
存储优化专题总结
We don’t stop playing because we grow old. We grow old because we stop playing — George Bernard Shaw
[TOC]
专题1 Disaggregated Memory
发展
- 网络:RDMA(Remote Direct Memory Access)
- 存储:non-volatile DRAM,PM
- 存算分离架构
问题总结:
- 提高资源利用率、负载均衡、弹性、异构性和容错性,降低成本,提高效率(Resource Disaggregation)
- LegoOS,AsymNVM,FileMR,Clover,AsymNVM,GAM
- 内存需求、内存限制、提高性能(Remote Memory):现代数据密集型应用程序因内存限制性能遭受损失,但大型集群中因无法在机器边界之外访问内存,使得内存未充分利用
- FaRM,FaRMv2,Leap,XMemPod,TH-DPMS,Clio
- For AI:GPU,CPU内存墙,提高性能
- DC-DLA,XMemPod
1. DSM over RDMA
- [NSDI’14] FaRM: Fast Remote Memory && [Sigmod ‘19 FaRMv2] Fast General Distributed Transactions with Opacity
- Microsoft Research,内部商用
- DRAM 价格的下降使得构建具有数百 GB DRAM 的商品服务器变得更具成本效益。 一个一百台机器的集群可以容纳几十TB的主存,这足以存储许多应用程序的所有数据,或者至少可以缓存应用程序的工作集
- 利用 RDMA 和大容量内存等新的数据中心的特点来封装一个存储池层,为上层数据结构设计提供统一的空间编址、海量数据存储、基于多副本的可靠性等服务,以简化上层分布式存储应用的构建难度
- 想统一的利用集群内存,物理机器之间的网络即TCP/IP网络成为了瓶颈
- FaRMv2:云数据中心提供许多相对较小的、单独不可靠的服务器。云服务需要在这些服务器的集群上运行,以在单个服务器出现故障时保持可用性。它们还需要向外扩展,以增加超过单个服务器的吞吐量。对于需要在主存中保存数据的对延迟敏感的应用程序,还需要扩展到超出单个服务器的内存限制
[OSDI ‘18 best paper] LegoOS: A Disaggregated, Distributed OS for Hardware Resource Disaggregation
Yiying Zhang团队,UCSD
资源利用率:数据中心面临着将应用程序安装到物理机器上的一个困难的装箱问题。由于一个进程只能在同一台机器上使用处理器和内存,因此很难实现内存和CPU资源的全利用率
负载均衡:很难在存储负载和计算负载之间达成比较好的平衡,原因在于这两种负载对计算机资源的诉求不同
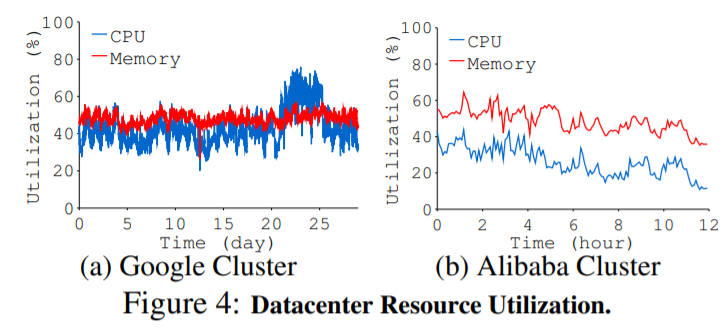
弹性、容错性:在服务器中封装硬件设备后,很难添加、删除或更改数据中心中的硬件组件。此外,当像内存控制器这样的硬件组件出现故障时,整个服务器都无法使用
异构性:现代数据中心承载着越来越多的异构硬件,设计适合单体服务器的新硬件并将其部署在数据中心是一个痛苦且成本效益低的过程,通常会限制新硬件的采用速度
[ATC ‘20 Clover] Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive Disaggregated Key-Value Stores
- Yiying Zhang团队,UCSD
- 存算分离架构已经成为许多数据中心和云的普遍做法。分解使得管理和扩展存储池和计算池变得很容易。通过存储池跨应用和用户共享,实现存储资源的整合和成本的降低。作为最近的一个成功案例,阿里巴巴将其基于rdma的分类存储系统列为五大原因之一,这五大原因使他们能够服务于峰值负载2019年双十一,每秒收到订单54.4万单
- [ATC ‘20 best paper] Effectively Prefetching Remote Memory with Leap
- Mosharaf Chowdhury团队,University of Michigan,密歇根大学
- 内存大小受限:现代数据密集型应用程序在其完整的工作集不能装入main memory时,会经历显著的性能损失。与此同时,尽管在大型集群中存在显著且不成比例的内存未充分利用,但无法在机器边界之外访问内存。这种未使用的、滞留的内存可以通过内存分解形成集群范围的逻辑内存池来利用,从而提高应用程序级别的性能和整体集群资源利用率
2. DSM with NVM
- [NSDI ‘20] FileMR: Rethinking RDMA Networking for Scalable Persistent Memory
- Steven Swanson 团队,UCSD,加利福尼亚大学圣地亚哥分校
- 可伸缩的计算机系统如何存储和访问数据正在迅速变化,而这些变化部分是由传统分离的系统组件之间的界限模糊所推动的
[TOS ‘20] TH-DPMS: Design and Implementation of an RDMA-enabled Distributed Persistent Memory Storage System
- Jiwu Shu团队,Tsinghua University
复杂的分析任务要求实时响应查询:新兴的数据中心应用,如电子商务、自动驾驶仪和金融交易等复杂的分析任务,要求系统最大限度地减少响应延迟并最大限度地提高处理吞吐量
- 新兴的 NVM 技术和 RDMA 技术,有希望用于建立大容量、高性能和低延迟的存储系统
[ ASPLOS ‘22] Clio: A Hardware-Software Co-Designed Disaggregated Memory System
- Yiying Zhang团队,UCSD
- 内存需求:图形计算、数据分析和深度学习等现代数据中心应用程序对大量内存的访问需求不断增加,不幸的是,由于pin、空间和功率限制,服务器正面临memory capacity walls
- 由于内存分解具有高效利用内存和易于管理的优点,近年来引起了人们的广泛关注
- [ ASPLOS ‘20] AsymNVM: An Efficient Framework for Implementing Persistent Data Structures on Asymmetric NVM Architecture
- Kang Chen团队,Tsinghua University
- 对称架构资源利用率较低:传统的架构是对称(symmetric)的,分布式中每个节点都配备了存储资源。由于之前的网络较慢,访问远程数据带来的开销较大,虽然单盘的带宽也不高,但可以通过多个盘来提高本地访问的带宽,所以之前的架构大多使用对称的架构。然而随着网络技术的发展,现在的网络具有较低的延迟和较高的带宽,对称架构的优势不再突出。另外在对称架构中资源利用率普遍不高,Google 的一项调查表明利用率平均低于 40%。而且当节点失效了该节点对应的存储资源就不可用了
- 存算分离(Resource Disaggregation):将存储放在单独的节点上,计算节点通过网络访问存储节点来获取数据,计算节点本地没有 NVM,往往使用 DRAM缓存数据。该架构能够灵活地扩充单节点的容量(将所有资源抽象为共享的池)。松耦合的设计使硬件的部署方便,同时提高资源利用率和性价比
3. DSM with 缓存一致性 / 分布式事务
- 在DSM基础上构建了高效缓存一致性协议
- [VLDB ’18 GAM ] Efcient Distributed Memory Management with RDMA and Caching
- DSM有显著优点:应用可以透明地使用集群的大量内存空间,方便开发人员;而且 DSM 可以更好解决负载不均衡时访问热点成为性能瓶颈的问题(通过重定向)
- 当前的 DSM 系统仍有不足:传统的缓存一致性开销大,可以利用 RDMA 实现高效的缓存一致性协议。现有的一些 DSM 系统为了同步缓存,需要手动调用特定的原语进行同步,增加开发人员的工作量
- 在DSM基础上构建了具有 ACID 特性的事务引擎,以为用户提供更加灵活的事务结构
FaRM && FaRMv2
- [EuroSys’16] Fast and General Distributed Transactions using RDMA and HTM && [OSDI ‘18] Deconstructing RDMA-enabled Distributed Transactions: Hybrid is Better
- WXD,Shanghai Jiao Tong University
- 将 HTM 的特性与 FaRM 结合以优化 FaRM 中分布式事务的性能
- [OSDI ’16] FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs
- 实现了基于 FASST RPC 的低延迟,高吞吐量的 KV 事务处理系统
4. Memory Disaggregation for Deep Learning
- [ATC ‘21] Zico: Efficient GPU Memory Sharing for Concurrent DNN Training
- GPU内存墙:并行训练的工作集很容易超过GPU内存
- [Micro ‘18 DC-DLA] Beyond the memory wall: A case for memory-centric HPC system for deep learning
- 内存不足:memory “capacity” wall
- [TOC ‘18 XMemPod] Hierarchical Orchestration of Disaggregated Memory
- 佐治亞理工學院
- 内存需求:大数据和延迟要求高的应用程序通常使用应用程序部署模型进行部署,包括虚拟机 (VM)、容器and/or 执行程序/JVM。如果这些应用程序完全由内存提供服务,它们将享有高吞吐量和低延迟。然而,实际的估计和内存分配是困难的。当这些应用程序无法在其虚拟机/容器/执行器的实际内存中容纳其工作集时,它们会因过多的页面错误和颠簸而遭受巨大的性能损失。即使在同一主机或远程节点上的其他 VM/容器/执行器中存在可用(未使用)内存时,这些应用程序也无法共享那些未使用的主机/远程内存
- On the Memory Underutilization: Exploring Disaggregated Memory on HPC Systems
- 资源利用率低:大规模高性能计算(HPC)系统是由海量的计算资源和内存资源在节点间紧密耦合而成。我们在四个生产HPC集群上进行了大规模的内存使用研究。我们的结果表明,90%以上的作业使用的节点内存容量小于15%,在90%的时间内,内存利用率小于35%。
专题2 大模型相关
- 拆 and 卸
1.算法优化
- 最简单:减少 batch size,能减少内存峰值,不过训练时间会变长
- 梯度检查点(gradient checkpointing):中间结果feature map 一个都不保留,全部干掉,反向传播时重新计算出来
- 用时间换空间
- Training deep nets with sublinear memory cost:每隔 sqrt(n)保留一个,比如一个100层的网络,每隔 10层,保留一个
- 梯度累加(Gradient Accumulation):每计算一个batch的梯度,不进行清零,而是做梯度的累加,当累加到一定的次数之后,再更新网络参数,然后将梯度清零
- 混合精度(mixed precision):单精度 float和半精度 float16 混合,需要硬件支持(好在 Nvidia GPU, TPU都支持 fp16 了),其次需要框架层面支持,能把内存降低到一半
2. Memory Management
总结:数据释放、预取,动态卷积函数选择、动态Batch大小选择,编码
- [ASPLOS ‘20] Capuchin: Tensor-based GPU Memory Management for Deep Learning
- 提出了一个基于张量的GPU内存管理模块Capuchin,它通过张量移除/预取和重新计算来减少内存占用
- [ASPLOS ‘20] SwapAdvisor: Push Deep Learning Beyond the GPU Memory Limit via Smart Swapping
- 优化GPU、CPU数据交换:根据给定的数据流图沿着三个维度执行联合优化:操作员调度、内存分配和交换决策。SwapAdvisor使用定制设计的遗传算法探索广阔的搜索空间
- [ISCA ‘19] Interplay between Hardware Prefetcher and Page Eviction Policy in CPU-GPU Unified Virtual Memory
- 开发了支持高效预取的统一虚拟内存(Unified Virtual Memory, UVM),支持按需分页和迁移,对用户是透明的
- [ISCA ‘18] Gist: Efficient Data Encoding for Deep Neural Network Training
- 特征图通常有两个用途,它们在时间上分散得很远。我们的关键方法是存储这个时间间隔的特征映射的编码表示,并解码这个数据以用于向后传递;全保真度特征映射在前传中使用,并立即放弃
- [PPoPP ‘18] SuperNeurons: Dynamic GPU Memory Management for Training Deep Neural Networks
- 动态GPU内存调度运行时训练深度非线性神经网络,动态卷积函数选择、动态Batch大小选择
- [MICRO ‘16] vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design
- GPU-CPU 统一内存管理,前向传播时向CPU内存中卸载张量,后向传播时从CPU内存中预取要发送给GPU的张量
3. 分布式 / 并行训练:Scheduling & Resource Management
- 减少任务切换开销,GPU-CPU内存资源管理
- [ATC ‘21] Zico: Efficient GPU Memory Sharing for Concurrent DNN Training
- 监控 GPU 计算进度来跟踪单个训练作业的内存使用模式,并使从作业中回收的内存可全局共享
- [NeurIPS ‘20] Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning
- 引入了一种称为提前调度(AoT)的新技术。调度过程在执行GPU内核之前完成,从而消除了运行时的大部分调度开销
- [OSDI ‘20] PipeSwitch: Fast Pipelined Context Switching for Deep Learning Applications
- PyTorch 底层封装了 CUDA 的 runtime API存在 lazy initialization:仅当进程第一次申请 GPU 资源时,CUDA 上下文才会创建,并且创建上下文消耗的时间较长
- 得多DL任务在同一GPU上高效地分时复用,任务切换开销为毫秒级,且不耽搁SLO
- [MLSys ‘20] Salus: Fine-Grained GPU Sharing Primitives for Deep Learning Applications
- 过Salus实现了两种GPU共享原语:快速任务切换和内存共享,以实现多个DL应用程序之间的细粒度GPU共享
- [SOSP ‘19] Generic Communication Scheduler for Distributed DNN Training Acceleration
- [EuroSys ‘18] Optimus: An Efficient Dynamic Resource Scheduler for Deep Learning Clusters
- [HPCA ‘18] Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective
4. 拆 and 卸
- [SC ‘20 拆] ZeRO: Memory Optimizations toward Training Trillion Parameter Models
- 数据并行具有较好的通信和计算效率,但内存冗余严重。因此,ZeRO通过对参数(包括优化器状态、梯度和参数)进行分区来消除这种内存冗余,每个GPU仅保存部分参数及相关状态
- ZeRO中有三个阶段,对应于三个模型状态:第一阶段(ZeRO-1)只划分优化器状态,第二阶段(ZeRO-2)划分优化器状态和梯度,最后阶段(ZeRO-3)划分所有三个模型状态
- [ATC ‘21 拆卸] ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Offload 是一种通过将数据和计算从 GPU 卸载到 CPU,以此减少神经网络训练期间 GPU 内存占用的方法,该方法提供了更高的训练吞吐量,并避免了移动数据和在 CPU 上执行计算导致的减速问题
- 基于ZeRO-2,ZeRO-Offload 不在每块 GPU 上保持优化器状态和梯度的分割,而是将二者卸载至主机 CPU 内存。在整个训练阶段,优化器状态都保存在 CPU 内存中;而梯度则在反向传播过程中在 GPU 上利用 reduce-scatter 进行计算和求均值,然后每个数据并行线程将属于其分割的梯度平均值卸载到 CPU 内存中,将其余的抛弃。一旦梯度到达 CPU,则每个数据并行线程直接在 CPU 上并行更新优化器状态分割
- [SC ‘21 拆卸] ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- ZeRO-Infinity构建GPU、CPU内存和NVMe异构系统,在有限的资源上实现前所未有的模型规模,而不需要重构模型代码
- 基于ZeRO-3,ZeRO-Infinity对所有模型状态进行分区,以消除内存冗余。ZeRO-Infinity设计有一个强大的offload机制,称为infinity offload引擎,它可以将所有分区的模型状态加载到CPU或NVMe内存中,或者根据内存需求将它们保留在GPU上
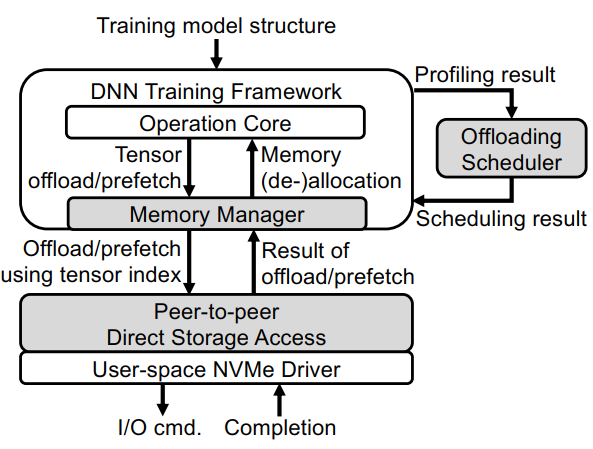
- [FAST ‘21 卸] Behemoth: A Flash-centric Training Accelerator for Extreme-scale DNNs
- 随着NLP训练的模型规模的扩大,DRAM的容量逐渐不能够跟得上NLP模型的增长速度
- 为了解决这个问题通常的方法有:重算中间结果(引入额外的训练开销),采用模型并行同时流水线处理(不能够确保任务都能够有效划分)
- 考虑带宽这个维度,因为在Transformer网络中,存在很多的FC层,需要较为密集的矩阵乘法计算,而且这里因为矩阵规模的庞大,这些计算通常是计算密集型的,所以对于存储的带宽需求其实是相对较低的
- 因此可以使用低带宽但是大容量的SSD来代替DRAM完成对于中间结果的缓存
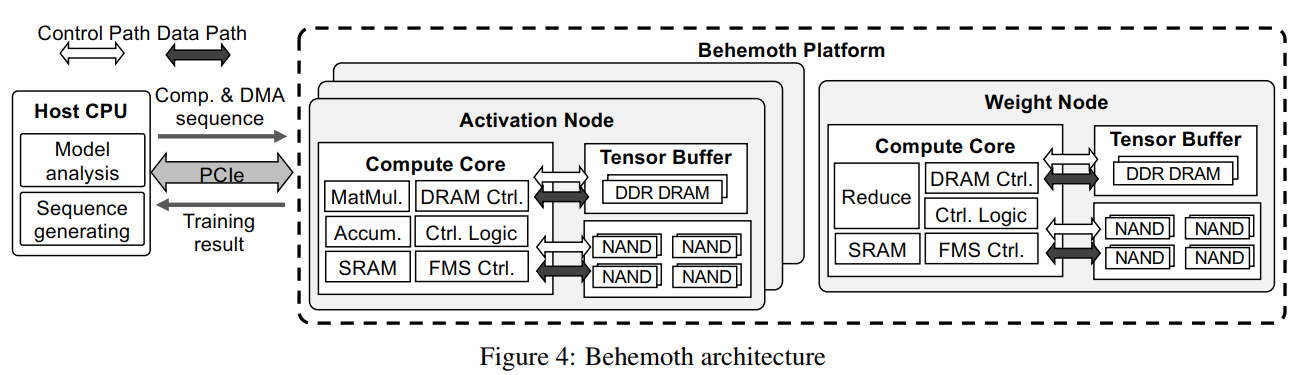
- [FAST ‘21 卸] FlashNeuron: SSD-Enabled Large-Batch Training of Very Deep Neural Networks
- 构建SSD为主存储平台 and 绕过CPU直接卸载到NVMe
- 在深度学习训练中,由于GPU显存受限,因此通常不能够加大Batch Size的大小。小Batch Size通常不足以充分发挥GPU的性能,从而会造成训练吞吐率的降低
- 过去的工作采用的方法通常是将GPU训练的中间结果(比如FeatureMap)下移到CPU之中,采用该方法能够实现大的吞吐,但是因为CPU和GPU之间来回传输数据的开销,将会造成吞吐的下降,同时还会存在使用CPU的计算任务的互相干扰
- Behemoth将训练的中间结果Offloading到NVMe上,实现了对于大Batch Size的支持,但是由于NVMe的带宽受限,需要采用精细化调度来优化数据传输,同时使用GPU-direct的策略,直接实现GPU和SSD的数据传输,最大程度地降低对于CPU的打扰
- DRAGON: Breaking GPU memory capacity limits with direct NVM access.
- 计算所需的数据分布到多个DNN训练设备上来并行化模型
5. Checkpoint
论文 CheckFreq: Frequent, Fine-Grained DNN Checkpointing
背景:为什么要checkpoint?
- 在工业界,由于训练DNN的数据量和模型大小都很庞大,训练一个大的DNN模型一般会花费数十小时,甚至几天时间。为了训练的速度考虑,最新的模型参数的更新都保存在GPU的高速缓存中。当训练过程中出现异常,或者训练机器挂掉,系统只有重头开始训练,浪费时间更浪费金钱。为了避免重头开始训练模型的窘境,人们在训练中某些batch训练完成后周期性的把训练中模型的中间状态备份到磁盘的过程叫checkpointing
同步模式
- 当模型训练完第n个batch之后,框架需要暂停batch n+1的训练,然后把GPU的高速缓存中模型同步下刷到本地或远端磁盘。当模型checkpoint完毕后,batch n+1的训练才可以继续
问题
- 同步checkpoint会阻塞模型训练,因此增加整个DNN模型训练的时间,那么有没有办法让checkpoint不阻塞或少阻塞训练呢?
- 多久做一次checkpoint对模型,系统来说最合理?
CheckFreq:细粒度划分+异步/并行
方案1: 2-phase checkpointing
- 加速checkpoint,解决checkpoint不卡
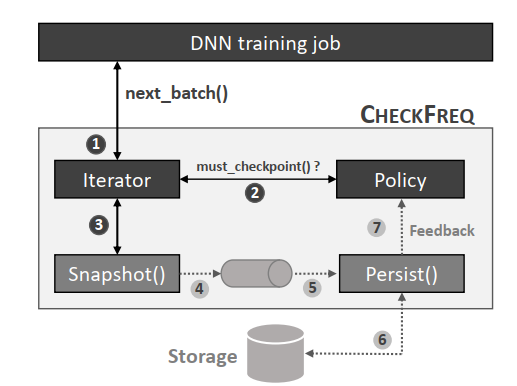
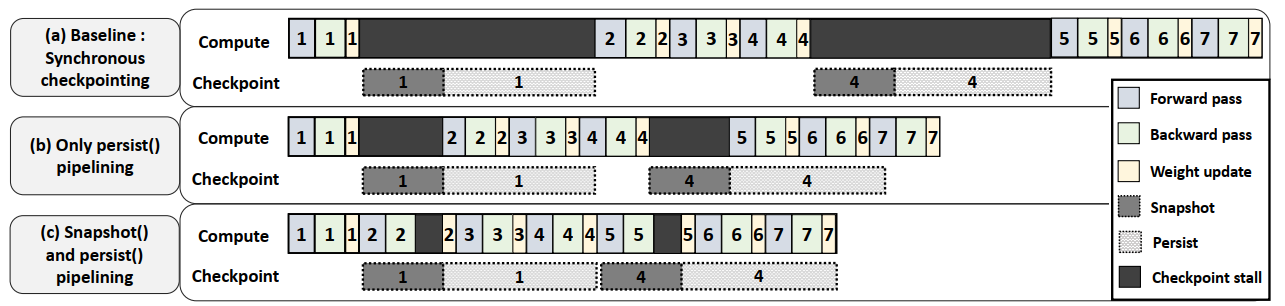
- 同步checkpointing(a):
- 假设第一个batch经过参数forward、backward,最后模型参数的weights都update了
- 这个时候同步checkpointing进程会先把GPU高速缓存里的模型拷贝到DRAM里(图中叫snapshotting)
- 然后通过文件系统fsync到磁盘(图中叫Disk IO)。系统需要等snapshotting和Disk IO都结束才能开始第二个batch的训练
- 进一步优化(b)
- 考虑到checkpointing有两步,因为checkpointing需要保存的是第一个batch训练结束后模型各个参数的值,所以snapshotting的时候要求模型的参数不能改变
- 所以我们暂停第二个batch的训练,但是当我们把GPU高速缓存中的模型数据拷贝到DRAM中时,这个时候模型在GPU和DRAM中有两份独立的拷贝,也就是说Disk IO阶段,GPU内的模型是可以被改变,并继续训练的
- 所以有了第一种优化:训练只在snapshotting的时候暂停,在系统把DRAM中的batch 1模型拷贝刷到磁盘的过程中,第二个batch可以并行的进行训练
- 2-phase checkpointing(c)
- 注意到:只要我们做snapshotting的时候,GPU高速缓存里模型参数的weight不变就行了
- 我们进一步把第二个batch的训练细分为forward,backward和weight update三个阶段来看
- Forward阶段是读取第一个batch结束后的参数的weight
- backward阶段是根据神经网络计算梯度
- 这两个阶段都不会改变GPU的高速缓存中模型参数的weight,那我们可以一边做snapshotting把模型从GPU高速缓存中拷贝到DRAM中,一边让第二个batch训练的forward和backward先做着
- 只有当第二个batch执行到weight update阶段,如果snapshotting还没有结束,这个时候系统才会暂停训练,这样可以最大程度的做到了checkpointing和训练并行
- 进一步,DNN一般都是一层一层forward,backward,只要snapshotting的顺序合理设计,有很多时间可以利用起来
方案2:动态profiling建模
- 什么时候做checkpoint,多久做一次checkpoint
- 什么因素会影响checkpoint的开销
- 例如,模型越大,需要备份的数据量越大,checkpointing时间越久; 磁盘越慢,做checkpoint的overhead越大,等等
- 动态profiling建模:看模型情况。图中列了一些metrics,动态profiling然后得到最合理的checkpoint interval

存储需求
- 当前的问题:
- lustre上训练有时起不来,有时会卡住,ceph训练比cache慢
- 大模型参数卸载到主存或者磁盘上
- checkpoint 怎样快速的保存
- 整体规划
- NLP榜单登顶,主要涉及到算法,如何支持超过2000亿参数的模型训练
- 在顶会发表paper
- 重构整个训练及推理框架,6个月后开源
- 下一步计划:
- 分析使用luste和ceph相关的问题
- 共享资料,分析啊现有的优化方法,分析现在大模型的训练瓶颈,寻找优化点
- 根据分析结果确定优化路径,时间点
专题3 RL Framework
1. RL 框架
- OpenAI的Baselines、SpinningUp
- 加州伯克利大学的开源分布式强化学习框架RLlib、rlpyt 、rlkit 、Garage
- 谷歌Deepmind的Dopamine、B-suite
- 其他独立开发的平台Stable-Baselines、keras-rl、PyTorch-DRL、TensorForce、Tianshou、Di-engine
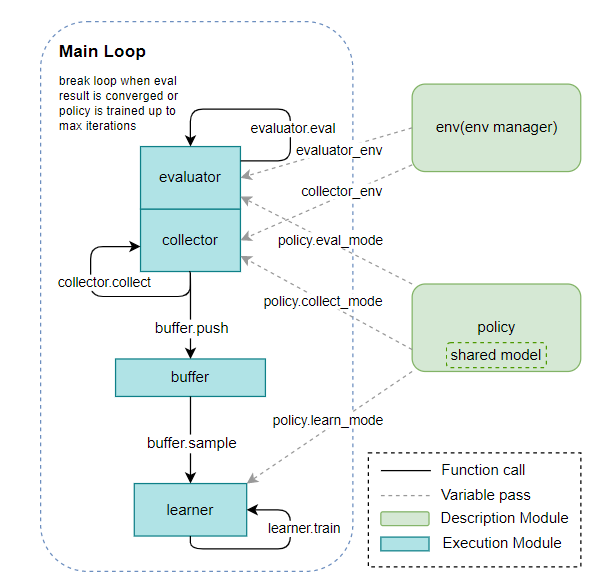
- 优化方式:multiple/parallel actors-learners,asynchronous actors-learners
2. Replay Buffer
经验回放使得在线强化学习的agent能够记住和重新利用过去的经验,在以往的研究中,过去的经验(transition,经验池中的一条记录,表示为元组形式,包含state,action,reward,discount factor,next state)
关键问题:一是选择哪些经验进行存储,二是如何进行回放
Prioritized Experience Replay:回放较为重要的经验,加快收敛
Google DeepMind,ICLR ‘15
通常只是Experience 通过均匀采样来获取。然而这种方法,只要原来有过这个经验,那么就跟别的经验以相同的概率会被再次利用,忽略了这些经验各自的重要程度
优先级排序用的是TD-error来进行衡量,这个值表示当前Q值与目标Q值有多大的差距。如果TD-error越大,就代表我们的预测精度还有很多上升空间,那么这个样本就越需要被学习,也就是优先级p越高
- 样本i的抽样概率为:(pi为优先级指标,alpha为优先级权重,等于0时为均匀采样)
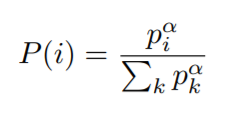
具体实现,提供了一种思路:sum-tree / 片段树 / 分段线性函数
每片树叶存储每个样本的优先级p,每个树枝节点只有两个分叉,节点的值是两个分叉的合,所以顶端就是所有p的合
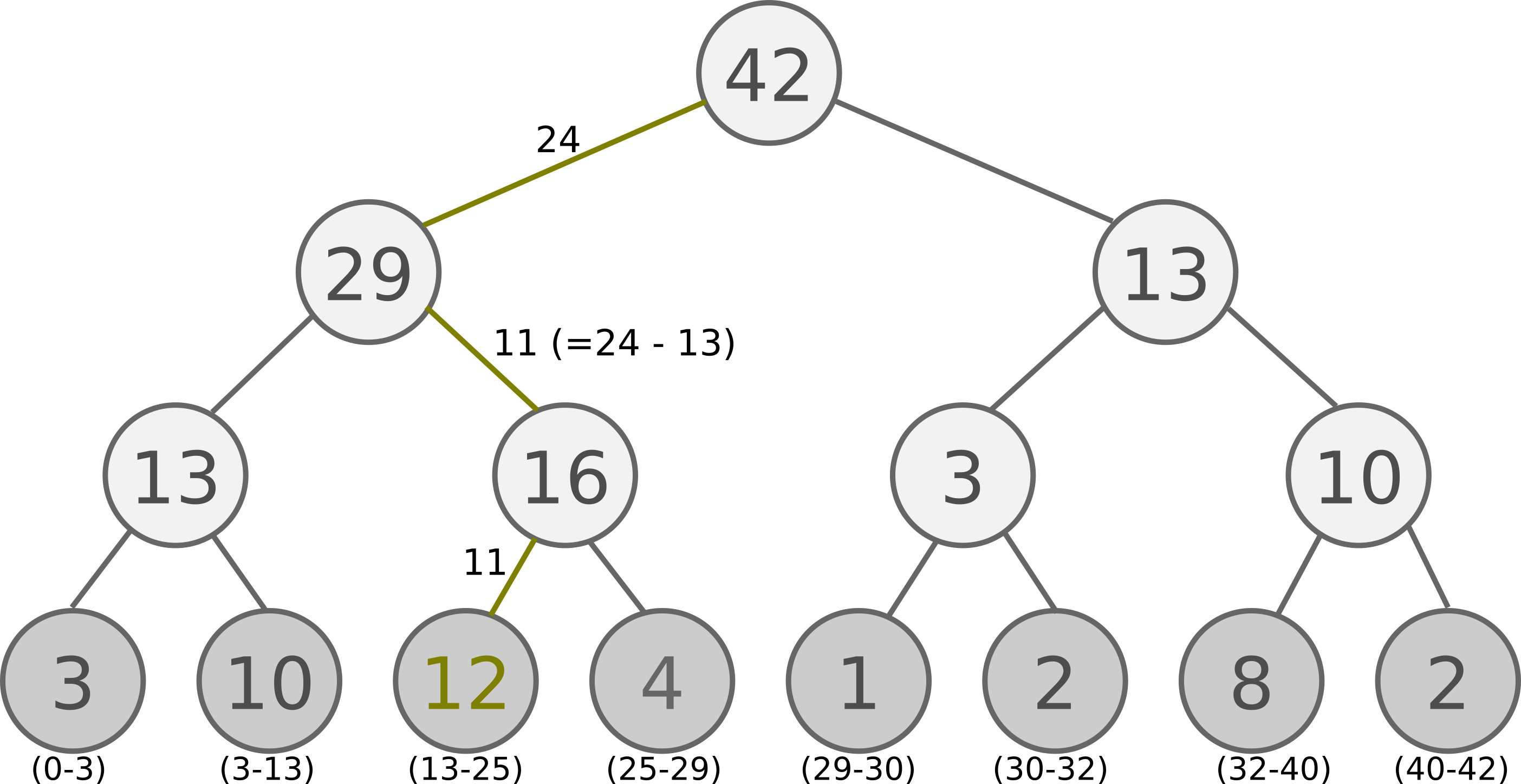
抽样时, 我们会将p的总合 除以 batch size, 分成 很多区间。比如42 / 6:
[0-7], [7-14], [14-21], [21-28], [28-35], [35-42]然后在每个区间里随机选取一个数。比如在区间
[21-28]里选到了24, 就按照这个 24 从最顶上的42开始向下搜索,每次找大的p, 最后就选 12 当做这次选到的 priority, 并且也选择 12 对应的数据
rank-based prioritization
基于排名的优先级,以 TD-error 由大到小排名的倒数作为优先级指标。即P= 1 / rank(i),可以得到累积密度函数: 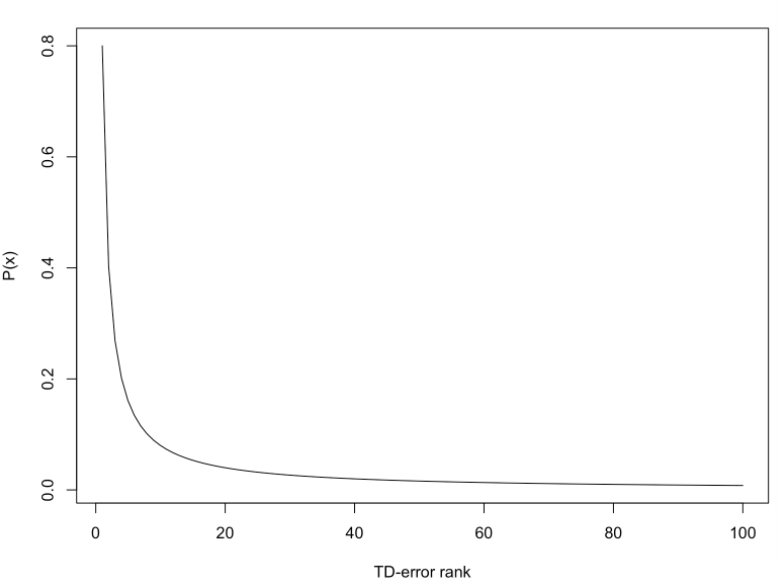
- 按照学习mini-batch k的大小,将排名分成k段,利用抽样分布抽样某一段。选中某段之后,均匀抽样某条数据
importance sampling
Distributed Prioritized Experience Replay
Ape-x,Google DeepMind,ICLR ‘18
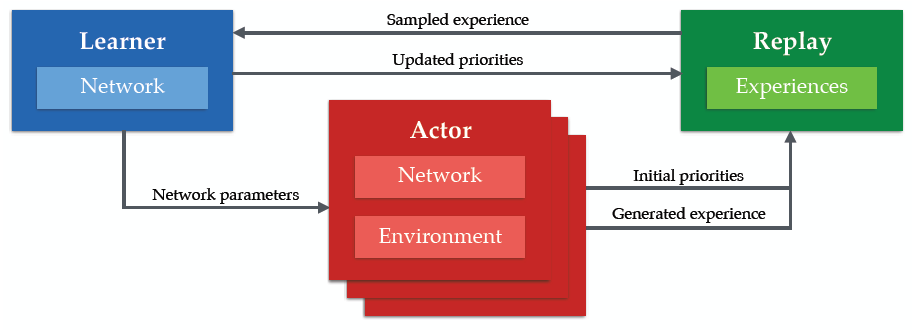
传统的分布式神经网络训练方法都是想要并行地计算梯度,Ape-x想要分布式地生成选取经验数据
Parallel Actors and Learners: A Framework for Generating Scalable RL Implementations
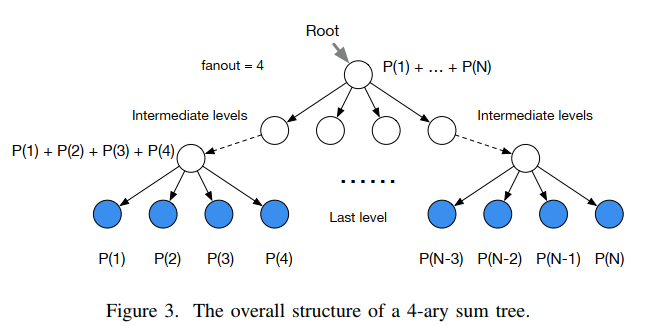
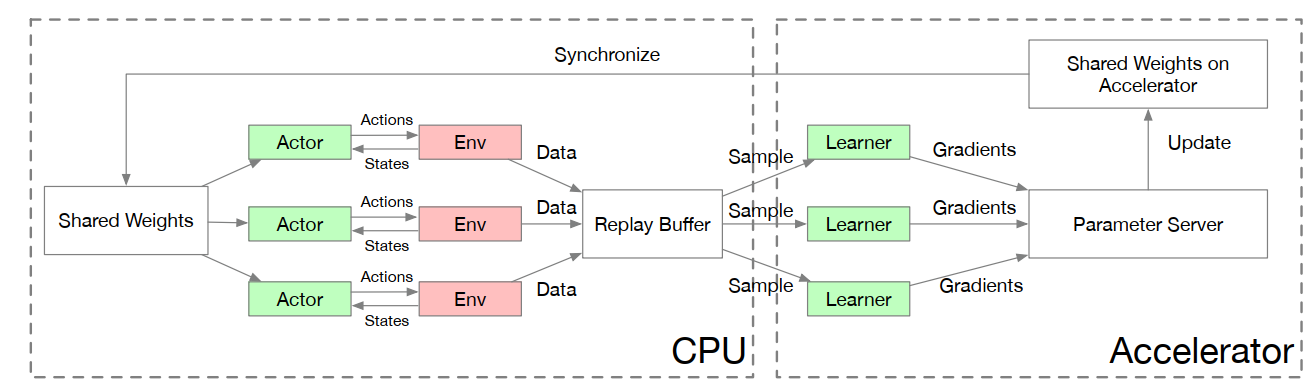
3. 存储需求
- 训练样本:Replay Buffer
- 采样优化:Memory Bank
- Parameter Server由server节点和worker节点组成,其主要功能分别如下:
- server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
- worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点
文件元数据信息
- 具体要求(~5200G)
- RL中的replay buffer
- 本质为一个FIFO队列,支持对于整个队列的随机采样,按索引访问,按索引删除元素,按索引修改元素的值
- 队列长度一般为1w-100w,单个元素大小为10KB-5MB。可定义数据被采样的优先级,可预采样多次
- 大小:100M~5000G
- RL中的parameter server
- 本质为一个固定K-V的字典,key是权重名,value是神经网络权重,训练端会以2s-20s的频率更新相应的权重,收集端会不定期读取相应的权重,并且收集端数量要远远大于训练端
- 权重大小:5M~500M
- RL中的memory bank
- 本质为一个FIFO队列,支持按索引快速访问
- 一般大小为1w-10w,元素大小10KB-1MB,但是元素大小很可能差别很大
- 大小:100M~100G
- 监督学习中的数据集文件名,文件元信息列表
- 本质是一个定长的数组,元素数量可能非常大(100w-1000w)量级
- 单个元素大小1KB-100KB,需要在训练初期加载到内存中,在训练过程中不会发生改变,只用于读取,且读取的顺序也可以在一开始确定
- 大小:1000M~100G
- RL中的replay buffer
专题4 最新论文
FAST 22
February 22–24,
Persistent Memory: Making it Stick 持久性内存
- NyxCache: Flexible and Efficient Multi-tenant Persistent-Memory Caching Kan Wu, Kaiwei Tu, and Yuvraj Patel, University of Wisconsin–Madison; Rathijit Sen and Kwanghyun Park, Microsoft; Andrea Arpaci-Dusseau and Remzi Arpaci-Dusseau, University of Wisconsin–Madison
- HTMFS: Strong Consistency Comes for Free with Hardware Transactional Memory in Persistent Memory File Systems Jifei Yi, Mingkai Dong, Fangnuo Wu, and Haibo Chen, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University
- ctFS: Eliminating File Indexing with Contiguous File System on Persistent Memory Ruibin Li, Univeristy of Toronto; Xiang Ren, University of Toronto; Xu Zhao, Facebook; Siwei He, Michael Stumm, and Ding Yuan, University of Toronto
- FORD: Fast One-sided RDMA-based Distributed Transactions for Disaggregated Persistent Memory Ming Zhang, Yu Hua, Pengfei Zuo, and Lurong Liu, Huazhong University of Science and Technology
A Series of Merges 压缩 - 索引结构
- Closing the B+-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression Yifan Qiao, Rensselaer Polytechnic Institute; Xubin Chen, Google Inc.; Ning Zheng, Jiangpeng Li, and Yang Liu, ScaleFlux Inc.; Tong Zhang, Rensselaer Polytechnic Institute
- TVStore: Automatically Bounding Time-Series Storage via Time-Varying Compression Yanzhe An, Tsinghua University; Yue Su, Huawei Technologies Co., Ltd.; Yuqing Zhu and Jianmin Wang, Tsinghua University
- Removing Double-Logging with Passive Data Persistence in LSM-tree based Relational Databases Kecheng Huang, Shandong University, The Chinese University of Hong Kong; Zhaoyan Shen and Zhiping Jia, Shandong University; Zili Shao, The Chinese University of Hong Kong; Feng Chen, Louisiana State University
Solidifying the State of SSDs 介质SSD
Design and Implementation of WOM-v Codes for High Density SSDs Shehbaz Jaffer, Kaveh Mahdaviani, and Bianca Schroeder, University of Toronto
GuardedErase: Extending SSD Lifetimes by Protecting Weak Wordlines Duwon Hong, Seoul National University; Myungsuk Kim, Kyungpook National University; Geonhee Cho, Dusol Lee, and Jihong Kim, Seoul National University
Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs
Miryeong Kwon, Donghyun Gouk, Sangwon Lee, and Myoungsoo Jung, KAIST
- 计算ssd硬件/软件协同可编程框架加速大规模图的深度学习服务
Operational Characteristics of SSDs in Enterprise Storage Systems: A Large-Scale Field Study Stathis Maneas and Kaveh Mahdaviani, University of Toronto; Tim Emami, NetApp; Bianca Schroeder, University of Toronto
Distant Memories of Efficient Transactions 事务
- Hydra : Resiliency on Fast and Highly Available Remote Memory Youngmoon Lee, Hanyang University; Hasan Al Maruf and Mosharaf Chowdhury, University of Michigan; Asaf Cidon, Columbia University; Kang G. Shin, University of Michigan
- MT^2: Memory Bandwidth Regulation on Hybrid NVM/DRAM Platforms Jifei Yi, Benchao Dong, Mingkai Dong, Ruizhe Tong, and Haibo Chen, Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University
- Aurogon: Taming Aborts in All Phases for Distributed In-Memory Transactions Tianyang Jiang, Guangyan Zhang, Zhiyue Li, and Weimin Zheng, Tsinghua University
The Five Ws of Deduplication 重复数据删除
- DedupSearch: Two-Phase Deduplication Aware Keyword Search Nadav Elias, Technion - Israel Institute of Technology; Philip Shilane, Dell Technologies; Sarai Sheinvald, ORT Braude College of Engineering; Gala Yadgar, Technion - Israel Institute of Technology
- DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression Jisung Park, ETH Zürich; Jeonggyun Kim, Yeseong Kim, and Sungjin Lee, DGIST; Onur Mutlu, ETH Zürich
- The what, The from, and The to: The Migration Games in Deduplicated Systems Roei Kisous and Ariel Kolikant, Technion - Israel Institute of Technology; Abhinav Duggal, DELL EMC; Sarai Sheinvald, ORT Braude College of Engineering; Gala Yadgar, Technion - Israel Institute of Technology
- DUPEFS: Leaking Data Over the Network With Filesystem Deduplication Side Channels Andrei Bacs, VU University Amsterdam; Saidgani Musaev, unaffiliated; Cristiano Giuffrida and Herbert Bos, Vrije Universiteit Amsterdam; Kaveh Razavi, ETH Zurich
Meet the 2022 File System Model-Year Lineup 文件系统
- FusionFS: Fusing I/O Operations in Firmware File Systems Jian Zhang, Yujie Ren, and Sudarsun Kannan, Rutgers University
- INFINIFS: Efficient Metadata Service for Large-Scale Distributed Filesystems Wenhao Lyu and Youyou Lu, Tsinghua University; Yiming Zhang, NUDT; Jiwu Shu, Tsinghua University
- Scale-XFS: Getting scalability of XFS back on the ring Dohyun Kim, Kawngwon Min, Joontaek Oh, and Youjip Won, KAIST
- exF2FS: Transaction Support in Log-Structured Filesystem Joontaek Oh, Sion Ji, Yongjin Kim, and Youjip Won, KAIST
Keys to the Graph Kingdom 键值存储
- A Log-Structured Merge Tree-aware Message Authentication Scheme for Persistent Key-Value Stores Igjae Kim, KAIST, UNIST; J. Hyun Kim, Minu Chung, Hyungon Moon, and Sam H. Noh, UNIST
- Practicably Boosting the Processing Performance of BFS-like Algorithms on Semi-External Graph System via I/O-Efficient Graph Ordering Tsun-Yu Yang, Yuhong Liang, and Ming-Chang Yang, The Chinese University of Hong Kong
- DEPART: Replica Decoupling for Distributed Key-Value Storage Qiang Zhang and Yongkun Li, University of Science and Technology of China; Patrick P. C. Lee, The Chinese University of Hong Kong; Yinlong Xu and Si Wu, University of Science and Technology of China
Keeping the Fast in FAST 杂七杂八
- SDIO: General, Portable I/O Optimizations With Minor Application Modifications Ricardo Macedo, INESC TEC & U. Minho; Yusuke Tanimura and Jason Haga, National Institute of Advanced Industrial Science and Technology (AIST); Vijay Chidambaram, The University of Texas at Austin and VMware Research; José Pereira and João Paulo, INESC TEC & U. Minho
- Separating Data via Block Invalidation Time Inference for Write Amplification Reduction in Log-Structured Storage Qiuping Wang, Jinhong Li, and Patrick P. C. Lee, The Chinese University of Hong Kong; Tao Ouyang, Chao Shi, and Lilong Huang, Alibaba Group
- CacheSifter: Sifting Cache Files for Boosted Mobile Performance and Lifetime Yu Liang, Riwei Pan, Tianyu Ren, and Yufei Cui, Department of Computer Science, City University of Hong Kong; Rachata Ausavarungnirun, King Mongkut’s University of Technology North Bangkok; Xianzhang Chen, Chongqing University; Changlong Li, East China Normal University; Tei-Wei Kuo, City University of Hong Kong and National Taiwan University; Chun Jason Xue, City University of Hong Kong
思考
- 问题导向
- 加速训练,发挥A100优势
- 内存大小,存储IO不成为瓶颈
- 算法/环境的变化,支持不同算法/场景
- 我们做什么
- 算法优化 / GPU-CPU的调度和管理:最主流
- RL流程 / 训练过程
- 提供存储接口 / 统一存储管理
- 内存/磁盘,数据管理
- RL框架
- 结合A100,如何优化
- 算法优化 / GPU-CPU的调度和管理:最主流
- 发论文
- OSDI,SOSP,SC,ASPLOS:1 / 3
- FAST,ATC:2
大模型内存墙问题和强化学习模型经验存储效率问题
测试
集群
| tp_dev | pat_rd | pat_virgo | pat_cancer | pat_leo | pat_gemini | pat_a100 | pat_dev | | —— | —— | ——— | ———- | ——- | ———- | ——– | ——- |