
Smartnic survey
SmartNIC Survey
世上本无难事,全在人为布局罢了—— 贾诩
Overview
Background
现有网络带宽逐渐从10GbE增长到100GbE,但同时CPU计算能力增长逐渐缓慢,使得分布式系统的性能瓶颈逐渐从网络转向了CPU。CPU无法提供能够完全利用高速网络带宽的计算能力。因此出现了新的带有计算能力的硬件,这些硬件带有专有的加速器,FPGA或者ARM核心,可以实现将部分CPU的负载进行offload,从而释放更多的CPU资源给应用
SmartNIC即为带有计算单元的网卡。根据计算单元的不同通常有三类SmartNIC,分别是流处理器(ASIC),FGPA以及ARM。这三类SmartNIC性能逐渐下降,但是可定制能力逐渐上升。其中基于ARM的SmartNIC可以直接运行完整的Linux并且支持基于C的编程
Products
常见厂商都推出了相应的SmartNIC产品:
| 厂商 | 型号 | 类型 | |
|---|---|---|---|
| Intel | Intel IPU C5000X / N3000 | FPGA |  |
| Nvdia/Mellanox | BlueField-2 | ARM |  |
| Xilinx | Alveo U25 | FPGA |  |
| Marvell | LiquidIO | ARM |  |
| Broadcom | Stingary PS250 | ARM | 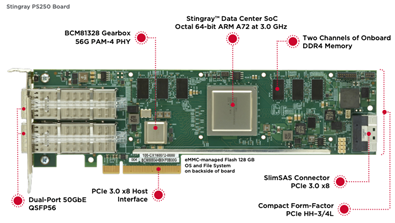 |
Deployment
SmartNIC部署的位置决定了进行offload的方式。SmartNIC可以仅部署在client端,仅部署在Server端,或者client和server都部署。
SmartNIC仅部署在Server端(SIGCOMM’19 iPipe)这种结构下,client配备普通的NIC,请求没有额外的处理发送到Server端的SmartNIC。
Client与Server端都部署的方式常见于Client-local的系统设计(SOSP’21 LineFS,SOSP’21 Xenic),每个client既是自己的client也是其他client的server。通过将部分的分布式功能offload到SmartNIC上降低host CPU的负载。
仅部署在Client端这种方式还没有见到;
Classification
论文中的SmartNIC根据packet被处理的路径主要两类:on-path和off-path:
| On-path | Off-path | |
|---|---|---|
| 结构 | 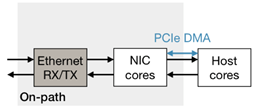 host的请求通过SoC转发 host的请求通过SoC转发 | 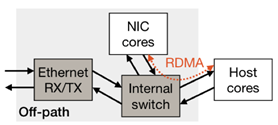 host和NIC互相独立的实体,可以被单独访问,请求通过NIC switch转发 host和NIC互相独立的实体,可以被单独访问,请求通过NIC switch转发 |
| 主要特点 | SoC暴露底层接口:Ethernet RX/TX queue,packet buffer management,packet scheduling,ordering module,PCIe DMA engine; | SoC运行完整Linux以及网络栈,不暴露底层接口; |
| 如何offload | 在packet processing pipeline中增加逻辑 | 指定请求发送的位置 |
| 如何访问host memory | PCIe DMA | RDMA |
| Limitation | offload与packet processing竞争SoC资源影响性能 | SoC访问Host memory延迟较高 |
Performance
NIC-NIC throughput
SIGCOMM’19 iPipe:
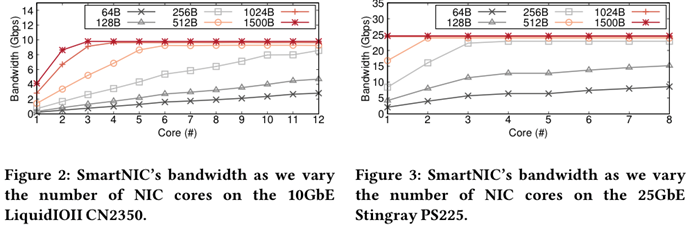
测试结果:64B/128B小请求下无法达到最大带宽,说明NIC的计算能力不足以满足充分利用网络带宽的需求,并且带宽越高对计算能力需求越高;
SOSP’21 Xenic: 80B UDP packet,16threads,NIC RPC吞吐最高71.8Mops/s,host RPC吞吐最高23Mops/s;
SIGCOMM’19 iPipe:
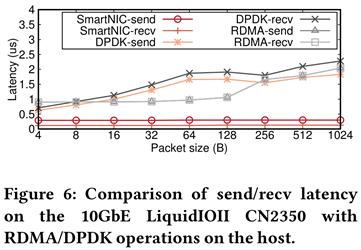
SmartNIC上的send/recv比DPDK快4.6\times,比RDMA send/recv快4.2\times,主要原因是on-path SmartNIC具有硬件加速的packet buffer,因此处理packet比host更快;
Latency
on-path:
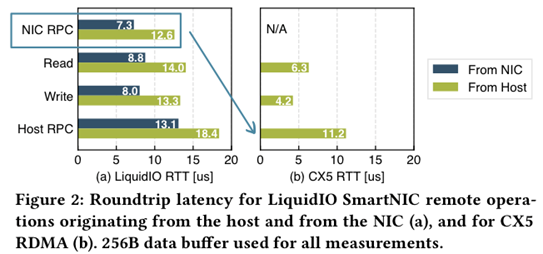
NIC RPC延迟比Host RPC更低,验证前面带宽的测试结果;
off-path
SOSP’21 Xenic:
Bluefield 1M332A RDMA write到host memory延迟为3.5us,写到NIC memory延迟为4.5us,NIC写到host memory延迟为5.1us;
SIGCOMM’19 iPipe:
RDMA read/write是blocking DMA的两倍左右的延迟;小于256B的请求,RDMA read/write只有blocking DMA的1/3带宽,超过256B接近;
off-path的SmartNIC通过RDMA访问host memory延迟更高;
PCIe
DMA:

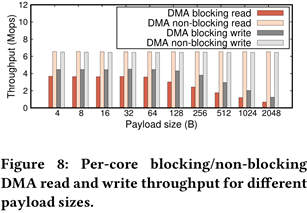
iPipe:non-blocking DMA能够实现更高的带宽以及更低的延迟,可以利用DMA的scatter/gather聚合PCIe的请求;
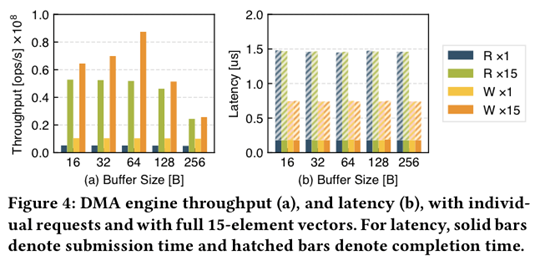
Xenic:利用batch(vector)能够提升DMA带宽,并且不会影响DMA请求延迟;
Compute Performance
iPipe:SmartNIC的ARM core计算能力弱于一般host server上的CPU,但是SmartNIC配备有特殊的硬件加速器,对于某些特定的负载,能够比host CPU处理得更快,比如压缩/解压缩,加密算法,hash等;
Xenic:
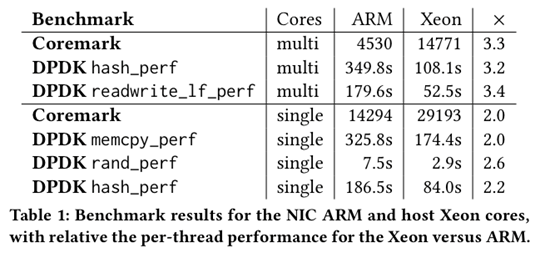
ARM比Xeon core慢2~3.3\times;
BlueField-2 Related
SW and HW:

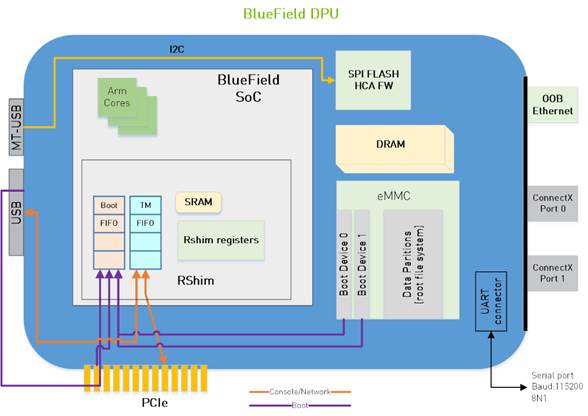
Interface
Structure
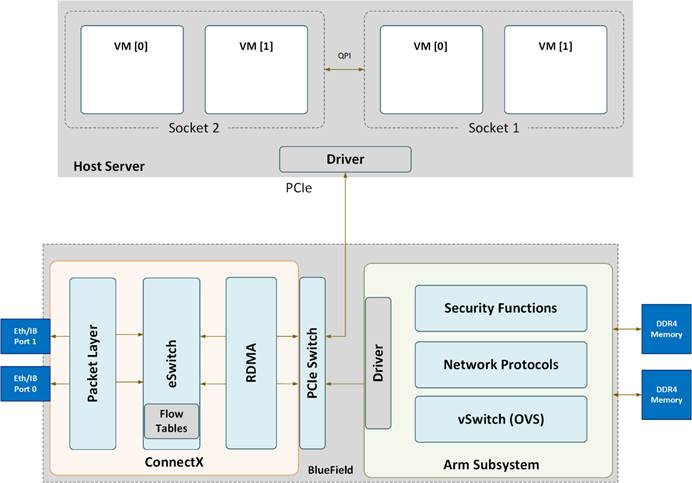
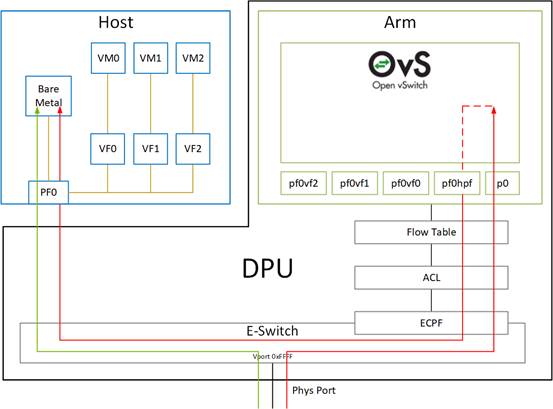
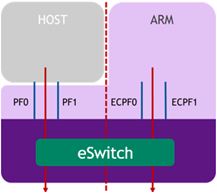
应该是off-path的结构,因为有一个PCIe switch管理packet的转发;
Mode
l Embedded function (ECPF / DPU) :ARM core控制NIC的资源以及data path(这个模式又有点类似于on-path),也可以通过配置offload的方式将路由规则offload到switch(ConnextX)实现直接将请求发送给host;
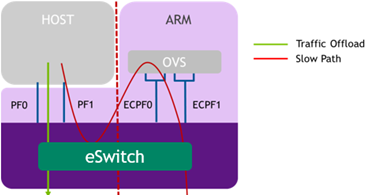
l Restricted mode which is an extension of the ECPF ownership with additional restrictions on the host side
l Separated host mode:此时host以及ARM系统相互独立,独立的IP和MAC;
Performance
\1. pktgen:运行到SmartNIC上,只能实现约60%的带宽,验证前面测试,SmartNIC的计算能力无法完全利用网络带宽;
\2. ECPF模式下,ARM CPU最高占用75%~82%,使用DPDK可以降低5.5%~12.5%的CPU占用;
\3. 避免访问local storage / fs,以及CPU计算较多的负载offload,避免使用内核网络栈;
Related Work
SIGCOMM’19 iPipe:一个基于Actor Model的SmartNIC编程框架,对标DPDK;
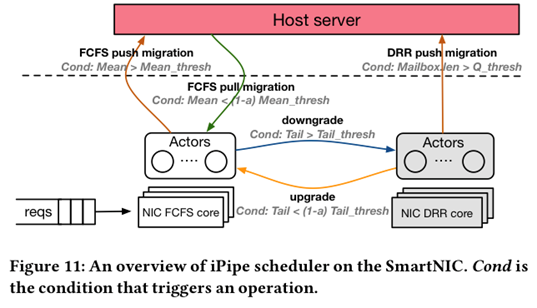
核心设计:
\1. 结合FCFS/DRR和task调度策略;
\2. host+NIC混合的对象管理系统;
\3. actor之间的security隔离;
SOSP’21 Xenic
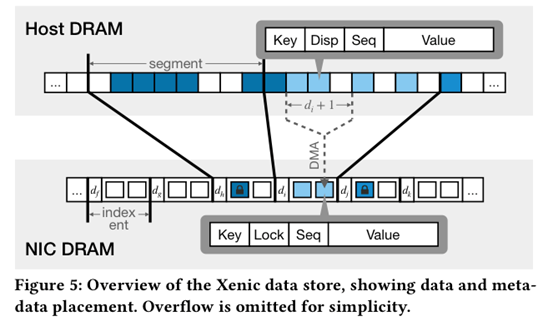
核心思想:将分布式事务的逻辑offload到SmartNIC上;
Design
Target Environment:disaggregated memory(persist)
Background:
KV-Direct:将KV完全做到SmartNIC内部,但是根据前面的测试来看,NIC core的处理能力有限,完全将KV store offload到NIC内部不是一个理想的方式;
RACE:完全利用单边RDMA的一个hash,为了实现无锁大量使用了RDMA atomic,并且每次读操作都需要读128B。除此之外,Resize在远端执行需要较大的CPU开销;
Design goal:利用SmartNIC协助hash table,降低read,concurrency control以及resize开销;