
RocksDB-范围查询优化
Range Query in LSM-tree
天将降大任于斯人也,必先苦其心志,劳其筋骨,饿其体肤,空乏其身,行拂乱其所为,所以动心忍性,曾益其 — 孟大爷
- LeRF: An Efficient Learned Range Filter
- AegisKV: A Range-query Optimized LSM-tree Based KV Store via XX
- 当前进度:测试 + 思考
- 投稿计划
- LeRF:Neurips 2022
- AegisKV:待定
Abstract
Introduce
Background and Motivation
3.1 LSM-tree and RocksDB
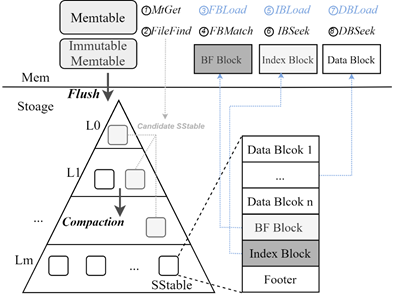
Range query in LevelDB/RocksDB is realized by using an iterator structure to navigate across multiple tables as if all the keys are in one sorted run. A range query first initializes an iterator using a seek operation with a seek key, the lower boundary of the target key range. The seek operation positions the iterator so that it points to the smallest key in the store that is equal to or greater than the seek key (in lexical order for string keys), which is denoted as the target key of the range query. The next operation advances the iterator such that it points to the next key in the sorted order. A sequence of next operations can be used to retrieve the subsequent keys in the target range until a certain condition is met (e.g., number of keys or end of a range). Since the sorted runs are generated chronologically, a target key can reside in any of the runs. Accordingly, an iterator must keep track of all the sorted runs.
LSM-tree范围查询过程 (m, n)
- iterator的形式,跨run的查找
- seek m初始化iterator,找到大于等于m的最小key
- next 推进iterator,使其按排序顺序指向下一个键
- 一系列 next 操作可以用来检索目标范围内的后续键,直到满足某个条件(例如,键的数量或范围的结束)
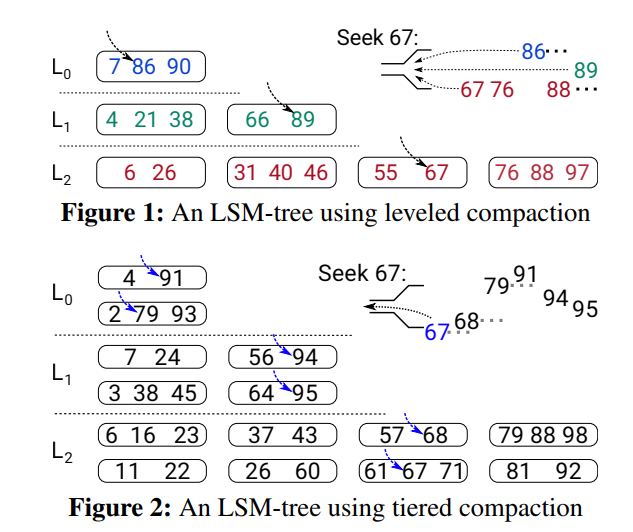
- seek 67,每个run中二分查找最小大于等于67的key,每个key被标记为cursor,这些keys用min-heap排序合并,找到L2的67
- next 比较cursors下的keys,返回最小的,并推进cursor
RocksDB iterator
- 用途:全表扫描、范围查找(大于、小于、区间)、前缀查找
- 接口:NewIterator、Seek、SeekToFirst、SeekToLast 、SeekForPrev、Next、Prev
- 类别:DBIter,MergingIterator,Memtable系列Iterator,LevelIterator 和 TwoLevelIterator
- 创建:RocksDB.newIterator()返回的是一个ArenaWrappedDBIter对象,ArenaWrappedDBIter相当于一个外壳,其持有的DBIter包括了大量的状态变量(上图最高部分,如当前读取key&value),还持有一个内部迭代器InternalIterator,DBIter的作用是将查询转发给底层InternalIterator,InternalIterator返回的KV是原始的二进制数据,DBIter获取到数据之后解析为有含义的内容,包括版本号sequence(末尾8-1字节)、操作类型type(末尾1字节,包括普通的Value Key、删除操作Delete Key、合并操作Merge Key等)、实际用户Key内容,比如Delete Key则需要跳过去读取下一个Key,Merge Key则需要合并新老值,处理完成之后才返回结果。
- 某个CF中范围查询:从 ArenaWrappedDBIter::Seek(const Slice& target) 方法一直往下追即可,MergingIterator::Seek(const Slice& target) 时,对所有的子迭代器进行一次Seek,然后按key排序将子迭代器放入最小堆中,返回最小key的子迭代器,通过 ArenaWrappedDBIter::Next() 获取下一个key时,将上次最小迭代器的值取走,接着依然返回最小key的子迭代器,如此循环往
- Iterator::Seek操作
- 内存中的MemTableIterator的Seek,以SkipList表为例,会通过SkipListRep::Iterator::Seek()找到SkipList对应的节点;
- level 0 SST文件(可能有多个)的Seek,会通过BlockBasedTableIterator::Seek()/PlainTableIterator::Seek()找到BlockBasedTable是SST的默认格式,BlockBasedTableIterator内部又通过SST的Block索引IndexIterator::Seek()来快速定位文件内部大致位置(哪个Block,一搬一个Block为4K大小),最终在Block内通过BlockIter::Seek()以二分查找找到key对应的具体Entry
- level 1~n SST文件的Seek,则是每层有一个LevelIterator,对于一层的多个SST文件,其内容都是排好序的,LevelIterator::Seek()先找到key对应的该层文件,并返回某个SST文件的BlockBasedTableIterator,再调用BlockBasedTableIterator::Seek(),接下来流程与上述level 0中分析类似
- ing…
RocksDB scan测试
- 测试1 ing…
- 预期结论:性能较低
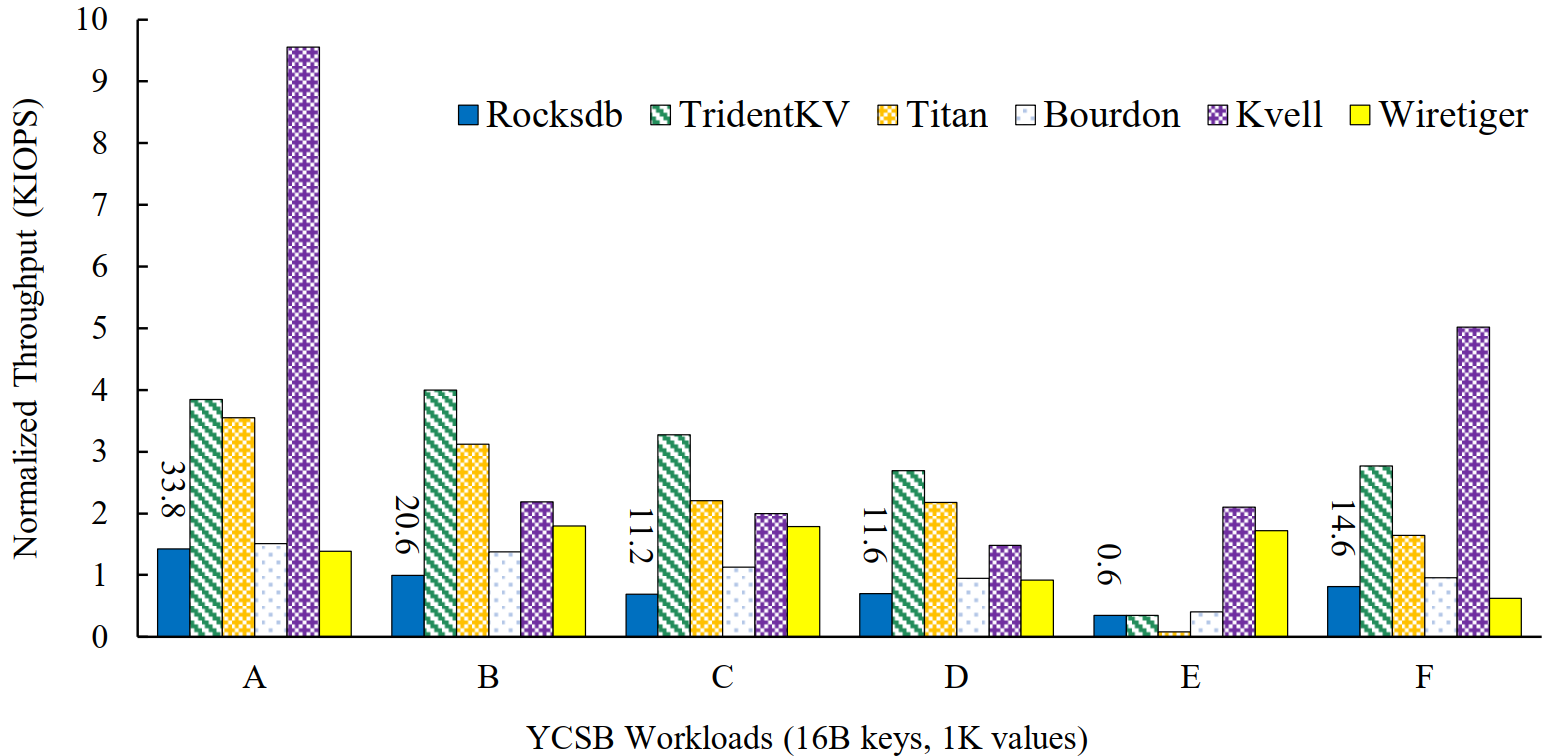
- db_ycsb
3.2 Related Work
过滤器
- RocksDB:prefix bloom filter,Ribbon Filter
- Add 进来的 Key 不再是原来的 Key,而是 Key 的固定长度的前缀,存储一个 Key 前缀 的有序集合,它里面容纳了所有的 Key 前缀的值。通过这个有序的 Key 前缀集合可以快速判断出目标范围是否存在于当前的 SST 文件中
- 布隆过滤器占用的空间变小了,误判率也会跟着提高了一点
- SuRF
- 新的结构Succinct Range Fliter
- Rosetta 优化SuRF的范围查询能力
- 问题1:Short and Medium Range Queries are Significantly Sub-Optimal
- 问题2:Lack of Support for Workloads With Key Query Correlation or Skew
- 学习ing…
- RocksDB:prefix bloom filter,Ribbon Filter
全局索引 REMIX
- 所有key分成几个segment ,每个segment中key数量一致,每个段维护anchor key,cursor offsets和run selectors
- anchor key(A):2,11,31,71
- cursor offsets(B):(0,0,0)(1,2,1)(3,4,1)(3,4,5)
- run selectors(C):(0,2,1,1)(0,1,0,1)(2,2,2,2)(0,1,0)
- 查询(13,60),对比A,从第二组开始;找C,在run0;找B,游标1,找到11,小了;R0往后移,R0=2;找第二个C,在run1,游标2,找到17,符合;R1往后移,R1=3;找下一个C,在run0,游标2,找到23,依次类推…..
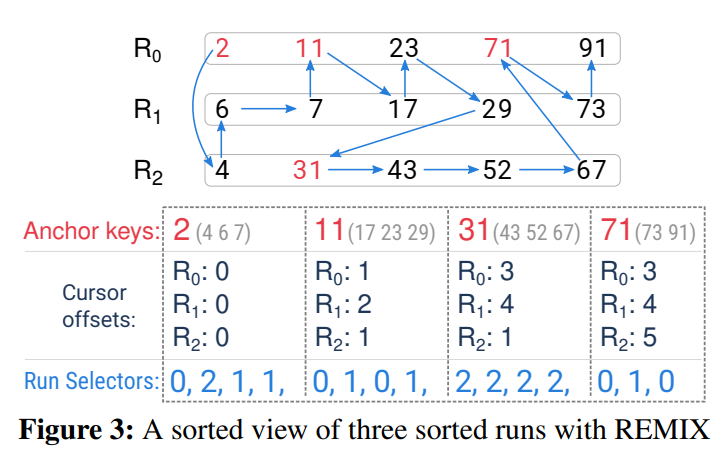
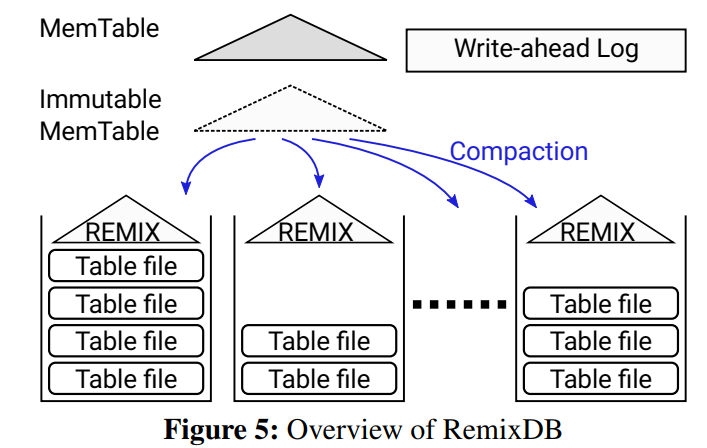
优点:通过全局索引,加速范围查询
缺点:插入新数据时索引重构开销较大
3.3 Problems
- 问题1:过滤器方法不适合长范围查询场景
- 测试2 ing
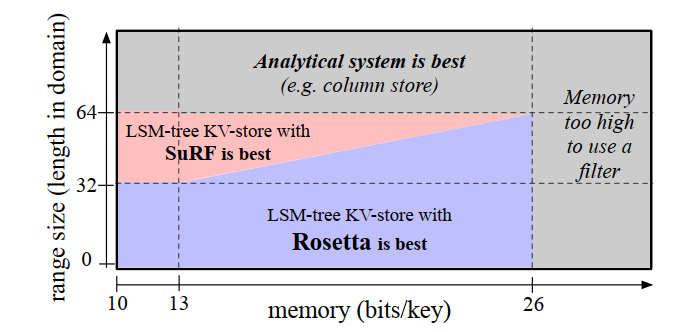
- 问题2:索引方法插入新数据时索引重构开销较大 ?
- remixdb代码
- 测试3 ing
问题3:删除问题
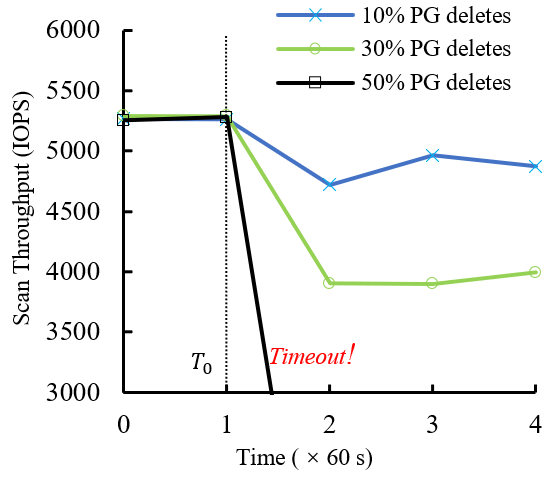
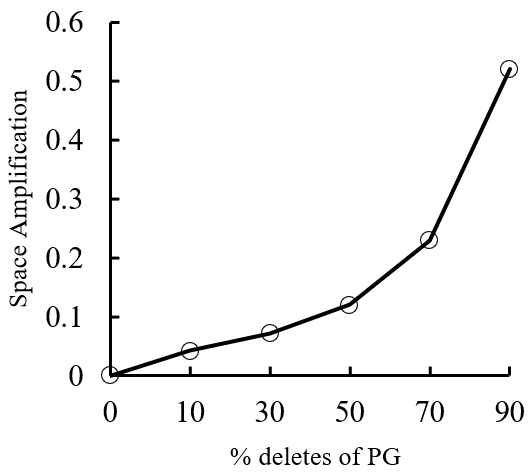
Design(XXKV)
- 两则结合?learned filter?
- 除了分区,删除问题更好方法?
- 异步 scan:费长红 ing
1. Range Filter
- Learned Filter, Tim Kraska (MIT)

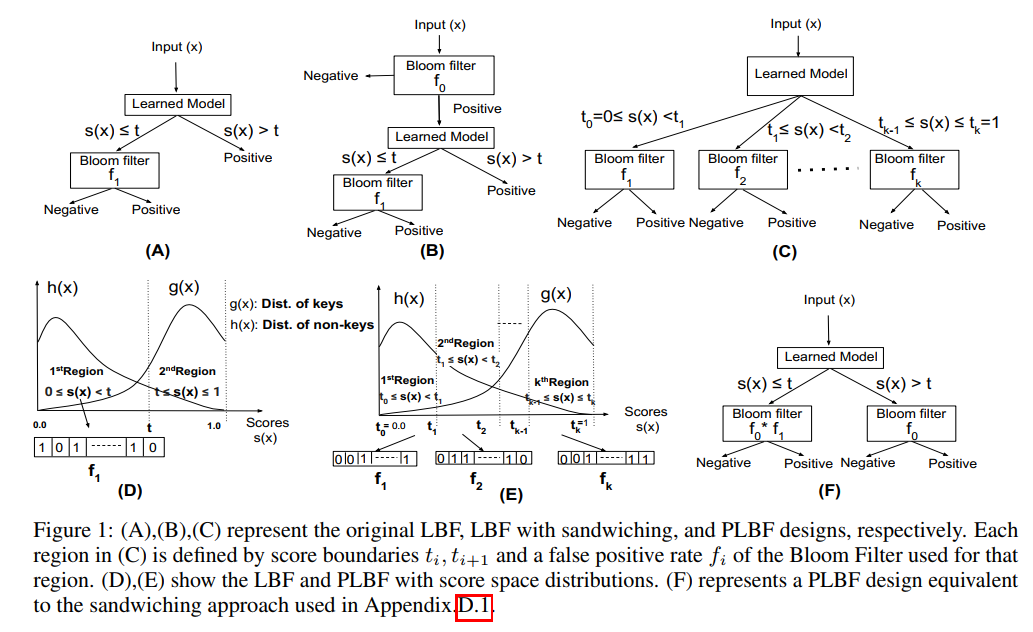
- PLBF:Partition Learned Bloom Filter, Tim Kraska
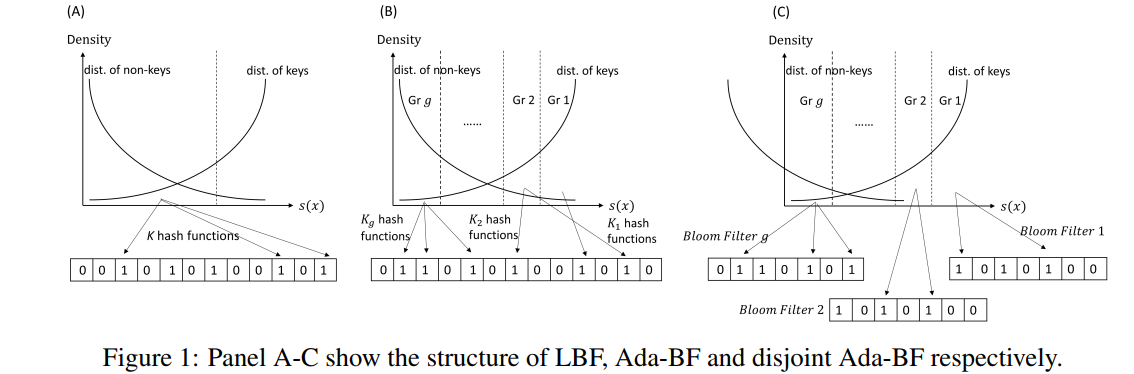
Adaptive Learned Bloom Filter (Ada-BF) ,NeurIPS 2020
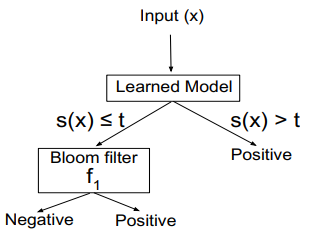
LeRF: An Efficient Learned Range Filter For LSM-tree Based KV Stores
- filter特征
- 存在性索引:0/1分类问题
- allow false positives, but will not give false negative (有不一定有,没有一定没有)
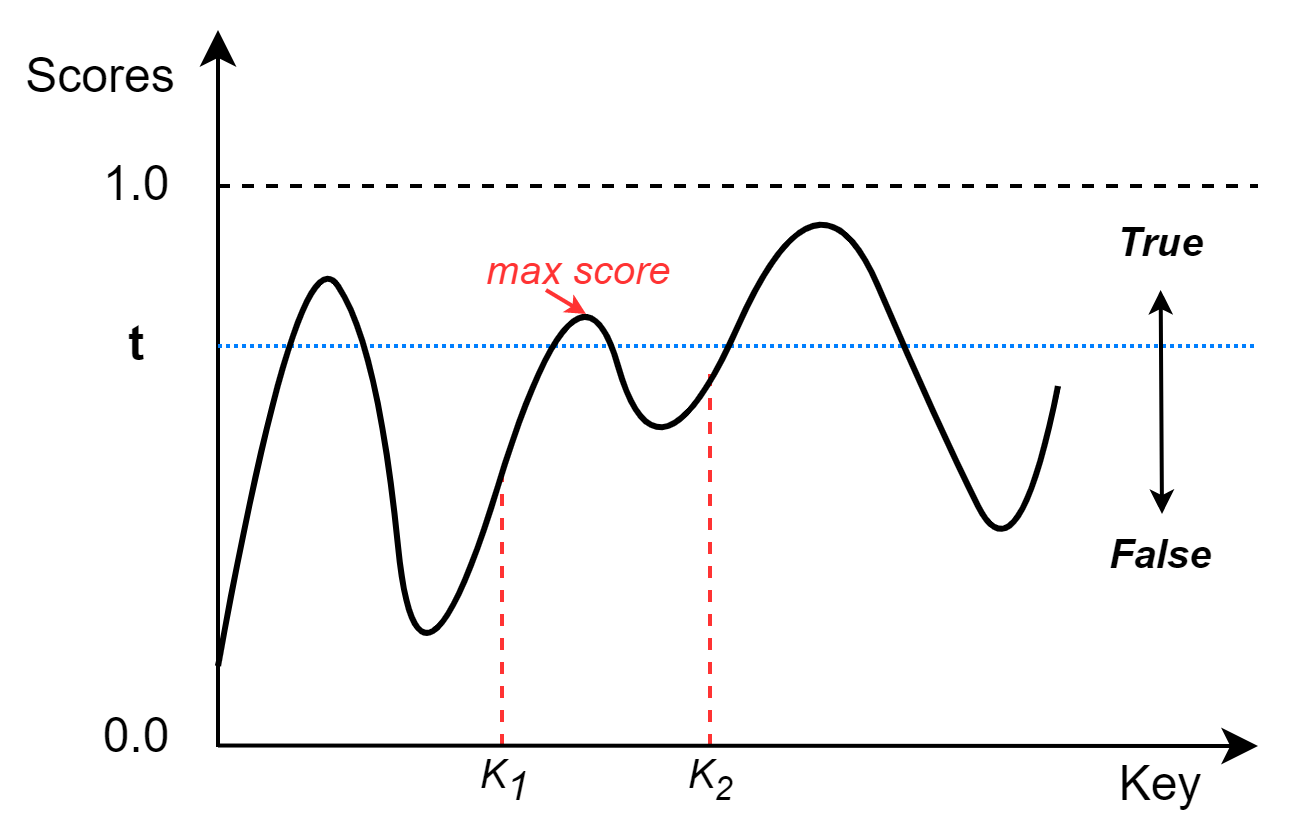
Range Filter:绘制Key-Score 的 PDF,判断范围内最高score是否大于t;例子: (K1, k2)
- 如何绘制PDF:插值问题
- 样本选择:正向样本:keys in the SStable;负向样本:?
- 区域最大值(极大值):求导
- 讨论 tradeoff:空间与精度
- bloom filter:位数(空间)与精度
- LRF:插值点(空间)与精度
- 测试 ing
- filter特征
LRF 2.0
LBF: f(x)输出了x存在(为1)的概率,可以把f(x)看成概率分布(PDF)
CDF累计分布函数F(x)
(k1, k2)范围查询:在(k1,k2)内至少有一点存在的概率
f(x)的选择,二分类问题
- RMI、Lr、Plr、SVM、CART、CNN、RNN
CDF累计分布函数F(x),等于PDF的积分 \(F(x) = \int_{-\infty}^x f(x)dx\)
2. 删除问题
3. 异步Scan
Evaluation
- 负载
- db_bench
- YCSB