
Learned index-调研和分析
本文主要介绍Learned index,详细的调研和使用分析。
天上冷飕飕,地上滚绣球;有陷是包子,没陷是窝头 — 郭儿
初衷
- 性能问题 -> ceph不能发挥nvme的全部性能 -> 优化bluestore / rocksdb读性能 -> cache / index / filter / 改结构
- 结合热门的算法 / 技术 -> ml / nvm / rdma / 结合工业上的问题等等
- 通过最新的索引技术learned index / succinct trie / others来加速LSM的查找过程
一、背景
1. 学习型数据库系统
- 相关背景
通用的数据库系统为不同的应用需求与数据类型提供统一的处理方式,在取得了巨大成功的同时,也暴露了一定的局限性:由于没有结合具体应用的数据分布与工作负载,系统往往难以保证性能的最优。为了解决这一问题,”学习式数据库系统”成为了目前数据库领域的研究热点,它利用机器学习技术有效捕获负载与数据的特性,从而对数据库系统进行优化。
- 相关研究
基于数据驱动的学习式数据库系统(learnable database systems)在近些年得到了工业界和学术界的广泛关注。在工业界,亚马逊开发了OtterTune系统,通过机器学习技术实现基于负载特性的自动旋钮配置。Oracle公司也于2017年发布了“无人驾驶”的数据库,可以根据负载自动调优并合理分配资源。在2019年,华为发布了首款人工智能原生(AI-native)数据库,首次将深度学习融入分布式数据库的全生命周期。在学术界,以Tim Kraska团队为代表也有多篇研究性论文。[1]
问题与挑战
- 在语义层面:如何将数据库组件建模成机器学习问题,保证设计的模型提供和传统数据库组件相同的语义
- 在实现层面:系统应不局限于某一个或某几个特定的应用,因此,如何设计通用的机制,使数据库组件可以根据数据特征选择对应最佳模型,颇具挑战性
- 在优化层面,如何将机器学习模型与传统数据库优化技术相结合,以应对复杂的实际情况
学习型数据系统相关技术研究及相关paper(以Tim Kraska团队为主)
《The Case for Learned Index Structures》,挂上Jeff Dean大名,在数据库系统中掀起了一阵机器学习之风,Tim Kraska也顺利成章的成为了学习型索引的开山鼻祖
学习型数据系统
Kraska在CIDR‘19上提出SageDB: A Learned Database System[2],它是集大成者,把数据库中所有能用机器学习替代、结合的地方都替代、结合了。包括了其研究的所有学习型技术:学习型索引、学习型排序、学习型数据排布(即切分)等等。凭着这些技术,数据库顶会(sigmod,vldb,icde等等)每年中好几篇,值得一提的是,sigmod’20中了7篇!
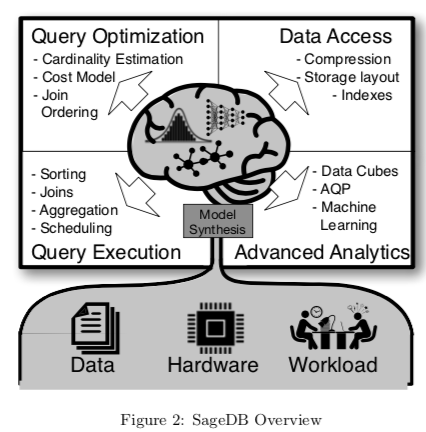
学习型索引结构
- VisTrees: fast indexes for interactive data exploration,sigmod‘16
- The Case for Learned Index Structures(sigmod‘18,[3]):提出了Learned Index基本概念和构建思路,提供替换传统索引的一些案例方法及其优化手段,Learned Index开山之作。
- FITing-Tree: A Data-aware Index Structure(sigmod‘19,[4]):从省空间角度出发构建Learned Index。
- Designing Distributed Tree-based Index Structures for fast RDMA-capable Networks,sigmod‘19
- ALEX: An Updatable Adaptive Learned Inde(sigmod‘20,[5]):原始的Learned Index只支持只读场景,ALEX将其优化支持更新/插入场景。
- Learning Multi-Dimensional Indexes(sigmod‘20,[6]):使Learned Index支持多维场景。
- CDFShop: Exploring and Optimizing Learned Index Structures(sigmod‘20,[7]):自动生成RMI。
- The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds(VLDB‘20,[8])
- Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads,vldb‘20
- RadixSpline: a single-pass learned index(sigmod‘20,[9]):一次数据传递构建模型
- Partitioned Learned Bloom Filter[10]:优化的学习型Bloom Filter
- SOSD: A Benchmark for Learned Indexes 和 Benchmarking Learned Indexes (Experiments & Analyses),vldb‘20,相关测试工具(https://github.com/learnedsystems/SOSD)
学习型排序算法
- The Case for a Learned Sorting Algorithm,sigmod‘20,sosp‘19 Workshop
学习型数据排布
- Chiller: Contention-centric Transaction Execution and Data Partitioning for Modern Networks,sigmod‘20
学习式系统调优(非常多)
其他
- From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees(osdi’20,[11]):在Leveldb(LSM-tree)中构建Learned Index,并使用其加速SStable查找。
- Learned Garbage Collection,pldi‘20,学习型垃圾回收
- ARDA: Automatic Relational Data Augmentation for Machine Learning,vldb‘20,自动机器学习
- MIRIS: Fast Object Track Queries in Video,sigmod‘20,视频流对象查询
- IDEBench: A Benchmark for Interactive Data Exploration,sigmod‘20,交互式搜索测试工具
- DB4ML - An In-Memory Database Kernel with Machine Learning Support,sigmod‘20,内存数据库内核,更好的使用机器学习算法
- 。。。
2. 学习型索引结构
索引是实现数据高效访问的重要途径,有助于快速得到键的相关信息,如地址、存在与否等。使用机器学习中的回归模型建立起键值与数据之间的对应关系或分类模型判断键值是否存在,从而利用数据分布或特征对索引结构进行优化,使索引变得专用。进一步探讨机器学习模型如何与传统的B树、布隆过滤器等结构结合,进行效果优化
- Learned Index发展
- RMI:learned index最初版,不同场景可以使用不同模型,多层结构
- CDFShop:RMI开源实现和优化
- FITing-Tree:优化learned index,省空间
- PGM、ALEX:优化learned index,支持插入和更新
- Flood:优化learned index,支持多维数据
- RadixSpline:优化learned index,一次构建,不要多次训练
- Bourbon:learned index in LSM-tree
- SOSD:learned index的benchmark
二、论文分析
1. The Case for Learned Index Structures
真正的大师,永远怀着一颗学徒的心 — 易老
说在前面
300+引用,Jeff Dean,以下分析省略部分公式,论文细节参考《论文学习—学习型索引结构案例》
基本观点:索引就是模型。Range Index索引(以B-Tree为代表)可以看做是从给定key到一个排序数组position的预测过程,Point Index索引(以Hash为代表)可以看做是从给定key到一个未排序数组的position的预测过程,Existence Index索引(Bloom Filter)可以看做是预测一个给定key是否存在(0或1)。这样一来,索引系统是可替换的,我们可以直接用ML模型去替换现有的索引模块实现。
索引一般是通用结构,它们对数据分布不做任何假设,也没有利用现实世界数据中更常见的模式,描述数据分布的连续函数可以用来构建更有效的数据结构或算法(机器学习模型)。假设用于Range Index的key的范围是1-100M,那么可以用特殊的函数或者模型(直接把key本身当成是offset)去做索引而不必再用B-Tree。
另外一个好处就是,现在支持和加速机器学习的硬件发展非常快(CPU-SIMD/GPU/TPU/…越来越强大),机器学习代价越来越低,性能越来越高
然而,如同前面提到的,用ML模型去做索引也可能存在一些问题:
- 语义保证。通过数据训练得到机器学习的模型是存在误差的,但是我们设计的索引经常需要满足严格的限制条件。举例来说,Bloom Filter的优势之一是可能会有把不存在的错判成存在(False Positive)但绝不会把存在的错判成不存在(False Negative)
- 训练问题。如果避免模型的overfitting?换句话说,如果当前训练的模型只能memorize当前数据形态而并不能generalize新的数据,该怎么办?
- 普适性。如果数据并没有任何特殊性,如完全随机或者不能被我们的设计模型架构所归纳,该如何处理?另一种情况是,新的数据破坏了之前模型归纳出的特殊性,比如新的数据来源于一个新的或者是变化了的distribution
- 效率评估。模型的inference过程相比显式索引数据结构的计算更昂贵
最原始的代码没开源,某人的learned index https://github.com/sunzhuohang/Learned-Indexes
对RMI开源了:https://github.com/learnedsystems/RMI
学习型B树(Range Index)
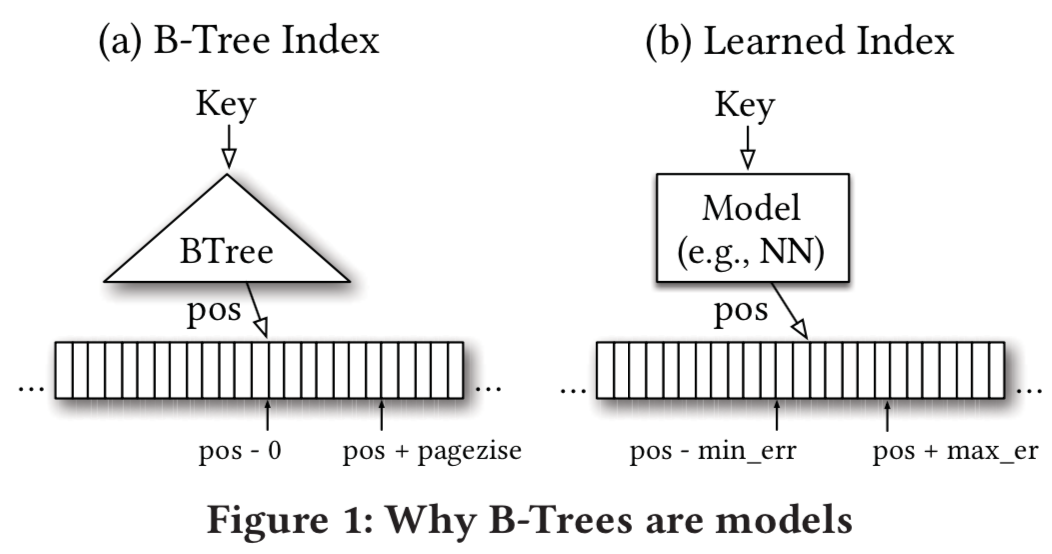
- 传统索引
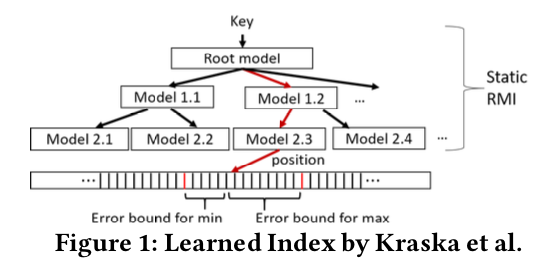
数据库系统通常使用B-Tree或B+-Tree来实现range index。查询时给定一个key(或一些定义range的keys),B-Tree会索引到包含该key的对应范围的叶子节点,在叶子节点内对key进行搜索。如果该key在索引中存在,就会得到其对应的position。这里position代表指向逻辑页的一个offset或pointer 。出于效率考虑,一般在一个逻辑页内的records会用一个key(首个)来index。如图所示,输入是一个key,输出是对应要查询record的position的区间[pos, pos + pagesize]。
Learned Index
- 从机器学习的角度,我们可以把B-Tree看做一个regression tree,这个模型(B-Tree)的建立过程也是依赖数据的,只不过它不是通过梯度下降的方式得到的,而是通过预先定义的法则(insert函数)。如图1右边,对于输入key,模型预测出一个pospred,若区间pospred - min_err,pospred + max_err中包含这个record,那么预测准确,其中min_err的期望是0(这时pos就是record的位置),max_err的期望是pagesize(这时record的位置在pos+pagesize)。那么min_err和max_err在模型中具体如何计算呢?对于训练数据(现有的(key,pos)),计算出每一组pospred和和pos的正负差,然后取最大的正差就是max_err,负差就是min_err。
- 查找过程就是一个预测过程,将key映射到区间内,区间两端是pos-min_err,和pos+max_err,min_err和max_err就是机器学习模型在训练数据上的最小误差和最大误差。如果我们记录了每一个key最小误差和最差误差,那么对于任意一个key,就可以通过模型对数据位置进行预测,如果关键值存在,则可以在最小和最大误差之间搜索到(一般是二分查找过程)。
- 复杂度分析:假设有1M个key(取值从1M到2M),那么可以直接用一个等价关系(线性模型)代替B-Tree,也就能把log(n)的复杂度减少成常数复杂度。同样的,如果(key, pos)是一个抛物线,那么神经网络模型也可以通过常数复杂度进行预测。考虑到神经网络的泛化能力,如果数据具有特殊性,那么用模型代替B-Tree就能减少查询复杂度。
Indexs as CDFs:对于常见的范围查询,所有的数据都是排好序的,能想到一个简单的模型就是预测给定key的累计分布函数(cumulative distribution function): p=F(key)*N,这里的p就是预测位置,F(key)就是预测的累计分布函数
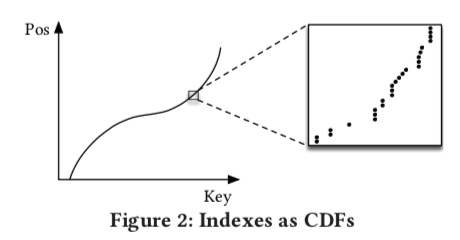
问题与解决
- 文中提到了简单的预测分布函数所面对的挑战,其中既包括了Tensorflow本身的效率问题,又包括了预测函数的误差难以控制问题。为了克服上面的挑战,论文提出了几种学习框架,其中最为基本的是learning index framework (LIF) 和recursive-model indexes (RMI)
- LIF主要是针对一个模型索引的优化,针对给定的模型规则,LIF生成索引配置,优化并且自动进行测试。它采用Tensorflow自带的神经网络模型去学习简单的函数,比如线性回归函数。在真正的数据库中应用时,LIF会生成基于C++的高效索引结构,将模型预测优化到30ns以内
- RMI则主要优化得到预测结果后last-mile查找准确性。举一个例子,要通过单一模型预测100M个key位置产生的最小和最大误差是很大的。但是如果我们采用两层模型,第一层模型将100M个key映射到10k个位置上,第二层将10k个key映射到1个位置上,则最小和最大误差会降低很多
- 这种思路就是用多模型来解决the last-mile accuracy问题,这里的多模型的思路是来源于混合专家网络(MoE)[12],具体可以参考原文
- RMI构建算法和过程较为复杂,基于成本模型/误差范围等和ML算法,可参考《论文学习—学习型索引结构案例》
- 下面举个简单例子大概介绍一下
- 给我例子
- 这是网上找的一个数据库里B+Tree index的例子[1]
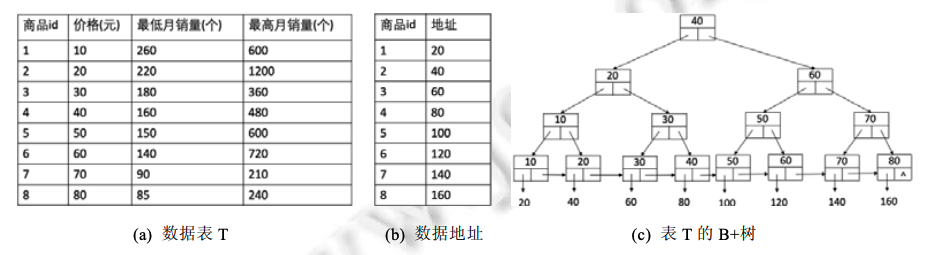
传统的B+ Tree,查询复杂度O(logN);如果考虑数据分布,ML会得出类似于Pos=20 * key(id)的线性模型,这个复杂度直接变成了O(1)
根据数据分布学到key 到地址 Pos 的映射函数,对于这种比较简单的数据分布,模型比较容易拟合出该映射函数。但是当数据库中的数据量很大或数据分布较为复杂时,如果还是只用一个模型拟合,该模型往往只可以拟合出总体趋势,但无法准确拟合出具体某一小部分数据的映射关系
如对数据表(a)中最低月销量列和对应地址构建学习索引
- 单个线性函数拟合可能是Pos=−6/7×K+1600/7,则此时拟合的准确率只有2/8=25%
- 如果我们将数据进行拆分,每一小部分数据用对应的模型拟合,那么效果会提升。如85~90的拟合函数为Pos=−4×K+500,140~150 的拟合函数为Pos=−2×K+400;160~180 的拟合函数为 Pos=−K+240;220~260的拟合函数为Pos=−0.5×K+150,则此时准确率为 100%
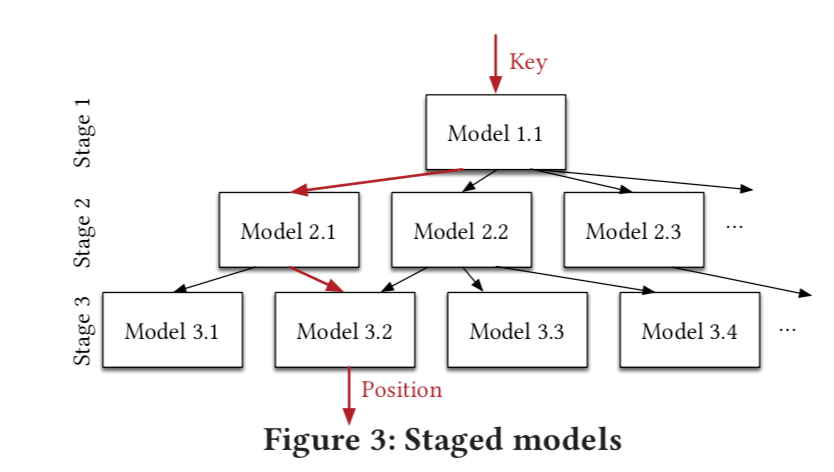
RMI模型的就是这种分段拟合的思想,它是建立学习式索引模型的核心。

RMI 模型目标是将键 K映射到它的地址Pos。RMI的基本结构是树,一般2~3层。树的结点是模型、边是引导到下层模型的判别式。根结点和中间结点的模型起引导作用,一直引导输入K到叶结点。叶结点模型根据其输入得出地址。RMI的层数的递增表示数据范围的缩小,直至叶结点可以拟合最小范围的数据分布。这里的根结点往往采用简单神经网络模型,其他结点使用线性回归模型。如果数据分布过于复杂而无法拟合,叶子结点可以直接换成传统的B树结构。
- RMI模型的查找:当输入键后,算法根据该键的取值找到 RMI 结构中最适合的叶结点,从而输出该键的地址。最后在预测的地址左右允许误差范围内查找是否存有该键:若存在,返回地址;若不存在,返回 “空”。
- 当输入K=90时,模型1.1输出90,引导至模型2.1输出2×90=180,最后引导至模型3.1输出P=(-2×180+500)=140,则地址为Pos=140。在底层地址140附近指定误差范围内查到有地址140存了K=90。同理,当输入为K=100时,最后输出为Pos=100.在底层地址100附近指定误差范围内未查到K=100,说明数据库没有键K=100。假设底层模型,例如3.3,对K为155~200的数据拟合不佳,则可替换为K为155~200的传统B树;
- RMI 模型的构建:首先,需要确定好静态RMI结构,如RMI的层数、每个结点的孩子结点个数等;然后,把数据库中所有键-地址对根据数目均分到不同的叶结点内;最后,各个叶结点与其所有连接的上层结点根据其分配到的数据进行训练,使得当输入该数据范围内的键时,模型可以输出对应地址。输出的地址允许有一定误差,误差范围也被作为评价 RMI 模型好坏的指标。如若模型3.1输出的底层地址140上没有找到键K=90,而在地址141或142找到,说明误差范围是1。
- 学姐论文:内存AEP索引结构—ComboTree[13],高可扩展高性能
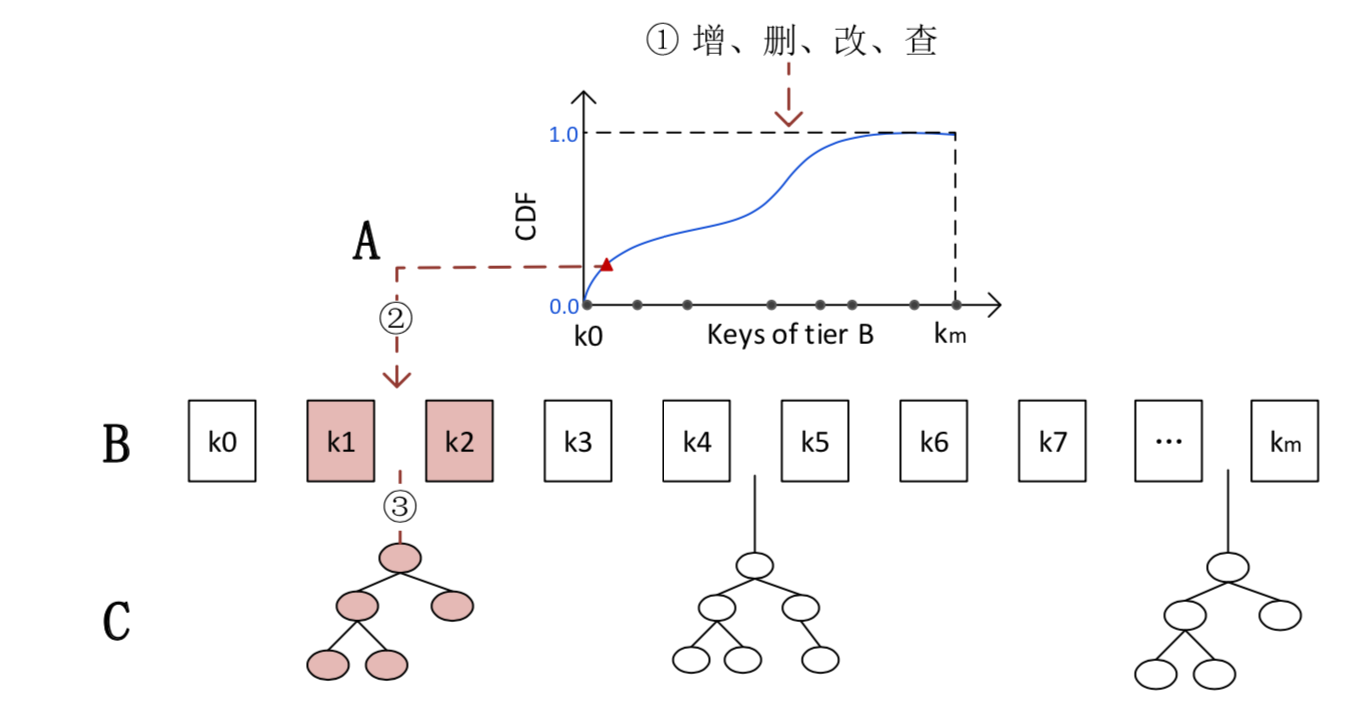
相关优化
- 普适性优化:如果数据本身是随机的,RMI模型并不能归纳出数据中的分布规律,应该怎么办?
- 这里的思路就是rollback到B-Tree Index。由于RMI模型的稀疏性和LIF的高效率,即使对于这种情况,加入RMI的range index效率也并不会降低太多。整个训练过程见下图,文中是分stage训练的(也可以用end-to-end),训练时可以用grid search和一些best practice来tuning hyper-parameter。我们知道,在训练完RMI后,能得到每个experts的minerr和maxerr。我们可以用它们来和预先给定的threshold(比如设成pagesize)对比,当成rollback的条件。更重要的是,它们能够优化索引搜索过程。通常的B-Tree在找到输入key的offset后会用binary search(也有其他的方式如Quaternary Search但是效率提高不明显)。而RMI模型预测出来的position可以用作更准确的pivot来进一步提高搜索record的性能。
- 搜索算法的优化:论文中提出了Model Binary Search,Biased Search和Biased Quaternary Search,这可以参考论文3.4节部分
测试:论文中用了四个数据集来做了实验,分别是Weblogs(日志数据,用timestamp建索引,这个最符合真实复杂环境),Maps(地图数据用经度建索引,虽然这个也是真实数据,但是相对更规则), Web-documents(真实的document数据)和合成的Lognormal(采样生成的数据,为了模拟真实环境中的长尾分布)。其中Weblogs、Maps和Lognormal数据使用整数来当索引的,而Web-documents是用字符串来当索引的(因为不连续)
下面举日志数据Weblogs数据集实验的测试为例。将经过cache优化过的B-Tree页大小为128作为baseline,对于学习索引,使用两阶段模型,在没有GPU 和TPU 的机器上运行结果如下图所示。可以看到学习索引比B-Tree更快的同时,内存占用更少
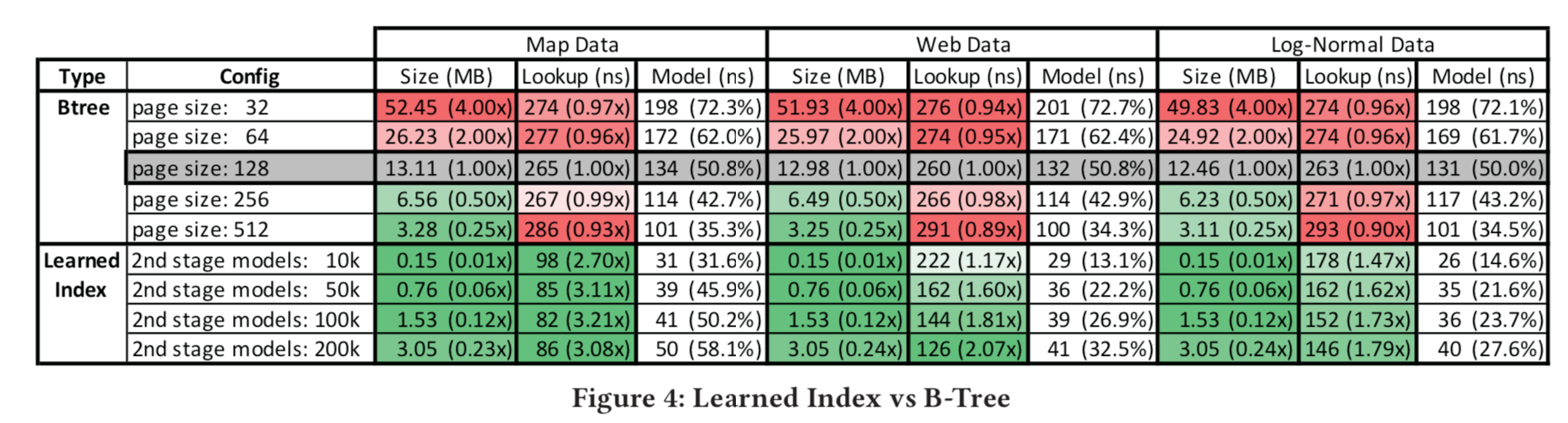
- 实验用的RMI只有两层,而且误差不稳定。猜想是如果更深的RMI,精度提出和时间效率提升以及内存占用提升相比并没有太好,论文中提到未来可以进一步采样模型压缩来优化
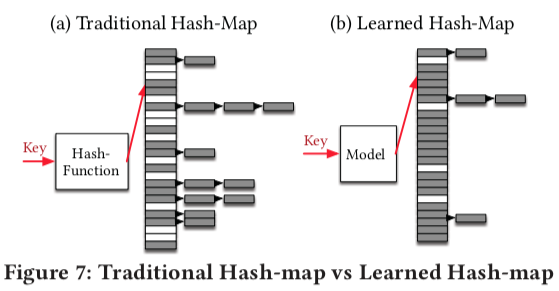
学习型Hash (Point Index)
- Point Index - 替换Hash index,减少hash冲突
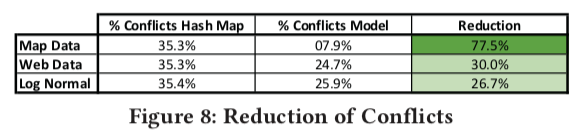
学习型Bloom Filter(Existence Index)
- Existence Index - 替换bloom filter,两种思路:对0/1的预测和分类问题,更高准确度

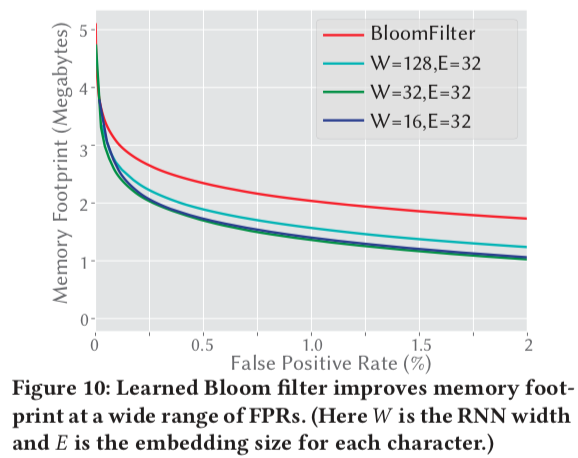
总结
- 基于静态RMI的学习式索引,为机器学习对索引的优化开辟了先河。然而,文章中的模型大多都是初步想法,缺乏可靠的理论支持,也没有应用于解决实际问题,仍然有大量问题需要进行研究:
- 仅支持静态操作(read-only),该索引的底层数据由紧密有序数组组织,这导致插入或删除操作需要移动大量数据。此外,由于RMI结构是静态且层次设计,当叶结点由于数据分布的改变需要重新训练时,该叶结点所有连接的上层结点都需要重新训练,训练成本过高,所以该模型仅支持查找操作,不支持插入、删除、更新操作,为使模型支持动态操作。
- ALEX(Kraska后续工作,sigmod‘20)、ASLM[14]、Doraemon[15]、PGM
- 数据划分不合理,采用按个数均分的方式划分数据,而未考虑数据之间的关系远近。而模型往往擅长拟合关系较近的数据,所以数据之间的关系远近也应该纳入数据划分与否的指标之一
- ASLM、ALEX、有很多学习型划分算法的研究
- 仅考虑均匀的查询负载,该模型假设对所有键的查询概率都相同,即没有热键。而现实查询往往存在热键,它们的查询准确率对模型的准确率影响最大,所以应该对热键有特殊的处理以提高模型性能。
- Doraemon
- 未考虑多维索引问题
- Learning Multi-Dimensional Indexes (Kraska后续工作,sigmod‘20)
- 机器学习本身的问题
- 训练复杂速度慢:RadixSpline
2. ALEX: An Updatable Adaptive Learned Index
禹门三汲浪,平地一声雷 — 汪少
说在前面
- Sigmod’20,Kraska组后续工作,论文细节参考《论文学习—ALEX: 一个可更新的适应性学习索引》
- 最初的Learned index只支持只读数据索引场景,ALEX的工作使得Learned Index也支持更新和插入
- ALEX的核心解决思路是:
- 让每个模型独立管理自己的数据,即插入到自己这部分的数据变化不影响其后的模型
- 更改数据存储结构(动态树结构 & 模型),使得插入、删除更为迅速
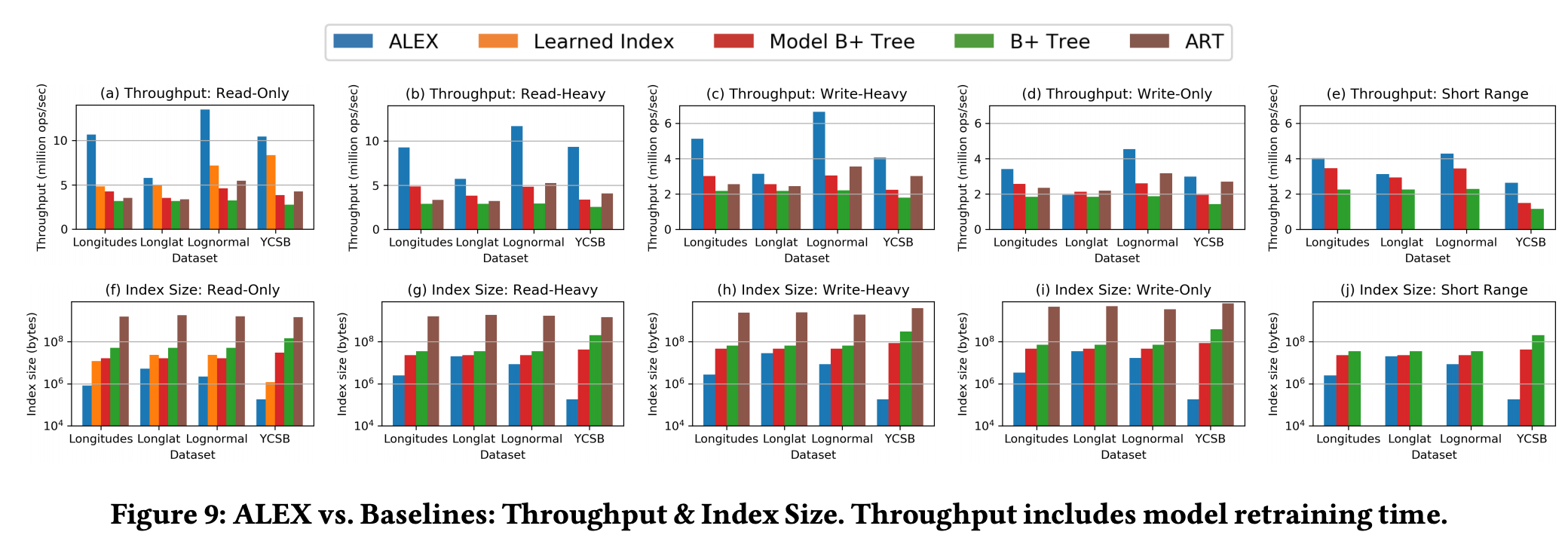
- 在只读工作负载上,ALEX在性能上比学习索引高2.2倍,索引大小小15倍;在读写工作负载的范围内,ALEX比B+树快4.1倍,但性能从未下降,索引大小可小2000倍。ALEX还击败了机器学习增强的B+树和内存优化的自适应基数树,可扩展到大数据大小,并且对数据分布稳定
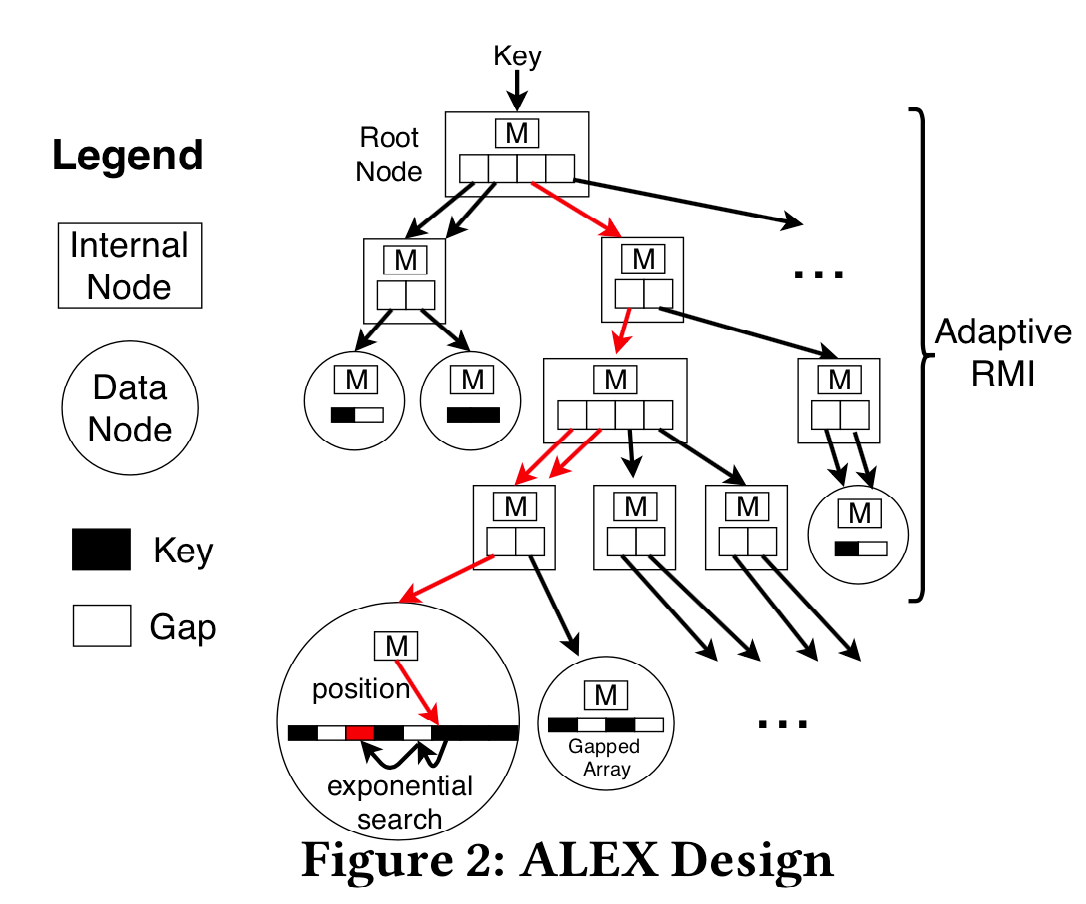
ALEX设计
四项关键技术:gapped array / model-based insert / exponential search / adaptive struct
让每个模型独立管理自己的数据
- 可以看到上图中,左边的RMI用多个模型直接映射整条数组,而右边的ALEX,更类似于树结构,每个模型下挂自己的数据结构。这样当一个插入,比如右图红色箭头来的时候,只要调整自己的模型就好了,而不影响其他的模型。(当然可能还会影响父节点模型进行分裂)
数据结构(动态树结构 & 模型)
- 叶节点/数据节点:存储线性回归模型(映射关系,只需存储斜率和截距空间小),两个间隙数组,一个存储key,一个存储实际有效负荷
- 内部节点:存储线性回归模型,指向子节点的指针数组
- ALEX使用了gapped array和packed memory array两种。其实就是有间隙的数组,后者提供了间隙的管理机制,这样做使得插入性能大大提升。直观理解就是如果插入的地方没有元素,直接放进去就好了,少了个挪动的步骤,即用空间换时间。可以参考在gapped array中 insertion sort是 O(nlogn)的论文《Insertion sort is o(n log n)》[16]
查找过程
- 基本与RMI类似,如图中的红线,为了查找一个key,从RMI的根节点开始,迭代地使用模型来”计算”指针数组中的一个位置,并且跟随指针到下一级的子节点,直到到达一个数据节点。
- 不同的是,在叶节点中的搜索采用的是exponential search,而RMI在提供的误差范围内使用二分搜索。只要模型足够好,实验验证了误差较小的情况下指数无边界搜索比二分搜索法有边界搜索更快。
插入/更新过程
具体过程较为复杂,参考《论文学习—ALEX: 一个可更新的适应性学习索引》中算法1分析
model-based insert,不同于RMI,RMI是先排好序,让后训练模型去拟合数据。而ALEX是在模型拟合完数据后,将数据在按照模型的预测值插入到对应的地方。这大大降低了预测的错误率。(如果预测的地方被占了,再进行挪动或分裂啥的)
ALEX是一个adaptive struct,提供了动态调整RMI结构的能力。比如在插入一个模型的数据超过threshold(定义了一个数据密度上限和下限,超过上限就扩展分裂,低于下限就收缩)后可以以当前模型为父节点,生出若干个子节点来重新分配数据
拓展方式可以分为横向和纵向,是否扩展、如何扩展和选择扩展或者重新训练都是通过基于成本模型(TraverseToLeaf)来判断:一旦数据节点满了,我们将预期成本(在节点创建时计算)与经验成本进行比较,没有显著偏离,则进行扩展而重新训练;如果偏离了,则扩展数据节点并重新训练模型
成本模型基于在每个数据节点跟踪的两个简单统计来预测平均查找时间和插入时间:(a)指数搜索操作的平均次数,以及(b)插入的平均次数
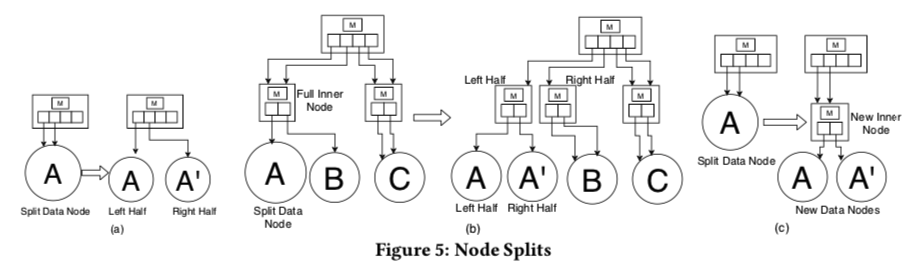
删除较为简单,但是如果数据节点由于删除而达到密度下限,则会收缩该数据节点(即与扩展数据节点相反),以避免空间利用率低。更新操作就是通过插入和删除操作实现。
其他:越界处理 / 大容量加载操作等等
测试结果
如前所言,各方面占优
总结
- 特点和性能优势
- ALEX解决了在为包含点查找、范围查询、插入、更新和删除的工作负载中Learned Index出现的实际问题
- 在只读工作负载上,ALEX击败了Kraska等人的原始学习索引。性能提高了2.2倍,索引大小减小了15倍
- 在各种读写工作负载中,ALEX比B +树(由STX B + 树实现)快4.1倍,索引大小也缩小了2000倍
- 性能局限性和未来研究方向
- ALEX当前设计是:in memory,single threaded,and on numerical keys;ALEX未来研究方向是支持persistence,concurrency,and string keys
- ALEX的模型对数据有一定要求,在不适用的数据模式性能会很差。具体而言,ALEX的前提是使用线性回归的集合对key分布进行建模。因此,当key分布难以通过线性回归建模时(即,key分布在小范围内高度非线性),ALEX的性能会很差。未来可能的研究方向是使用更广泛的建模技术(例如,还考虑多项式回归模型)
- ALEX可以在极端异常键的存在,这可能会导致关键领域和ALEX的树深度成为不必要的大。未来可能的研究方向是添加特殊逻辑以处理极端离群值,或者具有对稀疏关键空间具有鲁棒性的建模策略
- ALEX中额外参数众多,数据密度上下限、扇出因子、成本模型参数等等,如何调整以到达最佳性能也是一个问题
3. FITing-Tree: A Data-aware Index Structure
- 同RMI相比,FITing-Tree更追求实用性,分段线性函数结合树结构,细节可以参考《论文学习—FITing-Tree:数据感知的索引结构》
4. Learning Multi-Dimensional Indexes
- 纯机器学习里的方法,降维不可行,采用space filling curve,细节可以参考《论文学习—多维学习型索引》
5. RadixSpline: A Single-Pass Learned Index
当你凝望深渊时,深渊也在凝望你— 采采
说在前面
- 尽管Learned Index在大小和性能都能优于传统的索引,但是学习型结构一个比较大的问题就是构建训练比较慢,大多数方法都需要对数据进行多次训练
- RadixSpline,结合基树的思想,只需两个参数,在不影响性能的情况下,一次数据传递构建的学习索引
- 第一次提到了在LSM中构建Learned Index的可行性
- 首先,在LSM中做文件的索引是完全可行的,不需要单独的更新
- 其次,文件之间的compaction过程是重建/训练学习索引最佳时机,合并会进行排序产生数据,在将数据写回磁盘之前,可以通过单次的训练算法构建模型
- 由于合并操作本身是昂贵的,并且通常是异步进行的,所以训练这样一个一次性学习索引开销可忽略不计。然而,现有的学习索引不允许有效的构建
- RS只取两个超参数(spline err和radix table size),100以内的代码,简单且高效,在一次写入/多次读取的设置如LSM树)中性能极佳
RadixSpline 设计
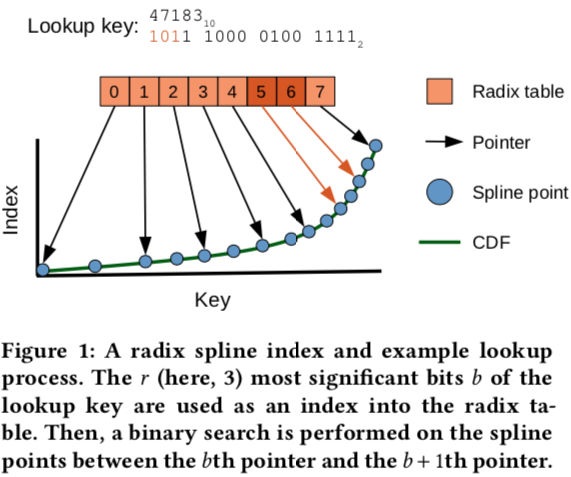
基本结构(Spline & Radix table)
- RS索引由两部分组成:一组Spline point和一个Radix table。spline点集是key的子集,经过选择后可以对任何查找键进行样条插值,从而在预设的误差范围内得出预测的查找位置。(例如,如果预设误差界限为32,则任何查找key的位置与RS索引预测的位置之间的距离不得超过32个位置。)
- Radix table有助于为给定的查找key快速定位正确的样条点。直观地说,Radix table限制了查找key的每个可能的某个长度(b-length)前缀的可能样条点的范围。
- 在查找时,Radix table用于确定要检查的样条点的范围。搜索这些样条点,直到找到围绕key的两个样条点。然后,使用线性插值来预测查找key在基础数据中的位置(索引)。因为样条插值是误差有界的,所以只需要搜索(小)范围的底层数据。
构建过程
- Build Spline:和传统Learned Index一样,构建一个模型S(ki ) = pi ±e,一种映射关系。这种模型,通过误差有界的样点插值算法实现(Smooth interpolating histograms with error guarantees)[17]
- Build Radix Table:类似基树/字典树/trie,一个uint32_t数组,它将固定长度的key前缀(“radix bits”)映射到带有该前缀的第一个样条点。key的前缀是基表中的偏移量,而样条点被表示为存储在基表中的uint32_t值(图中指针)。
- 首先分配一个适当大小的数组(2个条目),然后遍历所有样条点,每当遇到一个新的r位前缀b,我们就将样条点的偏移量(uint32_t值)插入基表中偏移量b处的槽中。由于样条点是有序的,基数表是从左到右连续填充的
- 用于sstable,利用共享前缀直接构建感觉很方便
- Single Pass:构建CDF、Spline和基表都可以在运行中进行,只需一次遍历已排序的数据点。当遇到新的CDF点时(即,当关键点改变时),我们将该点传递给Spline构造算法(Smooth interpolating histograms with error guarantees)。在同一过程中填充预先分配的基表也很简单:每当在选定的Spline点遇到新的r位前缀时,就在表中创建一个新条目
查找过程
- 首先提取查找key的r位前缀b(例中为101)。然后,使用提取的位b对基表进行偏移访问,检索两个指针
- 存储在位置b和b +1(此处为位置5和6)。这些指针(用橙色标记)在样条点上定义了一个缩小的搜索范围。接下来,使用二分搜索法搜索查找键周围的两个样条点。随后,在这两个样条点之间执行线性插值,以获得key的估计位置p。最后,在误差范围内进行一次二分搜索法运算,以找到第一个出现的键
性能分析和测试
略,总之蛮好的
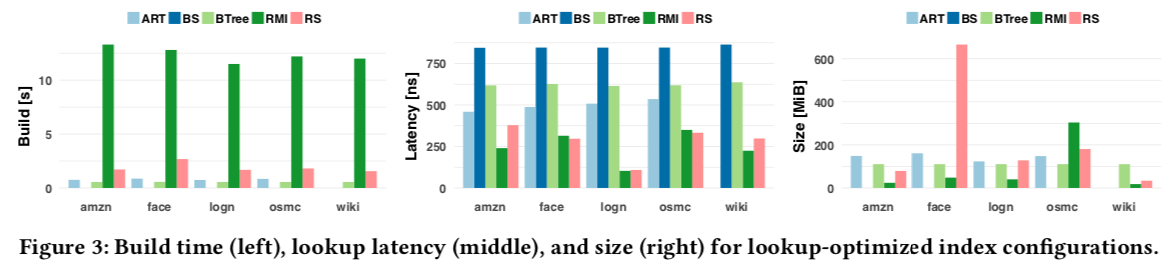
值得一提的一个测试,在RocksDB中用RadixSpline替换BTree index(?),使用osmc测试,执行400M个操作,50%读/50%写,单独写/读。RS写延迟提升4%,读延迟降低了20%,总执行时间从712s降到521s,内存减少45%,性能提升可能是为bloom filter和cache增大可用容量。只是初步尝试,后续可以完善。。
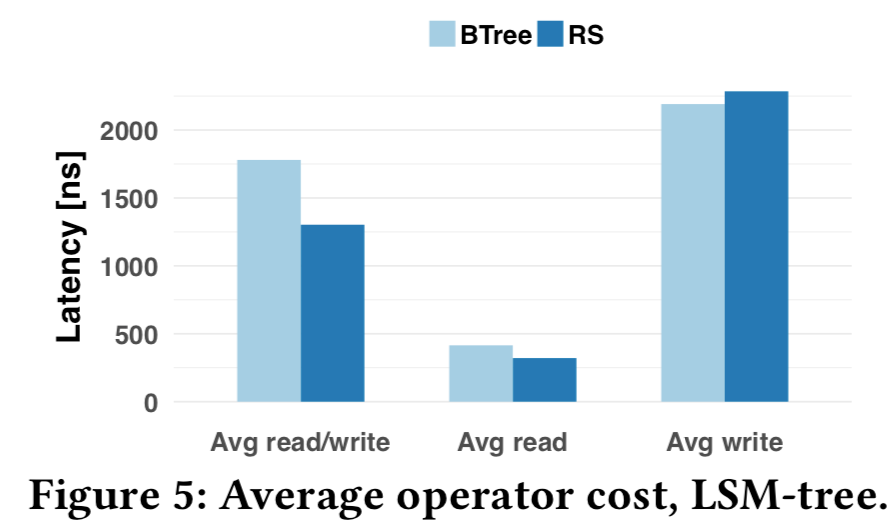
6. From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
不趁此时下手他,还到几时!正是先下手为强,后下手遭殃 — 承恩
说在前面
对于Learned Index只读场景的特性,适合构建/替代SStable索引和LSM中的Bloom Filter
- 已被osdi‘20收录,暂时没提供pdf,从arXiv中找到pre-print版《Learning How To Learn Within An LSM-based Key-Value Store》,论文细节参考《论文学习—Bourbon:在LSM中构建leanred index的案例》
- 论文绝大部分篇幅都在论证learned index用在LSM tree中的可能性和合理性,并提供指南
- 其实现的系统思路很简单,在Leveldb(rocksdb同理)中查找value过程可以分成两部分,二分查找key(indexing)和底层数据访问(data access),论文就是将learned index来替换传统二分查找过程,通过模型直接查找到value的position
- 论文中的learned index使用的是最简单的线性回归模型,当然考虑到数据的复杂性和模型的实用性,论文使用了piecewise linear regression(PLR,分段线性回归),训练模型使用了最简单的Greedy-PLR(贪心PLR,即如果不能在不违反错误限制的情况下将数据点添加到当前线段,则创建新的线段并将数据点添加到线段中)
- 测试效果上,基于WiscKey(他们认为是最先进的LSM的kv store)实现,与原始相比,提升性能1.23×-1.78×
- 从思路和做法来看,异常的简单和普通,效果也一般,只能说learned index可能真是机器学习和存储技术相结合的一种很好的思路(每年sigmod、vldb、atc等等都有好几篇相关的,Jeffrey牛逼!)
- 在看作者团队,好吧,Andrea C. Arpaci-Dusseau && Remzi H. Arpaci-Dusseau,看到这两个人就没什么可说的了
论文介绍
Wisckey(Leveldb)的查询过程包括:
- FindFiles(a):先在mem中查找memtable、immutable memtable,如果都不存在,则会在各level的sstables中查找。首先找出level上可能包含key的候选sstables,最差的情况是key可能出现在所有L0的文件中和其他所有层中的一个文件中;
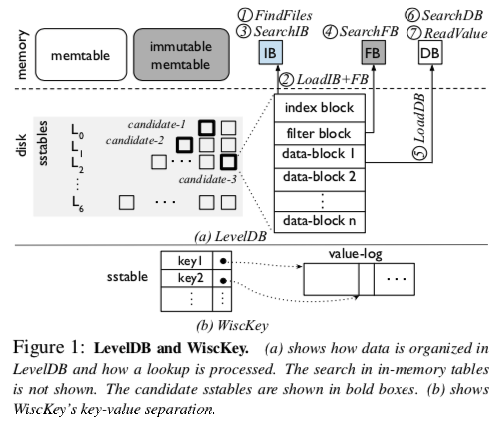
- LoadIB + FB(b):在候选sstable中,从disk中load上index block和bloom-filter block
- SearchIB(c):在index block中通过二分查找确定所在的data block
- SearchFB(d):通过bloom-filter来判断该data block中是否存在该key
- LoadDB(e):filter判断存在的话,加载data block
- SearchDB(f):在data block中通过二分查找确定k-v
- ReadValue(g):读取block中的value(是指向实际value的指针),然后读取该key对应的value
上述查找过程可以分成两部分
- indexing:a,c,d,f
- data access:b,e,g
- So,indexing部分可以通过learned index来替代,即sstable中构建key到value映射的模型
learned index必要性 && 合理性 && 实施指南
必要性(能提升多少):learned index可以降低索引开销,但不能降低数据访问成本,所以如果索引在总查找延迟中占相当大的比例,则学习索引可以提高整体查找性能。
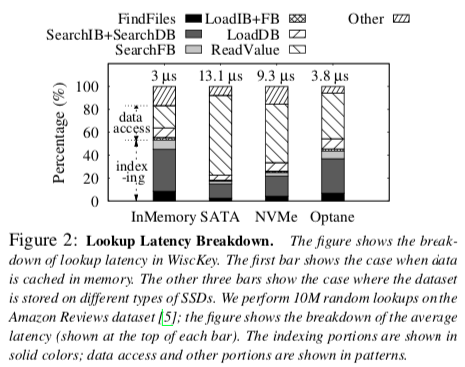
- 当数据集或数据集的一部分缓存在内存中时,数据访问成本很低,因此索引成本变得很高
- 随着设备速度的提高,查找延迟会减少,但用于索引的时间会增加。比如SATA固态硬盘,索引大约占总时间的17%;相比之下,使用Optane固态硬盘,索引需要44%,因此使用学习索引对其进行优化可以潜在地提高1.8倍的性能
- 随着存储性能的快速提高和3D Xpoint内存等新兴技术提供非常低的访问延迟,索引成本将占主导地位,因此学习索引将带来越来越多的好处
合理性(是否能进行):
- 对于只读分析工作负载,与传统索引相比,学习索引提供了更高的查找性能。然而,学习索引的一个主要缺点是它们不支持插入和更新等修改
- 修改的主要问题是它们改变了数据分布,因此模型必须重新学习;对于大量写入的工作负载,必须经常重新构建模型,从而导致高开销。学习索引似乎不太适合LSM-tree,LSM-tree由于出色的写性能往往用于大量写入场景
- 仔细分析(强行硬搞),LSM的设计很好地符合学习指标。虽然更新可以改变LSM-tree的一部分,但很大一部分仍然是不可变的。具体来说,新修改的项目被缓冲在内存结构中或出现在树的较高层,而稳定的数据驻留在较低层。假设数据集的大部分驻留在稳定的较低级别中,则无需重新学习或进行很少的重新学习就可以使对该部分的查找更快。 相反,较高水平的学习可能没有那么多好处:它们以更快的速度变化,因此必须经常重新学习
- 模型可以以sstable或者level单位来构建
实施指南(实验 && 构建方法)
实验的目标是确定一个模型能使用多长时间,以及它有多有用,测试分三部分:
- 只要sstable文件存在,为sstable文件构建的模型就有用,首先测量和分析sstable寿命
- 模型的使用频率由它所服务的内部查找数量决定,接下来测量每个文件的内部查找数量
- 由于模型也可以为整个level构建,最终也可以确定level生命周期
sstables的生命周期
- 较低级别的sstable文件的平均生命周期比较高级别的长;在较低的写入百分比下,甚至更高级别的文件也有相当长的生命周期;尽管随着写入次数的增加,文件的平均生命周期会缩短,但即使写入次数很高,较低级别的文件也会存在很长一段时间
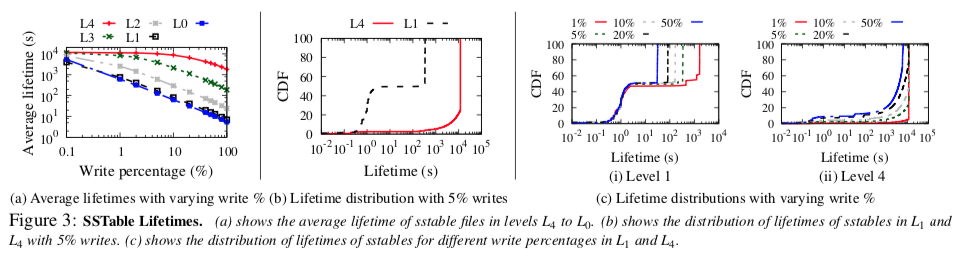
- 学习指南1—尽量学习较低level的文件
- 学习指南2—在学习一个文件之前等待,有很多文件存在周期很短,这些文件没必要学习。因此,只有在文件达到阈值寿命之后,才必须调用学习,在此之后,文件很可能会存活很长时间
不同level的内部查找数量
- 虽然大部分数据位于较低的级别,但较高的级别的内部查找数量较高。在更高的层次上,许多内部查找是负的,较低级别中的正向内部查找的数量较高
- 虽然bloom filters可能已经加快了这些负查找的速度,但仍需要搜索索引块(在过滤器查询之前)
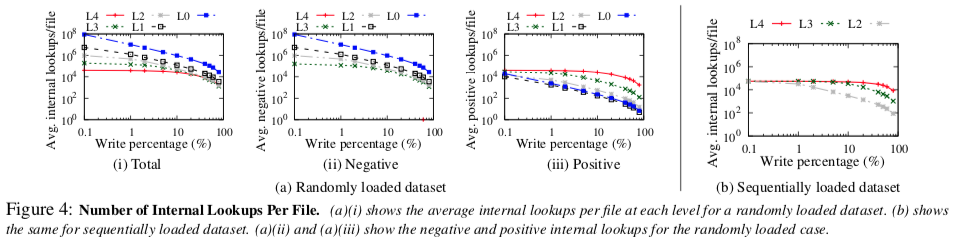
- 学习指南3—不要忽视更高level的文件,虽然较低level的文件寿命更长,可以进行多次查找,但较高级别的文件仍然可以进行多次负面查找。因此,更高层次的学习文件可以使负面查找更快
- 学习指南4—对工作量和数据有所了解,虽然大多数数据位于较低的级别,但是如果工作负载不查找这些数据,学习这些级别将产生较少的开销;因此,学习必须意识到工作量。此外,加载数据的顺序影响哪些级别接收大部分内部查找;因此,系统还必须具有数据感知能力。内部查找的数量充当工作负载和加载顺序的代理。根据内部查找的数量,系统必须动态决定是否学习文件
levels的生命周期
- 随着写入量的增加,一个级别的生命周期会缩短
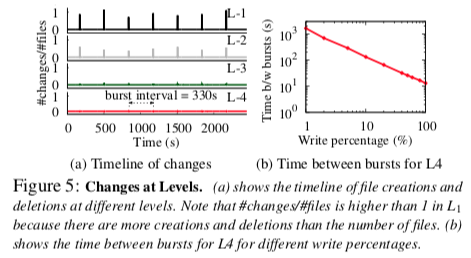
- 学习指南-5—不要学习大量写入工作负载的级别
具体实现— Bourbon,查找过程如下:
- FindFiles、LoadIB + FB
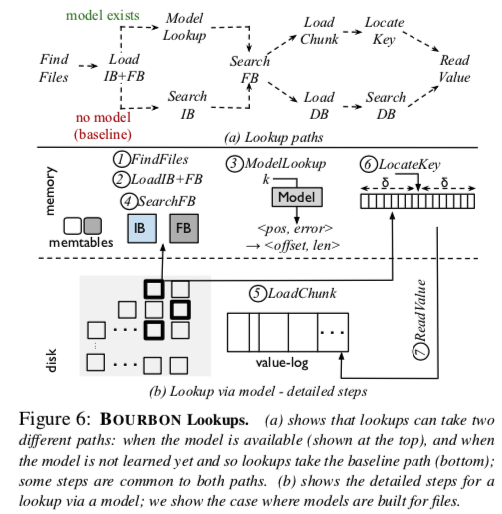
- 参考FITing-Tree,采用分段线性回归(PLR)模型,采用Greedy-PLR来训练,构建学习型模型
- 模型存在,则Model Lookup,否则Search IB,之后Search FB,load Chunk and Key
7. Leaper: a learned prefetcher for cache invalidation in LSM-tree based storage engines
平平淡淡才是真 — One
北京大学,vldb‘20 [18],采用机器学习方法解决X-Engine中cache miss问题
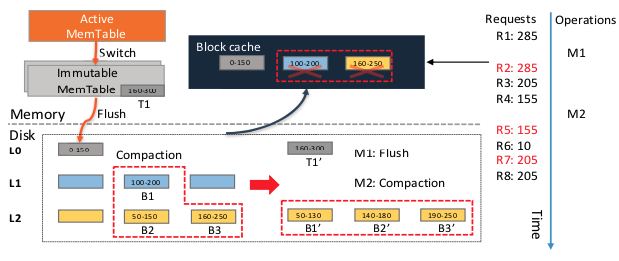
在X-Engine实际运行中,由于后台异步数据合并任务造成的大面积缓存失效问题。之前也有论文提出这种问题,具体解决是多增一个buffer cache,空间换效率。
Leaper采用机器学习算法,预测一个 compaction 任务在执行过程中和刚刚结束执行时,数据库上层 SQL 负载可能会访问到数据记录并提前将其加载进 cache 中,从而实现降低 cache miss,提高 QPS 稳定性的目的
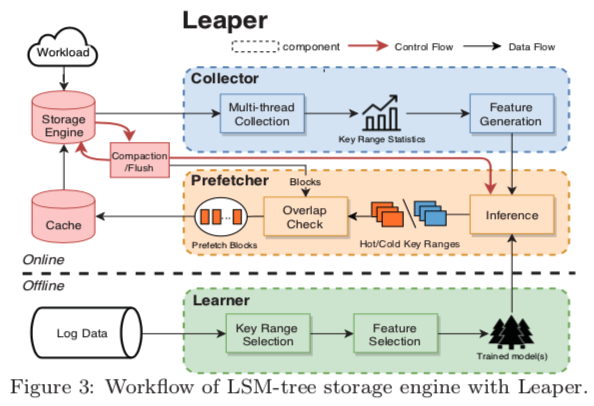
Leaper分成三个部分:Collector、Prefetcher和Learner
- Collector:收集数据和分key range
- Prefetcher:预测Hot key
- Learner:学习模型/训练
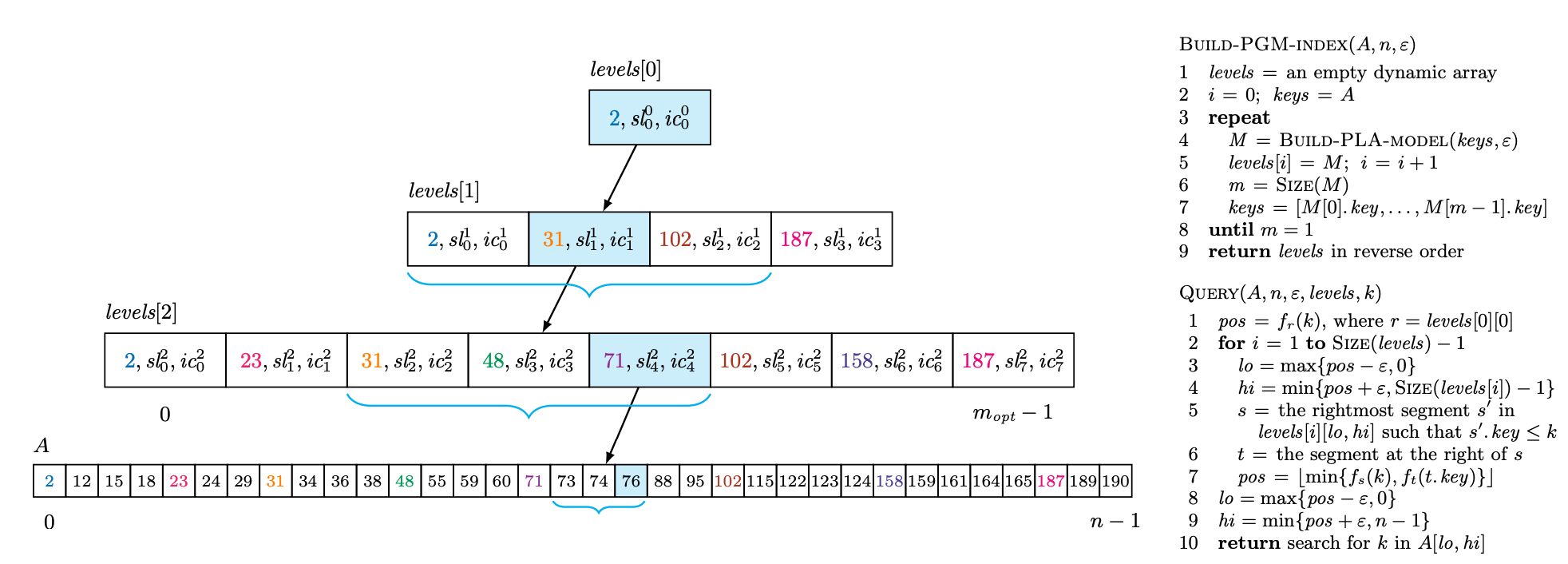
8. The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds
Source Code, VLDB’20, Paolo Ferragina(University of Pisa)
分段几何模型索引, 超高性能(比传统learned index提升三个数量级)
9. Partitioned Learned Bloom Filter
- 参考《论文学习—分区学习型Bloom Filter》
10. XIndex: A Scalable Learned Index for Multicore Data Storage
说在前面
- PPoPP‘20, 上交大IPADS, 不影响读性能高效率处理并发写
- leveraging fine-grained synchroniza- tion and a new compaction scheme 细粒度同步和新的压缩方案(Two-Phase Compaction), XIndex根据运行时工作负载特性调整其结构,以支持动态工作负载, 与Masstree和Wormhole相比,XIn- dex在24核机器上分别实现了3.2倍和4.4倍的性能提升
问题1: 写并发
- 并发写简单实现(增量索引 + 合并)
- 将所有写操作都缓冲到增量索引中,然后周期性地使用学习索引对其进行合并(包括将数据合并到一个新的排序数据数组和重新训练modls)
- 增加了增量索引,内存开销和查找耗时都增加很多
- compaction会阻塞并发请求
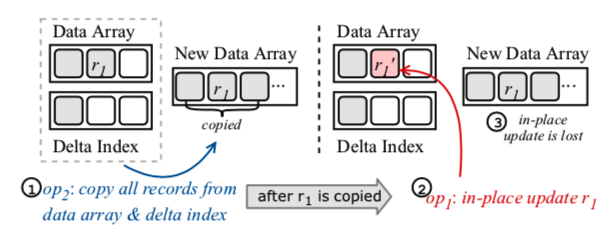
- 一种优化
- in-place更新, 的只有新插入的记录在增量索引中
- 后台线程异步合并
- 由于与后台合并的数据竞争,更新的效果可能会丢失
- 其中操作op1更新记录r1,操作op2并发地将增量索引和学习过的索引合并到一个新的数据数组中。通过以下交错操作,op1对r1的更新会因为并发压缩而丢失:1) op2开始压缩,将r1复制到新的数组中;2) op1更新原阵列中的r1;3) op2完成压缩,更新数据数组,重新训练模型
问题2: 数据分布
learned index的性能与工作负载特征紧密相关,包括数据和查询分布
查询效率取决于error bounds(误差界),不同的模型误差界也不同
- 在统一的查询分布下,所有的键都有相同的访问机会
- 在Skewed的查询分布下,95%的查询访问5%的热记录,并且每个工作负载的热记录位于不同的范围内。“Skewed1”从排序数据数组的第94%到第99%选择热键。“Skewed2”从第35%到第40%个选项中选择,而“Skewed3”从第95%到第100%个选项中选择。
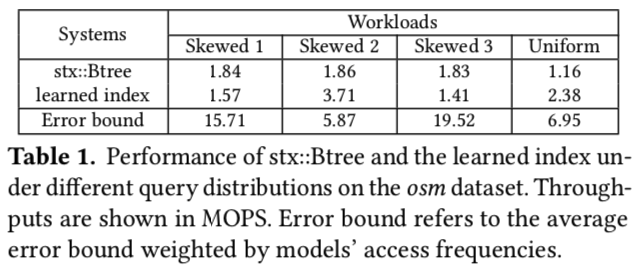
- 在工作负载为“Skewed1”和“Skewed3”的情况下,learned index对于频繁访问的记录有更高的平均误差界,这将阻碍查询性能
- 其根本原因是,learned index只将每个模型的误差单独最小化,而没有考虑模型的精度差异
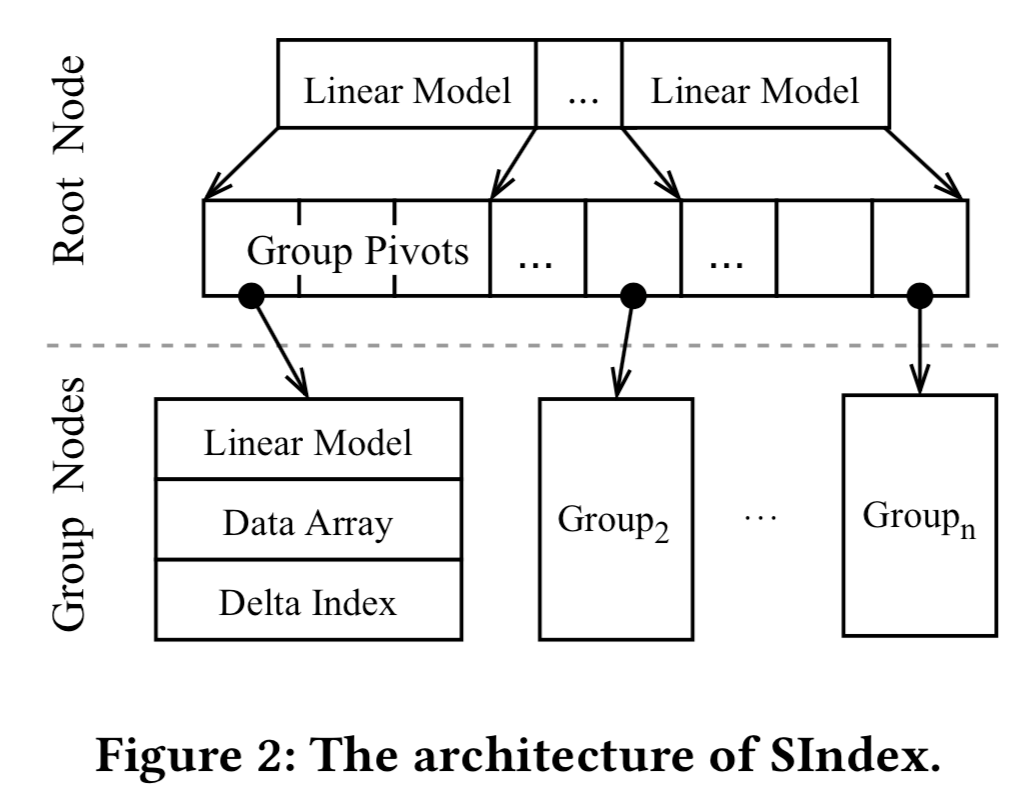
Xindex架构
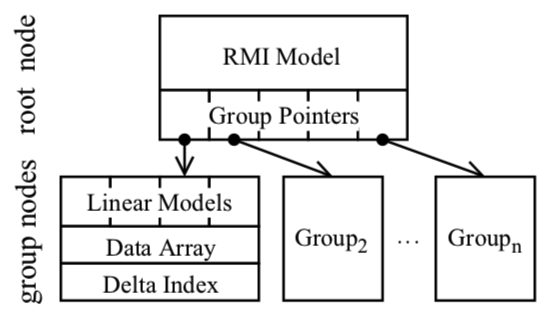
基本结构
- XIndex采用两层架构设计,顶层包含一个根节点,根节点对底层所有group节点进行索引,数据通过范围分区进行分组
- 根节点使用一个RMI模型
- 每group节点使用线性模型对其数据进行索引。对于写操作,XIndex对现有记录执行原地更新,并将每个组与一个delta索引关联起来以进行缓冲区插入
two phase compaction
- merger: XIndex将当前数据数组和增量索引合并到一个新的数据数组中。XIndex在新的数据数组中维护数据引用,而不是直接复制数据。每个引用指向正在压缩的记录,这些记录驻留在旧数据数组或增量索引中
- copy: 在确保没有通过RCU barrier访问旧数据数组之后,XIndex执行复制阶段。它将新数据数组中的每个引用替换为实际值
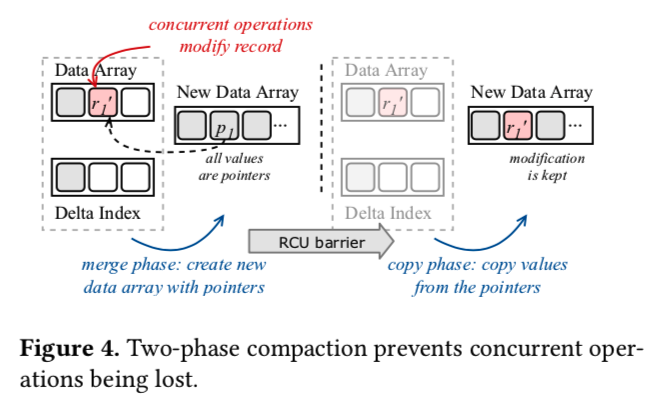
- 在合并阶段之后,新的数据数组包含对每个记录(r1)的引用(p1)。如果有一个当前写入器将r1更新为r1 ‘,那么写入器可以安全地继续,因为记录已经在新的数据数组中被引用了。在RCU barrier之后,没有线程将访问旧的数据数组。XIndex在复制阶段用r1 ‘替换p1
动态调整
- 根据运行时的工作负载动态调整其结构
Learned Indexes for a Google-scale Disk-based Database
三、总结与思路
为什么不问问神奇海螺呢 — 阿宝
| 论文 | 问题 | 方法 | 团队 | 会议时间 |
|---|---|---|---|---|
| Learned Index | 传统索引不能很好的感知数据特点,性能有限 | 机器学习模型替代传统索引 | Tim Kraska && Jeff Dean | sigmod‘18 |
| FITing-Tree | learned index空间优化 | 分段线性函数结合树结构 | Tim Kraska | sigmod‘19 |
| CDFShop | learned index没提供代码 | RMI自动构建 | Tim Kraska | sigmod‘20 |
| ALEX | learned index只支持只读场景 | 每个模型管理自己数据&优化结构 | Tim Kraska | sigmod‘20 |
| MultiDimensional | learned index只支持一维数据 | space filling curve | Tim Kraska | sigmod‘20 |
| RadixSpline | learned index训练复杂 | 条带点和基表可以一次训练构建 | Tim Kraska | sigmod‘20 |
| XIndex | learned index只支持单线程,不能够并发 | 两层结构,数据分段处理 | 陈海波 | PPoPP‘20 |
| Xstore | learned index在基于RDMA的KVs中缓存应用 | 构建learned cache加速RDMA | 陈海波 | Osdi’20 |
| Bourbon | learned index在基于LSM的KVs中的索引加速 | 用于sstable中来加速二分查找过程 | Andrea C. && Remzi H. Arpaci-Dusseau | Osdi’20 |
| PGM-index | 高性能Learned index | 分段几何模型索引 | Paolo Ferragina | Vldb‘20 |
突然迷失,就很气,在找到论文7之前,我们也想将learned index / succinct trie / others来加速二分查找过程,通过索引或者模型来直接定位value,当然要保证索引的空间和速度;另一方面,想着compaction过程是构建模型的好时机,很气
将很多优化的,尤其是ALEX & RS用在LSM中,是非常适合的,这方面可以做的很多
第二种思路就是抛弃LSM tree一些基本结构,单独建立索引结构用于读取,底层的SStable / level结构需要重新设计,类似于SLM-DB
- 第三种思路,优化上面论文(例如sosp 19提出了KVell,osdi 20立刻有人提出了KVell + ),优化思路主要可以包括:
- 首先是对learned index的优化,可以参考《Learned Index: A Search Space Odyssey》,首先是模型本身的优化(包括模型的选择、参数调整、训练算法、GPU/TPU等硬件优化等等,主要提高模型的准确度、训练速度,减少空间大小、索引消耗等等)
- 另一方面就是在index方面的优化,比如如何适用于更新 / 写数据频繁的场景(参考ALEX),如何减少模型重新训练次数和其开销,如何减少error miss和即使出现miss如何最小化开销等等
- 进一步的,如果使用ALEX等优化的索引,也要对ALEX进行完善和优化(参考论文分析中对ALEX的总结),一大方向是多线程和持久化的支持
- 构建learned index的方式,和使用learned index的地方。首先,论文中对learned index训练数据的选择是以SStable为单位的,也提供以level为单位,只对查找SStable过程进行优化。是否可以将index的范围做大,包括memtable之类的(当然要评估是否反而会拖慢)
- 另外就是感觉关注点小了,能不能把这种技术放大,放到crush、ceph来?
四、设计与实现
ABOUT X
一些结论
- learned index中lr模型是训练、性能、空间等方面是有提升的
- 数据量比较大的情况下, 对比传统索引提升明显
- 目前稳定版本存在两个明显缺陷: 不支持动态操作(动态操作容易导致频繁重训练) ; 预测结果需要连续且有序
训练时间
load_db -> train_x (可选);
后台主线程判断 in_retrain 是否进行(重)训练
- handlers::retrain
- 来着clients的RPC, 会使得整个模型进行重训练
- xcache::train_dispatcher && train_submodels
后台三个线程特定模型的(重)训练
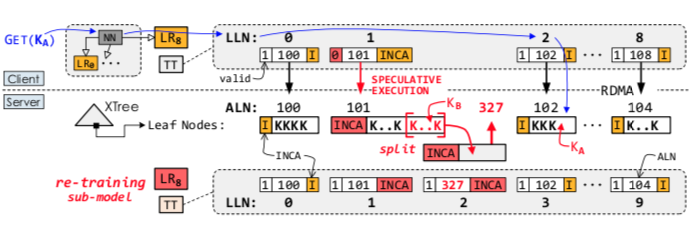
- 维护三个队列,每次要重训练将请求加入队列,后台三个线程处理队列请求
- 重训练: train_submodels
- 触发条件: split
- handlers::insert
- model.notify_watermark > model.train_watermark / check
- safe_get_with_insert_check_split
- Update / remove 不触发
- handlers::insert
- 训练数据
- cdf[]
- Data: key ; Label: LLN ; config
- TT: LLN -> (pageid, index) -> address
- 选择模型
- MKL && model_config
- index_factory -> Marshal::learned_index -> rmi
- smart_cache -> Marshal::learned_index -> rmi
- xcache -> mod && sub_mode -> lr
- 训练模型
- 第一层(model0) & 第二层(submodels)
- xcache::train_dispatcher && train_submodels
- lr::train
使用模型(get、scan) && 训练时间和精度统计
- r2::compile_fence()
TODO
对应于LSM-tree, 如果为每个sstable维护一个model
- 训练时间
- 后台: 生成sstable时 / compaction
- 训练数据
- sstable中key && pos
- 模型
- index_factory -> Marshal::learned_index -> rmi (MKL) & r2
- 只能int、单线程、in memory, 提供string key的情况
- xindex、ALEX、RadixSpline…
- int、并发
- 持久化
整个LSM-tree维护一个model
- 动态操作 -> 重训练
五、测试
模型
- rmi
- alex
- radixSpline
- xstore
./test_model -db_type ycsb –threads 24 –id 0 -ycsb_num=100000000 –no_train=false –step=2 –model_config=ae_scripts/ycsb-model.toml
负载 key num Key_size train_time(top) sub_model num train_time(sub) error Page entry Model_size CPU ycsb 100000000(100M) 4.47 GB 2.50145e+06msec 100000 3.40863e+06 0.41285 126 1.71661M 146/600 ycsb 200M 8.9407 4.60327e+06 100000 8.33398e+06 0.35576 247.87 1.71661 163/600 ycsb 200M 8.9407 5.35364e+06 10000 2.64878e+06 0.3315 2501 0.1716 162/519 ycsb 200M 8.9407 4.31363e+06 200000 1.03307e+07 0.45051 126 3.43323 162/600 Ycsb-64 200M 8.9407 4.6973e+06 100000 8.6688e+06 0.35576 251 1.71661 200/600 Ycsbh 200M 8.83315 4.68928e+06 100000 7.66754e+06 61.6619 249 1.71661 162/600 dummy 200M 8.83315 5.53296e+06 100000 4.9552e+06 61.6619 247.87 1.71661 162/600 TPCC/NUTO xindex:支持并发
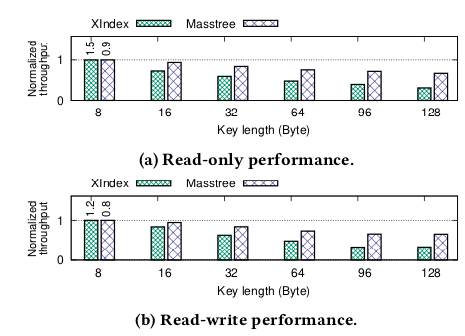
sindex:支持string类型
参考文献
[1] Chai MK, Fan J, Du XY. Learnable Database Systems: Challenges and Opportunities[J]. Journal of Software, 2020, 31(3): 806-830
[2] Kraska, Tim, et al. “Sagedb: A learned database system.” CIDR. 2019.
[3] Kraska, Tim, et al. “The case for learned index structures.” Proceedings of the 2018 International Conference on Management of Data. 2018.
[4] Galakatos, Alex, et al. “Fiting-tree: A data-aware index structure.” Proceedings of the 2019 International Conference on Management of Data. 2019.
[5] Ding, Jialin, et al. “ALEX: an updatable adaptive learned index.” Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
[6] Nathan, Vikram, et al. “Learning Multi-dimensional Indexes.” Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
[7] Marcus, Ryan, Emily Zhang, and Tim Kraska. “CDFShop: Exploring and Optimizing Learned Index Structures.” Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
[8] Ferragina, Paolo, and Giorgio Vinciguerra. “The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds.” Proceedings of the VLDB Endowment 13.8 (2020): 1162-1175.
[9] Kipf, Andreas, et al. “RadixSpline: a single-pass learned index.” arXiv preprint arXiv:2004.14541 (2020).
[10] Vaidya, Kapil, et al. “Partitioned Learned Bloom Filter.” arXiv preprint arXiv:2006.03176 (2020).
[11] Dai, Yifan, et al. “Learning How To Learn Within An LSM-based Key-Value Store.” arXiv preprint arXiv:2005.14213 (2020).
[12] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[13] ComboTree
[14] Li X, Li JD, Wang XL. ASLM:Adaptive single layer model for learned index.In:Proc. of the 24th Int’l Conf. on Database Systems for Advanced Applications (DASFAA 2019), 2019, 80-95.
[15] Tang CZ, Dong ZY, Wang MJ, et al. Learned indexes for dynamic workloads. CoRR, abs/1902.00655, 2019.
[16] M. A. Bender, M. Farach-Colton, and M. A. Mosteiro. Insertion sort is o(n log n). Theory of Computing Systems, 2006.
[17] T. Neumann and S. Michel. Smooth interpolating histograms with error guarantees. In Sharing Data, Information and Knowledge, 25th British National Conference on Databases, BNCOD ’08, pages 126–138, 2008.
[18] Yang, Lei, et al. “Leaper: a learned prefetcher for cache invalidation in LSM-tree based storage engines.” Proceedings of the VLDB Endowment 13.12 (2020): 1976-1989.
[19 ] Kraska关于Learned Index精彩的演讲:https://www.youtube.com/watch?v=qFbw4MgR6pI