improve I/O performance. They summarize the challenges in tuning storage parameters and then perform analysis of multiple black-box optimization techniques on the storage systems. Their works mainly focus on the local storage systems, often with less than 10 parameters. While in our work, we focus on the distributed storage systems and find new challenges, such as the configuration constraints, the huge numbers of parameters, and the higher noise.
Caver [?] also tries to solve the challenge of the large number of parameters and exponential number of possible configurations. Like SAPPHIRE, Caver proposes to focusing on a smaller number of more important parameters. Inspired by CART [4], Carver uses a variance-based metric to quantify storage parameter importance. Carver is designed for categorical parameters, as they find most parameters in local storage systems are discrete or categorical. But we observe the exact opposite in Ceph, as most configurable parameters are continuous (about 90 percent). From Table 2 we can find that all the top 16 parameters are continuous. Although there are discretization techniques that can break continuous parameters into discrete sections, feature-selection results depend heavily on the quality of discretization [?]. Thus, Carver is not suitable for our problem. Different from Carver, SAPPHIRE leverages Lasso to choose important knobs. Lasso can provide higher quality results for continuous parameters. And a small number of categorical parameters would not degrade the parameter ranking’s performance.
【结合强化学习】
ottertune、cdbtune
SmartConf [?] try to auto-adjust performancesensitive parameters in the distributed in-memory computing system, spark, to provide better performance. SmartConf uses a control-theoretic framework to automatically set and dynamically adjust parameters to meet required operating constraints while optimizing other system performance metrics. But SmartConf does not work if the relationship between performance and parameter is not monotonic. While in our cases, based on Figure 2b, those relationships can be irregular and multi-peak. Unlike SmartConf, SAPPHIRE uses machine learning techniques, which is a better fit for such complicated configuration space to find near-optimal settings. DAC [33] finds that the number of performancesensitive parameters in spark is much larger than previous related studies (more than 40 vs. around 10). DAC combines multiple individual regression trees in a hierarchical manner to address the high dimensionality problem. To reduce the modeling error, the hierarchical modeling process requires a large number of training examples, which is proportional to the number of parameters. But there are hundreds of performance-related parameters in our problem comparing to 40 in DAC. Modeling such a highdimensional system with DAC would require hundreds of hours to collect training examples, which is impractical
Design
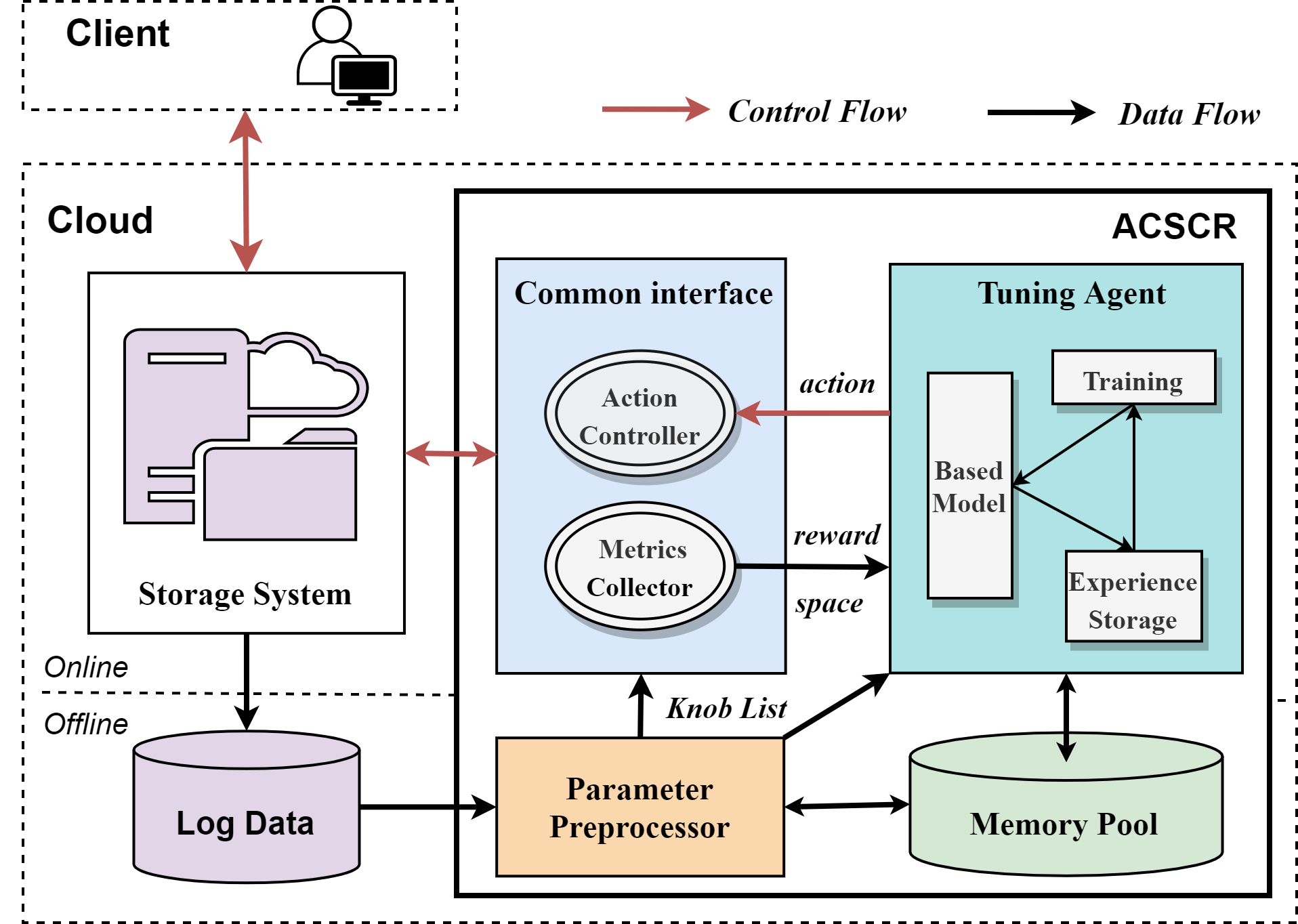
Fig.\ref{ACSTS} illustrates the architecture of ACSTS, a tuning service that works with any storage system in cloud. It uses offline log data collected form the storage system including configurations and performance metrics in different workloads, to build RL models of how the cloud srorage system responds to different knob configurations. When the client users send their own requests to the cloud server through the local interface, ACSTS collects user settings and workloads, which will be stored in the memory pool and fed into the deep RL network respectively, then recommends optimized configurations by the RL models online . ACSTS consists of four main parts, which will be described in detail as follows:
the Metrics Collector conducts stress testing on CDB’s instances which remain to be tuned by simulating workloads or replaying the user’s workloads. At the same time, the metrics collector collects and processes related metrics. The processed data will be stored in the memory pool and fed into the deep RL network respectively. Finally, the recommender outputs the knob confgurations which will be deployed on CDB.
The ACSTS framework defines the mapping of objects to Data Nodes (DNs) and provides interfaces for upper-layer operations on objects, including object creation, deletion, and migration. Based on the RL models, the basic elements of Environment and Agent are defined as follows:
【系统介绍】
unconfigurable
configurable: Static and dynamic configuration
优先级队列:参数分类和筛选关键参数
强化学习:关键参数调整
训练优化:?
【参数筛选&&选择】
【强化学习模块】
参数筛选器
Parameter Sieve
【训练加速】
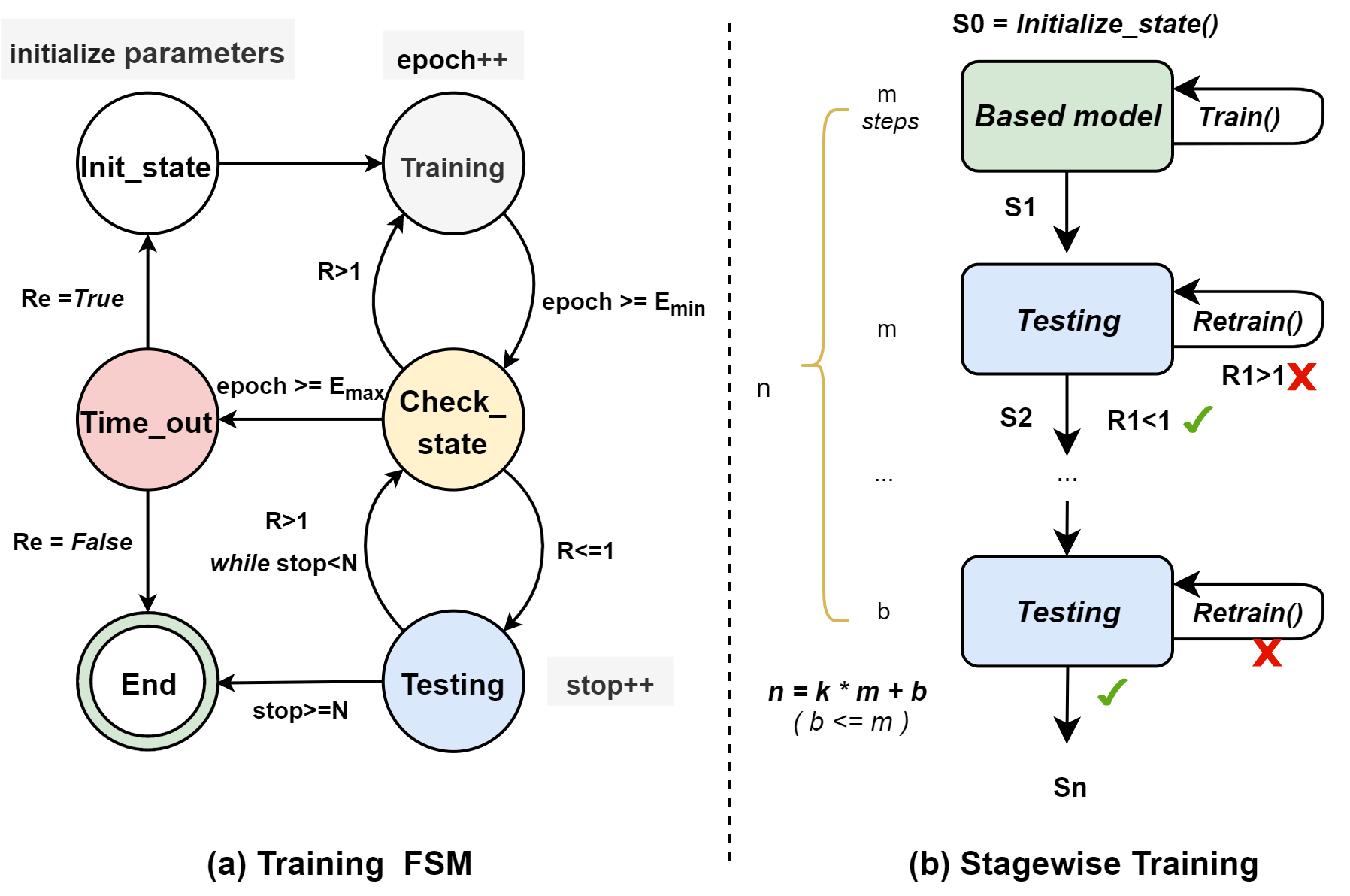
Implementation
ACSTune是在Park \cite{Park}平台上实现的,这是一个面向学习增强的计算机系统的开放平台。 RLRP的所有代码都是用c++和python编写的,并基于张量流实现了强化学习模型 。此外,ACSTune被成功打包到实际的分布式存储系统Ceph (v12.2.13) \cite{Ceph}中。 如图. \ref{Ceph}所示,Mertics收集器和动作控制器通过Ceph Monitor与Ceph交互。 Mertics Collector通过使用Linux SAR (system Activity Report) \cite{SAR}实用程序,每隔30秒从Ceph osd获取系统Mertics。 Action Controller调用Ceph监视器来实现RL Agent所做的放置/迁移操作,并更新Ceph集群的OSDmap。 RLRP以插件的形式实现,并保留了Ceph原有的体系结构和其他流程。
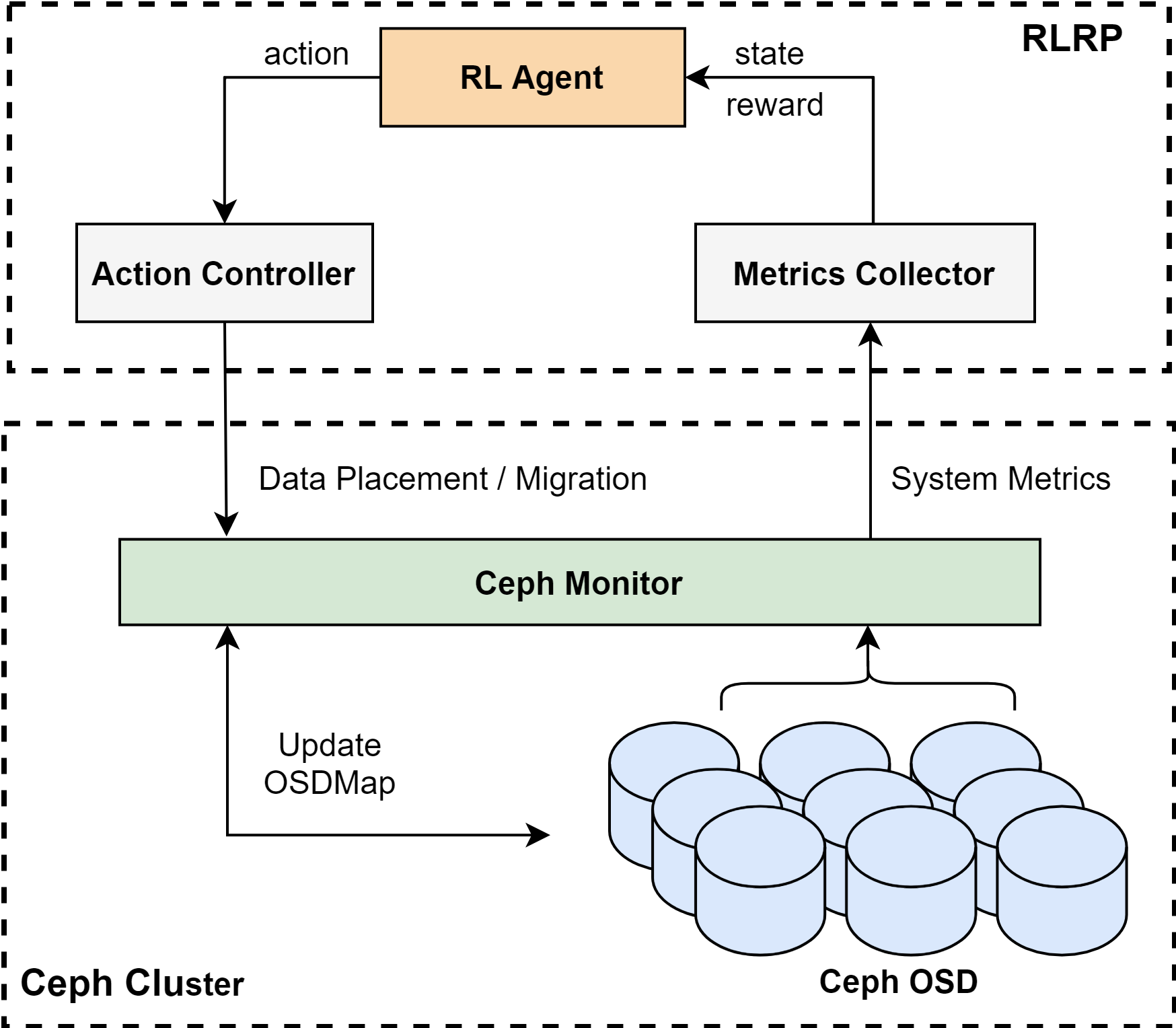
ACSTune is implemented on Park \cite{park} platform, which is an open platform for learning-augmented computer systems. All the codes in RLRP are written in C++ and python, and the Reinforcement Learning model is implemented based on the Tensorflow. In addition, ACSTune is successfully packaged into the actual distributed storage systems, Ceph (v12.2.13) \cite{ceph}. As shown in Fig. \ref{Ceph}, the Mertics Collector and Action Controller interact with Ceph through the Ceph Monitor. Mertics Collector fetches the system mertics from the Ceph OSDs at 30 second intervals by using the Linux SAR (System Activity Report) \cite{sar} utility. The Action Controller invokes the Ceph monitor to implement the placement/migration actions made by the RL Agent and update the OSDmap of Ceph cluster. RLRP is implemented as plug-ins, and retains the original architecture and other processes of Ceph.
Evaluation
Rados_bench:
测试平台:Cloudsim、COSBench、fio/rados benchmark

- https://github.com/intel-cloud/cosbench
Ceph
真实数据