
Ceph-数据丢失研究
青山无数,归去又还秋暮,算恁地光阴,能来得几度 —— 老俞
目标1:当出现坏盘,如何减少数据丢失
目标2:灵活,可拓展性强,能处理数据扩容/迁移
数据丢失问题
随机复制数据丢失率非常高,HDFS的例子
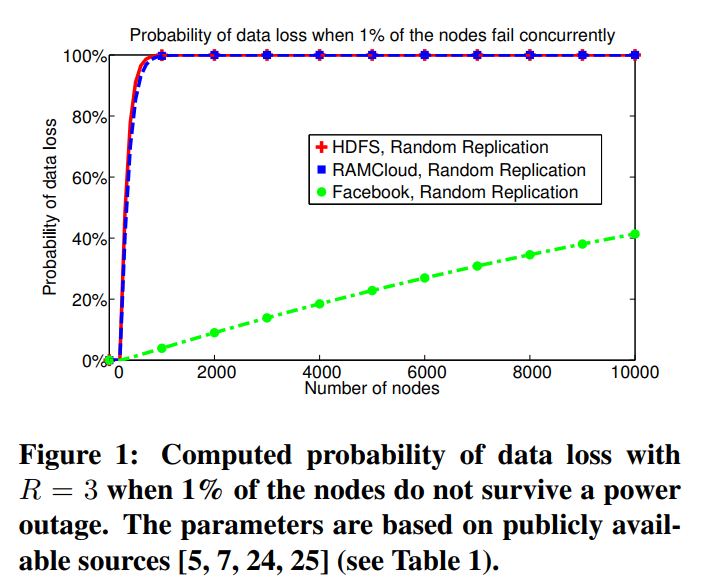
In CRUSH:三副本,坏三个OSD,一定有数据丢失?(前提是数据量足够大)
- 丢失PG的概率的公式:P = Pr * M / C(N, R)
- Pr表示R个(副本数)OSD故障的概率,跟它关联的因素有OSD硬盘故障概率及恢复(Recovery)期间其他(R–1)OSD的故障概率。M表示copyset组合数,PG映射到一组OSD里表示copyset,如pg 2.3 → [2, 3, 1]
- C(N, R) 表示N个OSD中,任意R个OSD的组合数
- 从公式看,C(N, R) 对于一个既定的Ceph集群值是不变的 (从侧面也证明副本数越多,集群规模越大,PG丢失的概率也越低),所以尽量缩小Pr、M的值
- 减少Pr值:一是缩小OSD硬盘的故障率,二是缩短恢复的时间。缩小OSD故障率就是选择可靠的硬盘
- 关于copyset数量M,当PG数量足够多,M >= C(N, R)
- 减少M?
From Copyset Replication to Tiered Replication
- 作者Asaf Cidon 斯坦福毕业,哥伦比亚大学教授(https://www.asafcidon.com/)
- 与FaceBook合作,Tectonic作者之一
论文1—Copysets: Reducing the Frequency of Data Loss in Cloud Storage
ATC‘13 Best Paper
为了解决 Random replication 的问题,有人提出了 Copysets,也就是论文 Copysets: Reducing the Frequency of Data Loss in Cloud Storage,相比于使用 random 方式,Copysets 引入了 scatter width,将整个集群节点进行分组,然后在分组的集合里面选择节点进行复制。
Copysets 的算法其实比较简单,假设集群数量是 N,复制因子是 R(其实就是选择几个副本),scatter width 是 S,那么:
- 创建
S / (R - 1)个节点排列 - 将每个排队分成 R 组
- 随机选择一个节点当成副本的 primary 副本
- 在分组的包含 primary 节点的集合里面随机选择 secondary 副本
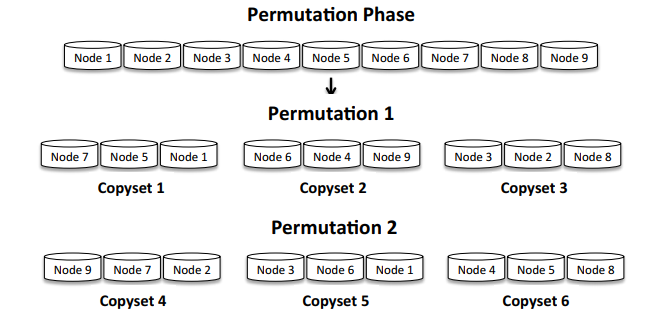
- 创建
譬如,假设我们有 9 个节点,R 是 3,而 S 是 2,那么就有
2 / (3 - 1) = 1个排列,譬如[1, 6, 5, 3, 4, 8, 9, 7, 2],然后我们分成 3 组,也就是[1, 6, 5], [3, 4, 8], [9, 7, 2]。对于 3 副本,假设我们选择 1 作为 primary 副本存放的节点,那么剩下两个 secondary 副本只能在 6 和 5 上面选取。
使用 Copysets,能有效的降低丢失数据的概率,根据 Paper 里面描述,在 5000 个节点下面,如果有 1% 的节点同时挂掉,random 丢失的概率是 99.99%,而 Copysets 则是 0.15%
论文2—Tiered Replication: A Cost-effective Alternative to Full Cluster Geo-replication
- ATC‘15,copeset replication并不能解决集群动态扩容的问题
- Tiered Replication 的原理其实也比较简单:
- 所有节点开始的 scatter width 是 0,也就是没有属于任何 Copysets
- 创建一个 Copysets,选择最小 scatter width 的 R 个节点加进去
- 重复上面的过程,直到所有的节点的 scatter width 至少是 S
- Tiered Replication 里面也有 primary 和 backup 节点的区分,通常两个副本会放在 primary 节点里面,而第三个副本则会放backup 节点里面
- 对于集群的动态更新,譬如新加入一个节点,就直接按照上面的算法,将这个节点加入到不同的 Copysets 里面,直到这个新加入的节点的 scatter width 为 S
- 对于删除节点,一个简单的做法就是将包含这个删除节点的 Copysets 干掉,而在这些 Copysets 里面的其他正常节点的 scatter with 也会减少,然后会创建新的 Copysets 替换老的。在老的 Copysets 里面的正常副本可能会重新复制到其他节点上面
应用
HDFS
Curve
- 关于S的设定
- 总恢复带宽 = scatter width * 单个copyset的恢复带宽
- scatter width = 总的恢复带宽 / 单个copyset的恢复带宽 = (数据容量 / 期望恢复时间)/ 单个copyset的恢复带宽
- 假设节点每个盘4T,恢复时间3600s,单个copyset的恢复带宽为10MB/s,那么S = (4 * 1024 * 1024) / 3600 / 10 = 116.51,这是scatter width的下限
- 关于扩容
- 物理池physicalPool是扩容的基本单元,也就是一次扩容一个physicalPool。物理池内包含若干台服务器,每台服务器上具有若干个ChunkServer节点
- logicalPool:在物理池之上,会创建logicalPool和copyset。copyset属于逻辑池,每个逻辑池一开始创建固定数量的copyset。copyset Id 在逻辑池内唯一,逻辑池Id + copyset Id 唯一确定一个copyset
- 关于S的设定
TiKV
- 打 label ,假设有 3 个 Rack,每个 IDC 有 3 台机器,会给每个启动在机器上面的 TiKV 进程打上类似
rack = rack1, host = host11这样的标签 - PD 就会将 3 个副本分散到不同 Rack 的不同机器上面,但在 Rack 机器的选择上面,还是一个 random 算法。也就是说,即使能保证副本在不同的 Rack 上面,但随着每个 Rack 机器数量的增多,我们 3 副本同时丢失的概率就会增大,所以自然需要一个更好的副本复制策略
- 打 label ,假设有 3 个 Rack,每个 IDC 有 3 台机器,会给每个启动在机器上面的 TiKV 进程打上类似
思考
- 是否可以运用于Ceph?