
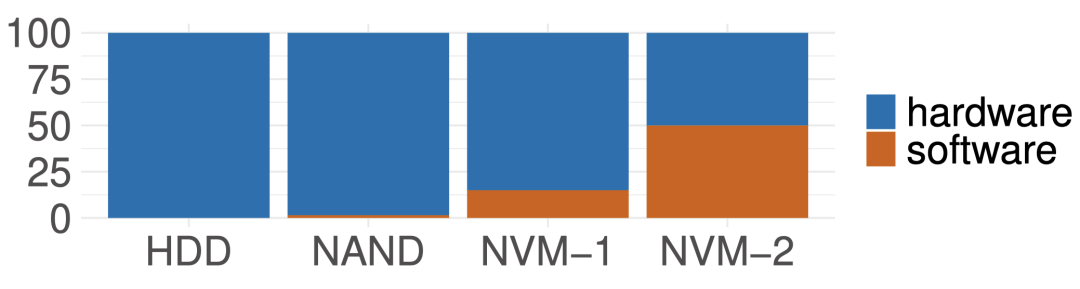
统一存储构想
Unified Storage
与善人居,如入芝兰之室,久而不闻其香,即与之化矣;与不善人居,如入鱼之肆,久而不闻其臭,亦与之化矣。—— 丘子
背景
- 传统存储架构问题
- 冗长存储栈,低效索引,资源分配,新介质…
- 解耦 vs 聚合,分离 vs 统一…
- 统一存储方式
- 不同存储格式:表格,对象…
- 不同存储应用:sql,s3,图…
- 不同工作负载,业务需求?:OLTP和OLAP 请求,或混合事务/分析处理 (HTAP) 工作负载
- 新索引技术的验证
- user applications
设计
- 分层解耦,统一存储
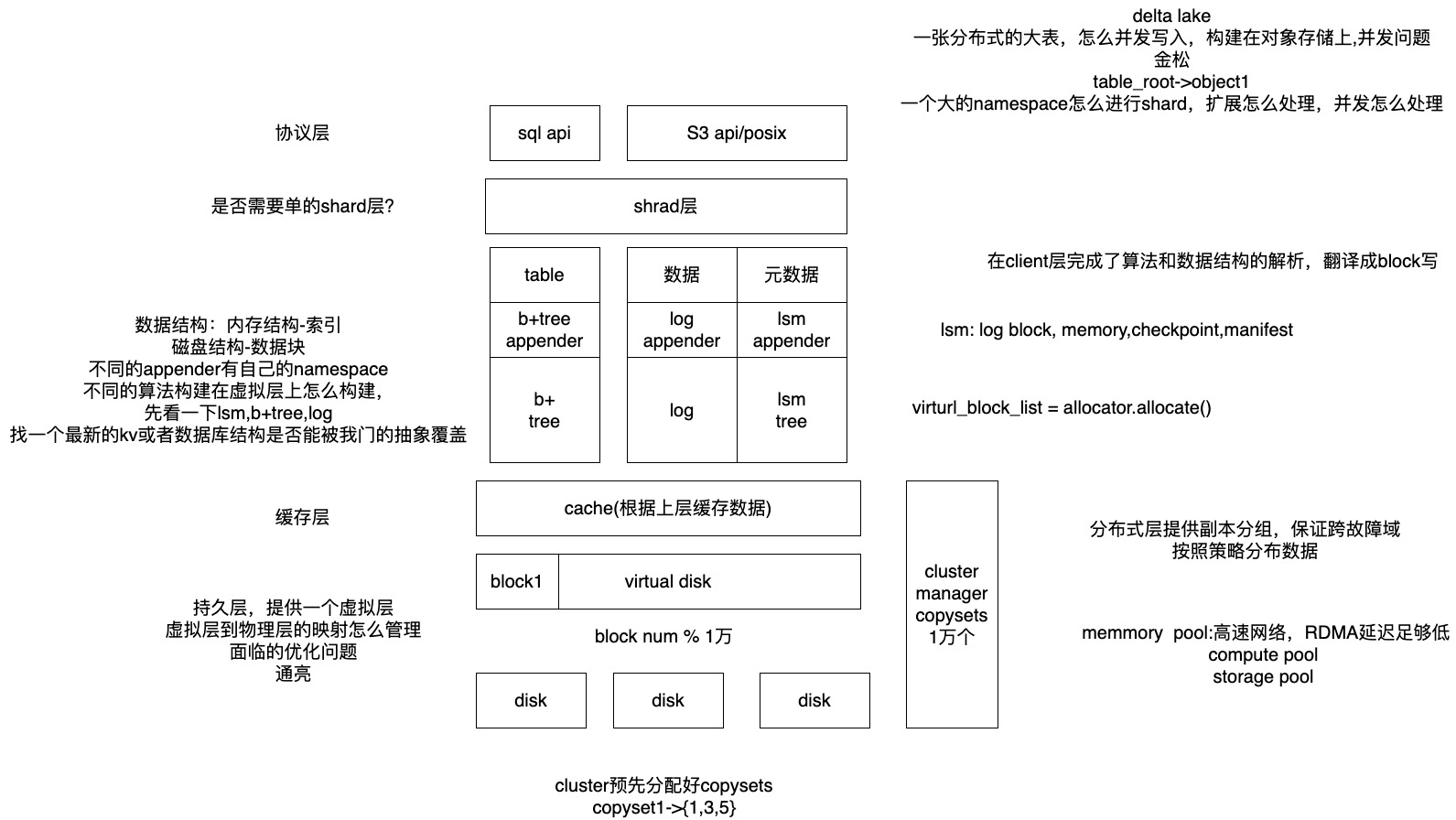
相关论文1 — 统一存储格式
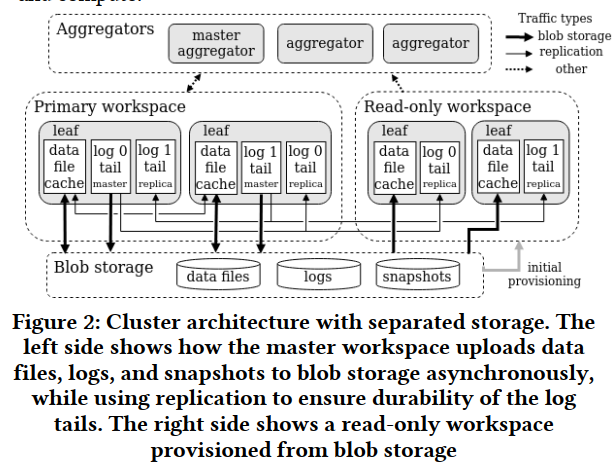
论文1 (Microsoft): Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency
微软向全球提供的商业存储平台,旨在为用户提供大容量、高可靠、高可用、强一致的存储服务,WAS存储数据中心分布在全球多地,使得用户数据得到最大限度的可靠性保障,WAS宣称其提供的服务满足CAP三个条件
统一存储:基于同一套架构提供了对象存储 (Blob)、结构化存储 (Table) 和队列服务 (Queue),这三种服务共享了一个提供了强一致、global namespace、多地容灾、支持多租户的存储层
三种服务都使用了同一套global namespace,格式为:
http(s)://AccountName.<service>.core.windows.net/PartitionName/ObjectName- AccountName会作为DNS解析的一部分,来确定这个account对应的primary data center(如果需要跨地域就需要使用多个account)
- PartitionName是跨对象事务的边界
- ObjectName是可选的,Blob就没有
Table的每行的primary key由PartitionName和ObjectName组成。Queue的PartitionName用来标识队列,而ObjectName则用来标识消息。
WAS的底座是Windows Azure Fabric Controller,负责分配和管理资源,WAS会从它那里获取网络拓扑、集群物理布局、存储节点的硬件信息等
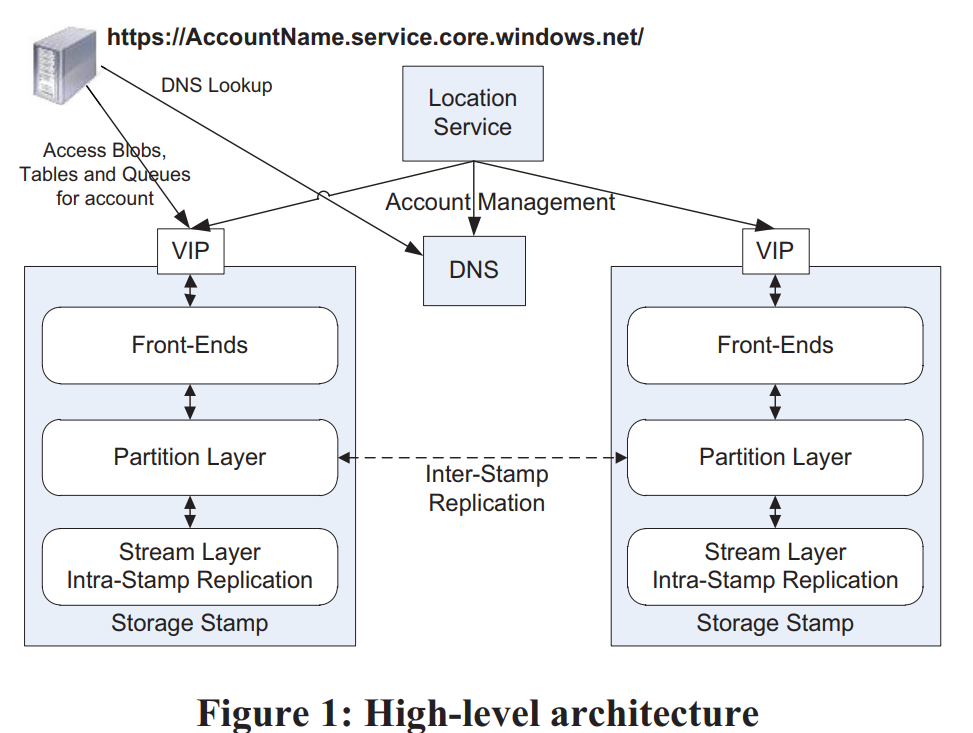
一套WAS环境由若干套storage stamp和一套location service组成:
- 每套storage stamp是一个小集群,典型的大小是10-20个rack,每个rack有18个节点。第一代storage stamp容量是2PB,下一代会提升到30PB。storage stamp的目标是达到70%的使用率,包括了容量、计算、带宽
- location service负责管理account到storage stamp的映射与迁移(一个account只能有一个primary storage stamp)
storage stamp内部分为三层:
- stream层提供类似于GFS的能力。数据组织为extent(类比chunk),extent再组织为stream(类比file)。这一层是三种服务共享的。
- partition层提供三种服务特有的能力。它负责提供应用层抽象、namespace、事务与强一致的能力、数据的组织、cache。partition和stream的server是部署在一起的,这样最小化通信成本。
- front-end(FE)负责处理请求。它会缓存partition map从而快速转发请求。另外它还可以直接访问和缓存stream层的数据。
storage stamp提供了两种replication:
- stamp内部,在stream层提供同步的replication,提供数据的强一致性
stamp之间,在partition层提供异步的replication,提供数据的多地容灾能力
- 区分两种replication还有一个好处是stream层不需要感知global namespace,只需要维护stamp内的meta,这样metadata就不会那么多,更容易全部缓存到内存中。
在stream层数据组织为三层:
block是读写的最小单元,但不同block可以有不同大小。每个block有自己的checksum,每次读都会校验。另外所有block定期还会被后台校验checksum
extent是stream层replication的单元,它由一系列block组成。每个extent最终会长到1GB大小,partition层可以控制将大量小对象存储到一个extent,甚至一个block中
stream类似于一个大文件,但它不拥有extent,只是保存了若干个有序的extent引用。将已有的extent组织起来就可以得到新的stream
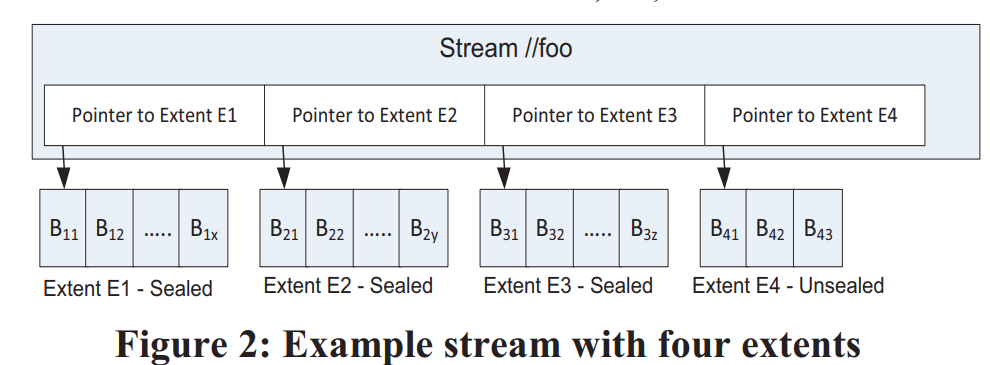
stream层是append-only的,每个stream只有最后一个extent可以被写入,其它extent都是不可变的(immutable)
stamp内部有两类组件:stream manager(SM)和extent node(EN),前者是master,后者是data node(类似于GFS)
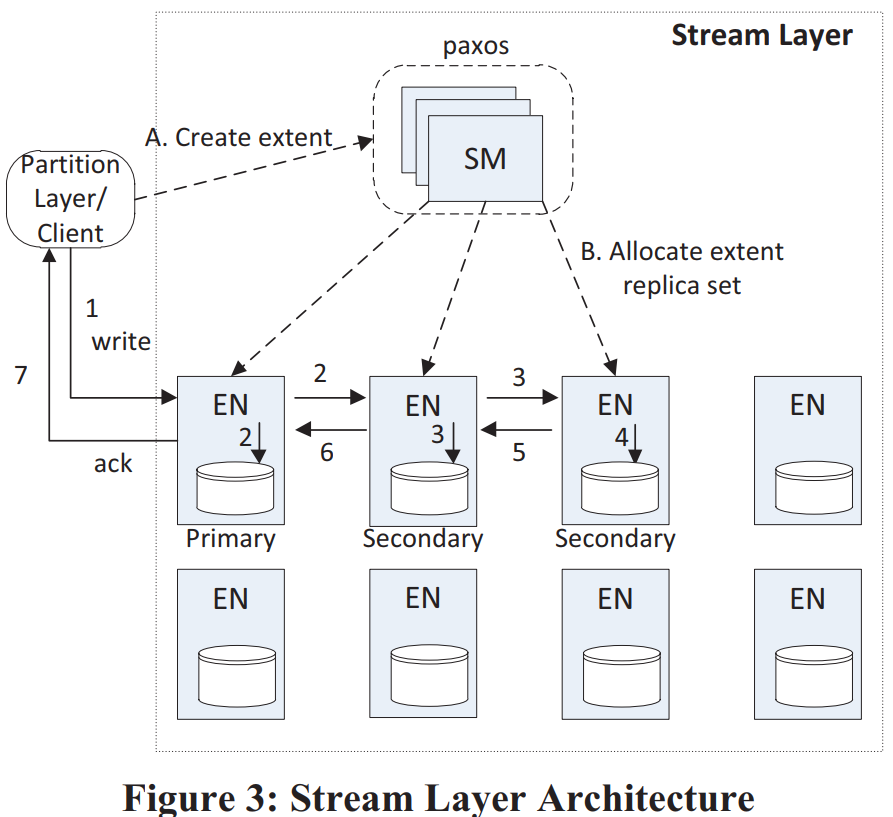
- extent支持原子append多个block,但因为重试原因可能数据会被写入多次,client要有能力处理这种情况。
client会控制extent的大小,如果超过阈值则发送seal指令。被seal的extent不可再被写入,stream层会对sealed extent做一些优化,如使用erasure coding等。
stream层提供的强一致保证:
- 一旦写入成功的消息告知了client,后续所有replica上这次写入的数据都可见(read committed)
一旦extent被seal了,后续所有已经seal的replica的读保证看到相同内容(immutable)
每个extent有一个primary EN和若干个secondary EN,未被seal的extent的EN是不会变的,因此它们之间不需要有lease等同步协议。extent的写入只能由primary EN处理,但可以读取任意secondary EN(即使未seal)。primary会将所有写入排好序,确定每笔写入的offset,再发给所有secondary EN。所有replica都写成功了之后primary才会告知client。
client在写入过程中会本地缓存extent的meta,不需要与SM通信(直到需要分配新extent)。如果某次写入失败了,client可以要求SM来seal这个extent,然后立即开始写新extent,而不需要关心旧extent末尾是否有数据不一致。
seal过程中SM会与每个replica EN通信,并使用可用的EN中最小的commit length。这样能保证所有告知过client的数据都不会丢,但有可能会有数据还没来得及告知client。这是client需要自己处理的一种情况。(是不是可以让client缓存一个commit length,seal时告知SM)
- client在读多副本的extent时可以设置一个deadline,这样一旦当前EN无法在deadline之前读到数据,client还有机会读另一个EN。而在读erasure coded数据时,client也可以设置deadline,超过deadline后向所有fragment发送读请求,并使用最先返回的N个fragment重新计算缺少的数据。
WAS还实现了自己的I/O调度器,如果某个spindle已经调度的I/O请求预计超过100ms,或有单个I/O已经排队超过200ms,调度器就不再向这个spindle发送新的I/O请求。这样牺牲了一些延时,但达到了更好的公平性
- 为了进一步加速I/O,EN会使用单独的一块盘(HDD或SSD)作为journal drive,写入这台EN的数据会同时append到journal drive上,以及正常写extent,哪笔写先完成都可以返回。写入journal drive的数据还会缓存在内存中,直到数据写extent成功(阿里云的pangu使用了类似的方案)。journal drive方案的优点:
- 将大量随机写转换为了顺序写。除了写journal drive天然是顺序的,这种设计还使得写extent时可以使用更倾向batch的I/O调度策略,进一步提高了磁盘带宽的利用率。
- 关键路径上读写请求分离,前者读数据盘(或cache),后者写journal drive。
- 使用了journal drive可以极大降低I/O的延时波动率(对在线业务意义重大)。
- 为了进一步加速I/O,EN会使用单独的一块盘(HDD或SSD)作为journal drive,写入这台EN的数据会同时append到journal drive上,以及正常写extent,哪笔写先完成都可以返回。写入journal drive的数据还会缓存在内存中,直到数据写extent成功(阿里云的pangu使用了类似的方案)。journal drive方案的优点:
Partition层设计类似于BigTable,数据保存在了不同的Object Table(OT)中,每个OT分为若干个RangePartition。OT包括:
- Account Table,Blob Table,Entity Table,Message Table,Schema Table,Partition Map Table
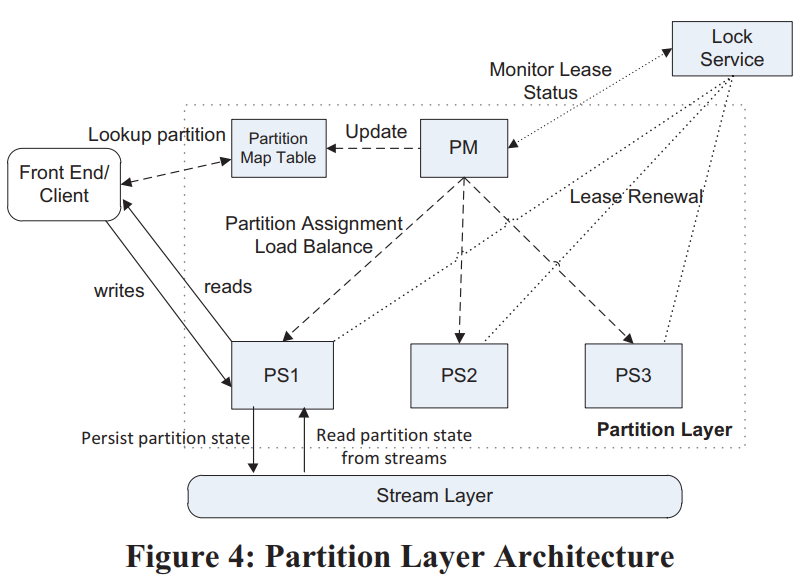
Partition层的架构:
- Partition Manager(PM):类似于BigTable的Master,管理所有RangePartition
- Partition Server(PS):类似于BigTable的Tablet Server,加载RangePartition,处理请求
- Lock Service:类似于Chubby
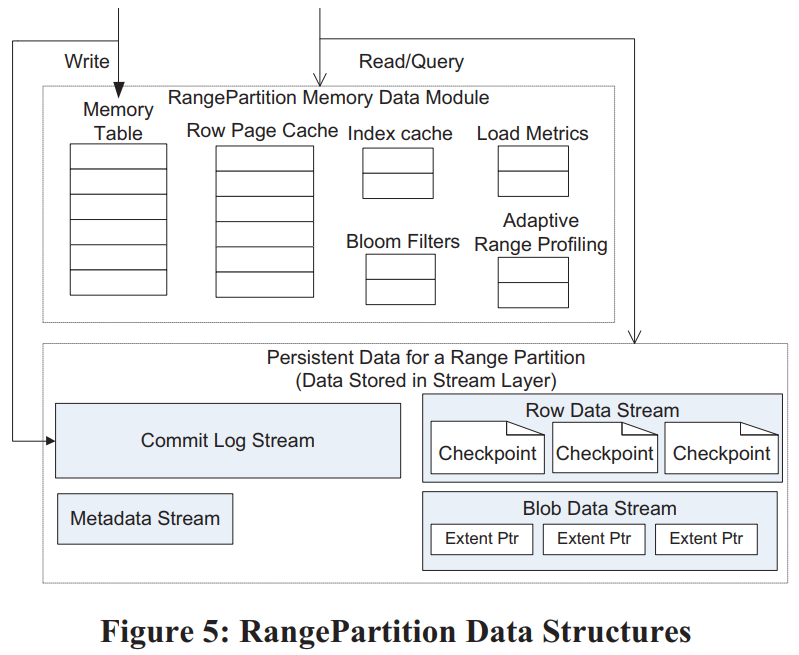
Blob Table大块数据进commit log,但不进入row data(不进cache、不参与常规compaction等),相反row data中只记录数据的位置(extent+offset),并且在checkpoint的时候直接用commit log的extent拼装成data stream
RangePartition的分裂(Split)过程:
- PM向PS发请求,要求将B分裂为C和D
- PS生成B的checkpoint,然后B停止服务(此时是不是可以不停读)
- PS使用B的所有stream的extent组装成C和D的stream
- C和D开始服务(client还不知道C和D,此时应该不会有请求发过来)
- PS告知PM分裂结果,PM更新Partition Map Table,之后将其中一个新Partition移到另一台PS上(分散压力)
合并(Merge)过程类似:
- PM将C和D移动到相同PS上,之后告知PS将C和D合并为E
- PS生成C和D的checkpoint,之后C和D停止服务
- PS使用C和D的stream的extent组装为E的stream,每个stream中C的extent在D之前
- PS生成E的metadata stream,其中包括了新的stream的名字、key range、C和D的commit log的start和end位置、新的data stream的root index
- E开始服务
- PS告知PM合并结果
最后是一些经验教训的总结:
- 计算存储分离:好处是弹性、隔离性,但对网络架构有要求,需要网络拓扑更平坦、点对点的双向带宽更高等
- Range vs Hash:WAS使用Range的一个原因是它更容易实现性能上的隔离(天然具有局部性),另外客户如果需要hash,总是可以基于Range自己实现,而反过来则不然。
- 流控(Throttling)与隔离(Isolation)。WAS使用了SimpleHold算法[2]来记录请求最多的N个AccountName和PartitionName。当需要流控时,PS会使用这个信息来选择性拒绝请求,大概原则是请求越多,被拒绝概率越大(保护小用户)。而WAS会汇总整个系统的信息来判断哪些account有问题(异常访问),如果LoadBalance解决不了就更高层面上控制这种用户的流量
- 自动负载均衡(LoadBalancing):WAS一开始使用单维度“load”(延时*请求速率)来均衡,但无法应对复杂场景。现在的均衡算法是每N秒收集所有Partition的信息,然后基于每个维度排序,找出需要分裂的Partition。之后PM再将PS按各维度排序,找出负载过重的PS,将其中一部分Partition移到相对空闲的PS上(整体思路与Tablestore的LoadBalance差不多,更系统化一些,但Tablestore的LoadBalance策略更多,更灵活)
- 每个Partition使用自己的log file。这点与BigTable的整个Tablet Server共享log file区别比较大。单独log file在load/unload上更快,且隔离性更好,而共享log file更节省I/O(综合来看单独log file更好一些,尤其是随着存储性能的提升、计算存储分离架构的流行,共享log file的优势越来越小,劣势越来越大了)。
- Journal drive。它的意义是降低I/O波动。BigTable使用了另一种方案,用2个log来规避长I/O,但导致了更多的网络流量与更高的管理成本
- Append-only
- End-to-end checksum
- Upgrade。重点是在每一层将节点分为若干个upgrade domain,再使用rolling upgrade来控制upgrade的影响。
- 基于相同Stack的多种数据抽象。我们的系统支持从同一存储中提取三种不同的数据堆栈:Blob、表和队列(包括块存储)。 这种设计使所有数据抽象来使用相同的内部标记和标记间复制,使用相同的负载均衡系统,并实现受益于流和分区层的改进。 在此外,由于 Blob、Tables 和队列不同,我们的单栈方法使我们能够通过在同一组硬件上运行所有服务来降低成本。Blob 使用大量磁盘容量,表使用 I/O 主轴从节点上的许多磁盘(但不需要那么多容量为 Blob),而队列主要在内存中运行。因此,我们不仅融合了不同客户的共享资源上的工作负载,我们也在混合将 Blob、Table 和 Queue 流量放在同一组存储节点
- 使用预定义的Object Table,而不允许应用定义自己的Table。意义在于更容易维护
- 限制每个Bucket大小为100TB。这个是教训,WAS计划增大单个storage stamp
- CAP。WAS认为自己在实践层面上同时实现了C和A(高可用、强一致),具体策略上是通过切换新extent来规避掉不可访问的节点(实践上有意义,但也不能说是同时实现了C和A)。另外[3]表示使用chain replication就可以同时实现高可用和强一致。
- 高性能的debug log。这点很重要
- 压力点测试。WAS可以单独测试多个预定义的压力点(如checkpoint、split、merge、gc等)。(除此之外现在还需要考虑chaos test)
论文2 (Facebook) Facebook’s Tectonic Filesystem: Efficiency from Exascale
背景
- 问题1:业务类型需求不一致,有的是IOPS敏感型,有的是吞吐敏感型,当前facebook不同的业务类型使用独立的集群导致不能同时充分利用集群的吞吐和IOPS资源,造成资源浪费
- 问题2:对于一些数据仓库业务,通常其容量需求巨大,单个集群无法满足,所以一个数据仓库的数据需要存储在多个小集群中,这种方式使得数据处理复杂度提升了。
Tectonic 主要特点
- 同一集群可以提供不同业务需求的服务
- 单个集群能够达到EB级别的扩展能力
资源平衡
资源分类
Tectonic将资源划分为: non-ephemeral and ephemeral。可以理解为可重复使用的和不可重复使用的,对于存储资源,一旦分配给一个租户就不能再分配给其他租户了,那么他就是不可重复使用的,是一个长期占用的资源。但是对于IOPS这样的资源,租户只会在发请求的时候使用到,并且这个请求结束后IOPS资源就被释放出来了,他是一个暂时的占用(大多数云厂商通常都是IOPS超售,存储资源不超售)
因此,可以看出我们能够做文章的也就是这些non-ephemeral的资源。这里的挑战在于,首先我们既要满足每个用户的最基本的存储需求,另外还需要给不同类型的用户提供符合其业务类型需求的优化。
- 用户分类
- Tectonic服务的application数百个,所以在进行资源调度的时候如果以application为粒度,那么整个调度会异常复杂。所以,为了简化资源调度,不按application分类,按照traffic group分类
- 同一traffic group里的application其资源需求相似,在单个集群中,tectonic支持50多种traffic group
- 一个traffic group对应一个trafficClass,trafficClass代表该group对于请求latency的敏感程度,这里分为金、银、铜三个等级,对应的延时敏感性从高到低,同时也对应了其IO优先级。这里需要注意的是,这三个不同等级影响的IO优先级仅限于那些富余的IOPS资源。如果这个集群的在服务当前所有租户没有盈余,这些金银铜等级就没有意义,这点其实很类似mclock的调度模式
- 调度策略
- 当一个请求下发时,在client端需要先经过漏桶,告知自己需要多少的资源,client检查自己的trafficgroup的资源够不够这次IO,够的话就将请求下发到底层存储节点(tectonic不仅对存储节点进行了资源平衡调度,同时也对元数据节点也有一致的优化),存储节点采用权重轮训(WRR)的方式,依次处理到来的请求
- 在存储节点调度IO时有如下三个优化:
- 如果一个低优先级的IO其处理时间足够的情况下,WRR会转让本次执行权限给高优先级的IO,这个策略防止高优先级被低优先级IO阻塞
- 对于非金牌优先级的IO,在存储节点会限制其inflight IO数量。在达到非金牌IO inflight上限时,如果有金牌IO需要处理,都会先处理金牌IO,再进来的非金牌IO都会被阻塞
- 磁盘本身也可以参与重排请求顺序,如果一个金牌IO已经在磁盘pending太久超出阈值,tectonic会停止调度非金牌IO
架构 (略)
- 对于一个集群提供EB级别的存储能力,在小文件场景下,元数据量会很庞大,需要有能力保证随着存储数据量增加带来的元数据量膨胀,需要元数据存储具备同样的强悍的扩展能力
- 元数据管理优化
Design and Deployment Lessons 设计和部署经验总结
- Achieving high scalability is an iterative process enabled by a microservice architecture. 实现高可扩展性是一个由微服务架构支持的迭代过程
- 几个构造组件已经通过多次迭代来满足不断增加的可扩展性要求。例如,第一个版本的块存储分组块以减少元数据。若干 具有相同冗余方案的块被分组并RS编码为一个单元以将它们的块存储在一起。每个块组映射到一组存储节点。这是一种常用技术,因为它显着减少了元数据,但是对于我们的生产环境来说太不灵活了。为了例如,只有 5% 的存储节点不可用,80% 的块组无法写入。这种设计还排除了对冲仲裁写入等优化和法定人数附加(§5)
- 此外,我们最初的元数据存储架构没有分离名称层和文件层;客户咨询了相同的用于目录查找和在文件中列出块的分片。 这种设计导致元数据热点不可用,促使我们进一步分解元数据
- 构造的演变表明尝试新事物的重要性设计以更接近性能目标。我们的发展经验也显示了基于微服务的价值实验架构:我们可以对系统的其余部分透明地迭代组件。内存损坏在规模上很常见。在构造的规模,数千台机器读写大量每天的数据量,内存数据损坏是经常发生的,在其他大规模观察到的现象系统。我们通过执行校验和来解决这个问题检查进程边界之内和之间
- Tectonic 维护数据完整性的成本。所有涉及移动、复制或转换数据的 API 边界都必须进行改造,以包含校验和信息。客户端在写入时将带有数据的校验和传递给客户端库,Tectonic 需要通过校验和不仅跨越流程边界(例如,在客户端之间库和存储节点)但也在进程内(例如,改造后)。检查转换的完整性可防止损坏传播到重建存储节点故障后的块
- Achieving high scalability is an iterative process enabled by a microservice architecture. 实现高可扩展性是一个由微服务架构支持的迭代过程
Services that do not use Tectonic,Facebook 中的某些服务不使用 Tectonic 进行存储
- Bootstrap 引导服务,例如软件二进制包部署系统,必须没有依赖关系,不能使用 Tectonic,因为它依赖于许多其他服务(例如,键值存储、配置管理系统、部署管理系统)
- Graph存储也没有使用 Tectonic,因为 Tectonic 尚未针对通常需要 SSD 存储提供的低延迟的键值存储工作负载进行优化
- 许多其他服务不直接使用 Tectonic。 相反,他们通过 Blob 存储或数据仓库等主要租户使用 Tectonic。 这是因为 Tectonic 的核心设计理念是关注点分离。 在内部,Tectonic 旨在建立独立的软件层,每个软件层都专注于存储系统的核心职责(例如,存储节点只知道块而不知道块或文件)。 这种理念延伸到 Tectonic 如何与其他存储基础设施相适应,例如,Tectonic 专注于在数据中心内提供容错; 它不能防止数据中心故障。 异地复制是 Tectonic 委托给其大型租户的一个单独问题,他们解决这个问题,为应用程序提供透明且易于使用的共享存储。租户还应该了解容量管理和存储部署以及跨不同数据中心重新平衡的详细信息。 对于较小的应用程序,以满足其存储需求的方式直接与 Tectonic 交互所需的复杂性和实现将相当于重新实现租户已经实现的功能。 因此,各个应用程序通过租户使用Tectonic
相关工作
Tectonic adapts techniques from existing systems and the literature, demonstrating how they can be combined into a novel system that realizes exabyte-scale single clusters which support a diversity of workloads on a shared storage fabric.
- Distributed filesystems with a single metadata node
- HDFS [15], GFS [24], and others [38, 40, 44] are limited by the metadata node to tens of petabytes of storage per instance or cluster, compared to Tectonic’s exabytes per cluster.
- Federating namespaces for increased capacity
- Federated HDFS [8] and Windows Azure Storage (WAS) [17] combine multiple smaller storage clusters (with a single metadata node) into larger clusters. For instance, a federated HDFS [8] cluster has multiple independent single-namenode namespaces, even though the storage nodes are shared between namespaces. Federated systems still have the operational complexity of bin-packing datasets (§2). Also, migrating or sharing data between instances, e.g., to load-balance or add storage capacity, requires resource-heavy data copying among namespaces [33, 46, 54]
- Hash-based data location for metadata scalability
- Ceph [53] and FDS [36] eliminate centralized metadata, instead locating data by hashing on object ID. Handling failures in such systems is a scalability bottleneck. Failures are more frequent with larger clusters, requiring frequent updates to the hash-to-location map that must propagate to all nodes. Yahoo’s Cloud Object Store [41] federates Ceph instances to isolate the effects of failures. Furthermore, adding hardware and draining is complicated, as Ceph lacks support for controlled data migration [52]. Tectonic explicitly maps chunks to storage nodes, allowing controlled migration.
- Disaggregated or sharded metadata for scalability
- Like Tectonic, ADLS [42] and HopsFS [35] increase filesystem capacity by disaggregating metadata into layers in separate sharded data stores. Tectonic hash-partitions directories, while ADLS and HopsFS store some related directory metadata on the same shards, causing metadata for related parts of the directory tree to be colocated. Hash partitioning helps Tectonic avoid hotspots local to part of the directory tree. ADLS uses WAS’s federated architecture [17] for block storage. In contrast, Tectonic’s block storage is flat.
- Like Tectonic, Colossus [28, 32] provides cluster-wide multi-exabyte storage where client libraries directly access storage nodes. Colossus uses Spanner [21], a globally consistent database to store filesystem metadata. Tectonic metadata is built on a sharded key-value store, which only provides within-shard strong consistency and no cross-shard operations. These limitations have not been a problem in practice.
- Blob and object stores
- Compared to distributed filesystems, blob and object stores [14, 18, 36, 37] are easier to scale, as they do not have a hierarchical directory tree or namespace to keep consistent. Hierarchical namespaces are required for most warehouse workloadsther large-scale storage systems. Lustre [1] and GPFS [45] are tuned for high-throughput parallel access. Lustre limits the number of metadata nodes, limiting scalability. GPFS is POSIX-compliant, introducing unnecessary metadata management overhead for our setting. HBase [9] is a key-value store based on HDFS, but its HDFS clusters are not shared with a warehouse workload. We could not compare with AWS [2] as its design is not public.
- Multitenancy techniques
- Tectonic’s multitenancy techniques were co-designed with the filesystem as well as the tenants, and does not aim to achieve optimal fair sharing. It is thus easier to provide performance isolation compared to other systems in the literature. Other systems use more complex resource management techniques to accommodate changes in tenancy and resource use policies, or to provide optimal fair resource sharing among tenants [25, 48, 49]. Some details of Tectonic have previously been described in talks [39, 47] where the system is called Warm Storage.
- Distributed filesystems with a single metadata node
Design and Implementation of an Object Store with Tiered Storage
B𝜀-tree 拓展版本
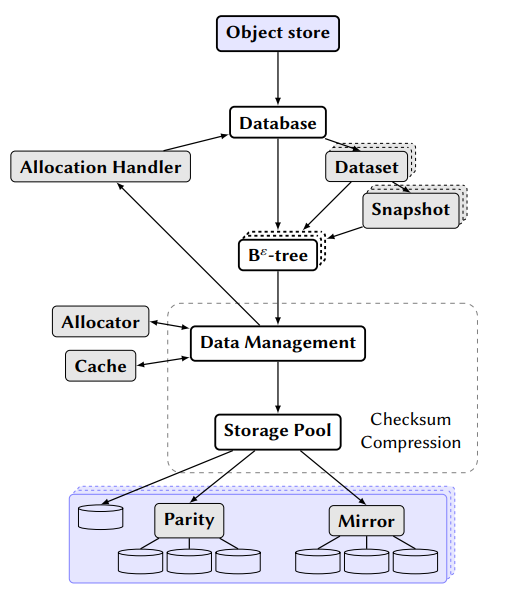
B𝜀-tree 存储堆栈由几个组件构成,如图 2.2 所示,其中大多数实现了一个接口,以允许每个角色的不同实现互操作
- 数据库层管理数据集和快照,用用户友好的 API 包装它们,并将其他组件连接到一个功能系统中,包括例如数据库配置和数据库超级块的初始读取
- B𝜀-tree 上的操作与数据管理层交互以根据需要处理树操作和重塑,在此期间它可以简单地从数据管理层请求数据库对象
- 数据管理层为上层提供大部分不透明的对象,而无需了解其中包含的树节点。它连接到缓存系统以最小化磁盘访问,但会在缓存未命中时查询存储层。在另一个方向上,它能够循环分配段,从这些段请求块范围,然后在通知分配处理程序将分配保存在分配位图中之后指示存储层执行实际写入
- 存储层是围绕模块化虚拟设备构建的,也称为 vdevs,可以以树状方式组织。叶 vdev 可以是操作系统文件,其中包括原始块设备,如磁盘分区。然后可以将这些叶 vdev 聚合为两种不同的新 vdev 类型之一:
- Mirror: 一个镜像vdev 将接收到的数据写入其所有子 vdev,并且可以承受除最后一个 vdev 之外的所有 vdev 的故障。 尽管对最小和最慢设备的容量和写入速度分别有限制,但镜像可以在其子 vdev 之间分配读取以超过单个设备的读取传输速度
- Parity: 奇偶校验 vdev 将其写入分配给它的子节点,并生成奇偶校验数据以维持任何单个子节点 vdev 的故障。 与可以选择仅从单个磁盘读取的镜像 vdev 不同,奇偶校验 vdev 必须从其多个子磁盘中读取vdevs 来重建请求的数据,同样允许比单个磁盘更高的读取吞吐量
相关论文2 — 统一存储应用
论文3 (Databricks) Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
- 核心:用云对象存储作为存储底座来实现数据仓库有两个重要的问题, 一是不支持事务, 二是小文件导致的性能问题。Delta Lake核心其实就是在云对象存储上引入了一个新的中间层, 来解决上述问题
- 背景
- 云对象存储很适合用来作为数据仓库(Data Warehouse)和数据湖(Data Lake)的存储底座
- 传统系统和云对象存储并不能实现高效和可变的表格存储, 也就导致了难以在它们之上实现数据仓库功能
- 这是因为与HDFS等分布式文件系统或DBMS中的自定义存储引擎不同, 大多数云对象存储仅仅是键值存储, 没有跨键一致性保证. 另外它们的性能特征也与分布式文件系统有很大不同
- 目前在云对象存储中存储关系数据集最常见的方法是使用列式文件格式, 如Parquet和ORC, 其中每个表作为一组对象(Parquet或ORC文件)存储, 可能按某些字段聚集成分区(例如, 每个日期的单独一组对象)
- 只要目标文件比较大, 这种方法可以为扫描工作负载提供可接受的性能. 但是, 在如下几种复杂的场景中就不行了:
- 由于云对象存储中多对象更新不是原子的, 所以多个查询之间没有隔离: 例如, 如果一个查询需要更新表中的多个对象(例如, 删除表中所有Parquet文件中关于一个用户的记录), 其他查询将看到部分更新, 因为查询单独更新每个对象. 回滚写操作也很困难:如果更新查询崩溃, 表就处于部分更新的不一致状态
- 对于拥有数百万个对象的大表, 元数据操作的开销很大. 例如, Parquet文件包括带有最小/最大统计信息的页脚, 可用于在选择性查询中跳过读取它们. 在HDFS上读取这样的页脚可能需要几毫秒, 但云对象存储的延迟要高得多, 这些数据跳过检查可能比实际查询花费更长的时间
- Delta Lake是云对象存储之上具有ACID特性的表格存储层:使用本身存储在云对象存储中的预写日志, 以ACID的方式维护关于哪些对象是Delta表的一部分的信
- Delta Lake除了原表之外, 还新增了一种预写日志(称为Transaction Log), 并以ACID的方式来维护, 这样就可以支持事务。关于Transaction Log的具体内容, 下文会详细分析. 有了事务特性之后, Delta Lake还可以支持许多传统数据湖无法支持的特性, 比如:
- 时间旅行(Time travel)
- UPSERT, DELETE和MERGE操作(UPSERT, DELETE and MERGE operations)
- 高效的流式I/O(Effificient streaming I/O)
- 缓存(Caching): 因为Delta表及其日志中的对象是不可变的, 所以计算集群节点可以安全地将它们缓存在本地存储中. Databricks云服务中利用它来为Delta表实现一个透明的SSD缓存
- 数据分布优化(Data layout optimization): 可以自动优化表中对象的大小和数据记录的聚集性(例如, 使用Z-order存储记录, 以实现多个维度的局部性), 而不会影响运行的查询
- Schema演化(Schema evolution)
- 审计日志(Audit logging)
- 略…
论文4 (Databricks) Photon: A Fast Query Engine for Lakehouse Systems
- 。。。
相关论文3 — 统一存储负载
论文5 (SingleStore) Cloud-Native Transactions and Analytics in SingleStore
背景
- SingleStoreDB(S2DB) 是最早支持HTAP (Hybrid Transaction/Analytical Processing) 数据库之一(2012)
- S2DB 的一个集群有两种 nodes,aggregator nodes (调度) 和 leaf node (分区 + 计算)。
- 用户提供 shard key (可以是多个 column),tables 根据 shard key 被 hashed 到 多个 partitions 上。
- 一个 partition 要么是 master (可以 read/write) 要么是只读 replica。update 信息从 master 到 replica 的同步是实时的
- query 默认只会用 master partition
SingleStore database engine主要特点:
- 计算存储分离架构
- unified table storage (又称 universal storage)
存储格式
S2DB 内部包含两种 storage types:an in-memory rowstore backed by a lockfree skiplist,和一个 disk-based columnstore
- 在内存 rowstore 中,每行 (称为一个 node) 会存一个 linked list of versions 来支持 MVCC。写入 commit 前会写 log。然后也会定期给内存 rowstore 打 snapshot,恢复的时候根据 snapshot + log 恢复
- columnstore 部分的数据会被切成 segments (存 disjoint subset of rows,以文件的形式存在)。每个 segment 内列数据按行顺序存放但单独压缩。segment 的 metadata 放在 in-memory rowstore 中
- 每个 segment 还会包含一个 delete bitset,主要为了 OLAP 设计,同时也加入了一些 TP 的考虑,比如 encoding 后要能 “seekable”,这样可以避免解压所有 rows。如果指定了 sort key,segments 内部会排序,segments 之间会使用类似 LSM-tree 的方式进行后台排序。对于每个 columnstore table,S2DB 同时也会开一个 in-memory rowstore table 来支持少量写,并后台定期 merge 到 columnstore (操作类似 LSM L0 到 L1)。columnstore 计算可以使用 vectorized execution,对于部分算子,如 group by 和 hash join,可以直接在未解压的数据上进行
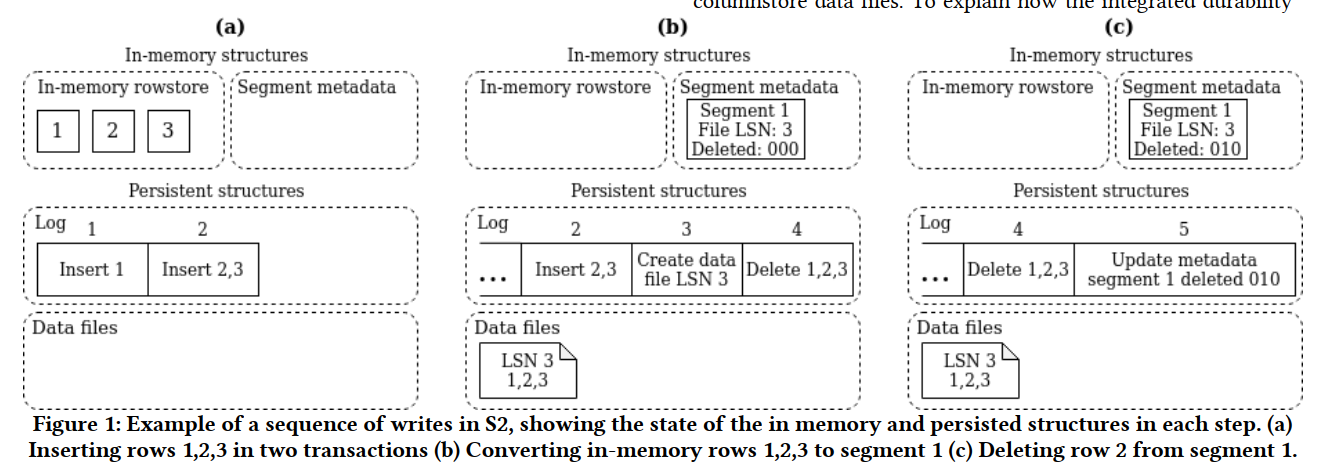
计算存储分离
统一表存储
- 原来的S2DB 需要选择rowstore 还是 columnstore 。这是非常困难的,因为这需要让用户自己去判断涉及这张表的 workload 是更偏向于 TP 还是 AP,如果很均衡那就无了。
- 为了解决这个问题,S2DB 提出 Unified table storage,将原本的 columnstore 进行优化来支持 AP 和 TP。其采用基于 LSM tree 的方式,将数据写入连续的 chunks 中。为了加速 TP 性能,做了如下优化:
- 做了个保存在内存中的 delete bitset,而不是像其他 LSM tree 实现(e.g., RocksDB)那样用 tombstone entry 来标记 delete (merge on read,读放大太大)
- 细读一下…
- 和其他 LSM tree 实现类似,写入部分依然放在 in-memory 中 (需要额外处理 metadata)
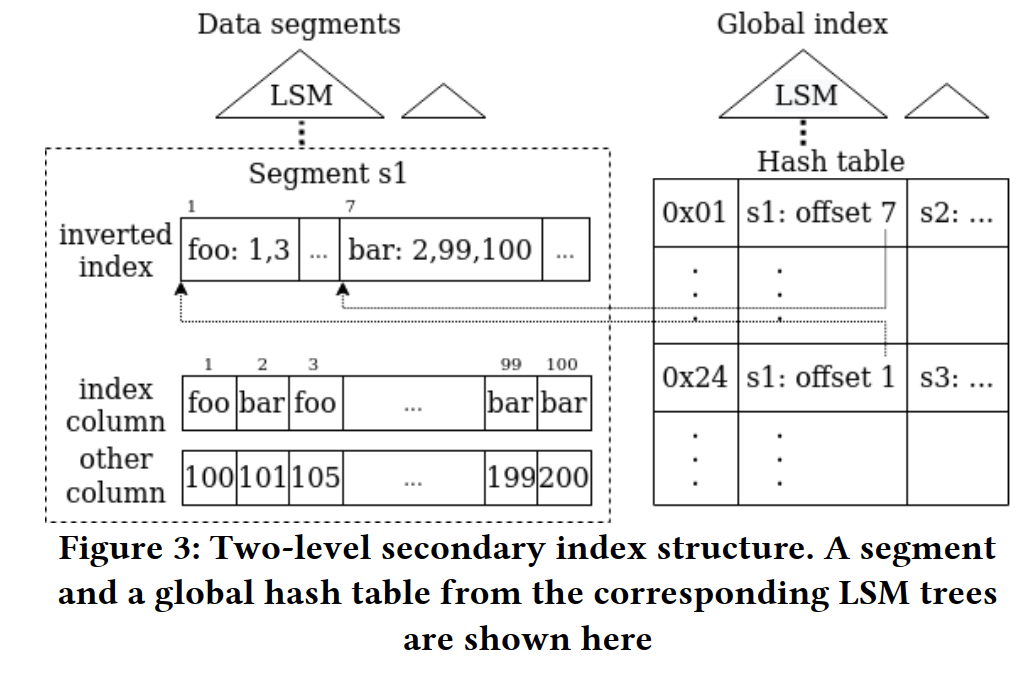
- 构建了大量支持 LSM tree 的 secondary index 来支持 efficient point access。比如 bloom filter 和 inverted index 来过滤不需要访问的 segments。以及 S2DB 自己的 two-level index structure 来定位 segment 和 offset
- row-level lock 来避免 blocking
- 做了个保存在内存中的 delete bitset,而不是像其他 LSM tree 实现(e.g., RocksDB)那样用 tombstone entry 来标记 delete (merge on read,读放大太大)
相关
- AnalyticDB: Real-time OLAP Database System at Alibaba Cloud (VLDB 2019
- SingleStore并行化
论文6 (ScaleStore) ScaleStore: A Fast and Cost-Efficient Storage Engine using DRAM, NVMe, and RDMA
- 一种新颖的分布式存储引擎,它利用DRAM 缓存、NVMe 存储和 RDMA网络同时实现高性能、成本效益和可扩展性
- …
论文7 Proteus: Autonomous Adaptive Storage for Mixed Workloads
- 背景:HTAP (Hybrid Transaction/Analytical Processing)
- 对于数据规模逐步增大的业务来说,分布式数据库很好地满足了它们对 TP 性能水平扩展的需求
- 但由于存储格式或者设计目标上的差异,这些系统不一定能满足业务对于历史数据的 AP 分析需求
- 核心策略:提出一些根据 workload 自适应存储的策略/算法,包括一些几部分:
- Format:根据数据被访问的情况决定使用行存/列存
- Tier:内存/磁盘,选择合适的存储介质,比如冷数据放在磁盘里
- 排序/压缩:对于列存数据,使用排序可以借助二分查找或者 merge-join 等算法加速,使用压缩有效地减少占用的存储空间
- Replication:此处侧重的不是我们在分布式存储中为了可靠性做的副本,而是为了加速查询刻意进行的数据冗余以支持类似 local join 之类的场景
- Proteus 根据 workload 的实际情况,可以对系统内实际数据存储做出的调整决策,比如说数据原先是行存的,但经过一段时间的访问后,Proteus 判断列存更为合适,则将在运行时进行相应的调整
- …
相关论文 4 — 虚拟地址空间
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上物理内存通常被分隔成多个内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。此外,虚拟内存技术可以使多个进程共享同一个运行库,并通过分割不同进程的内存空间来提高系统的安全性
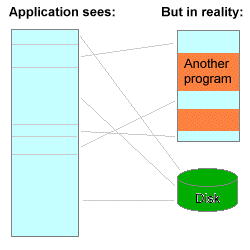
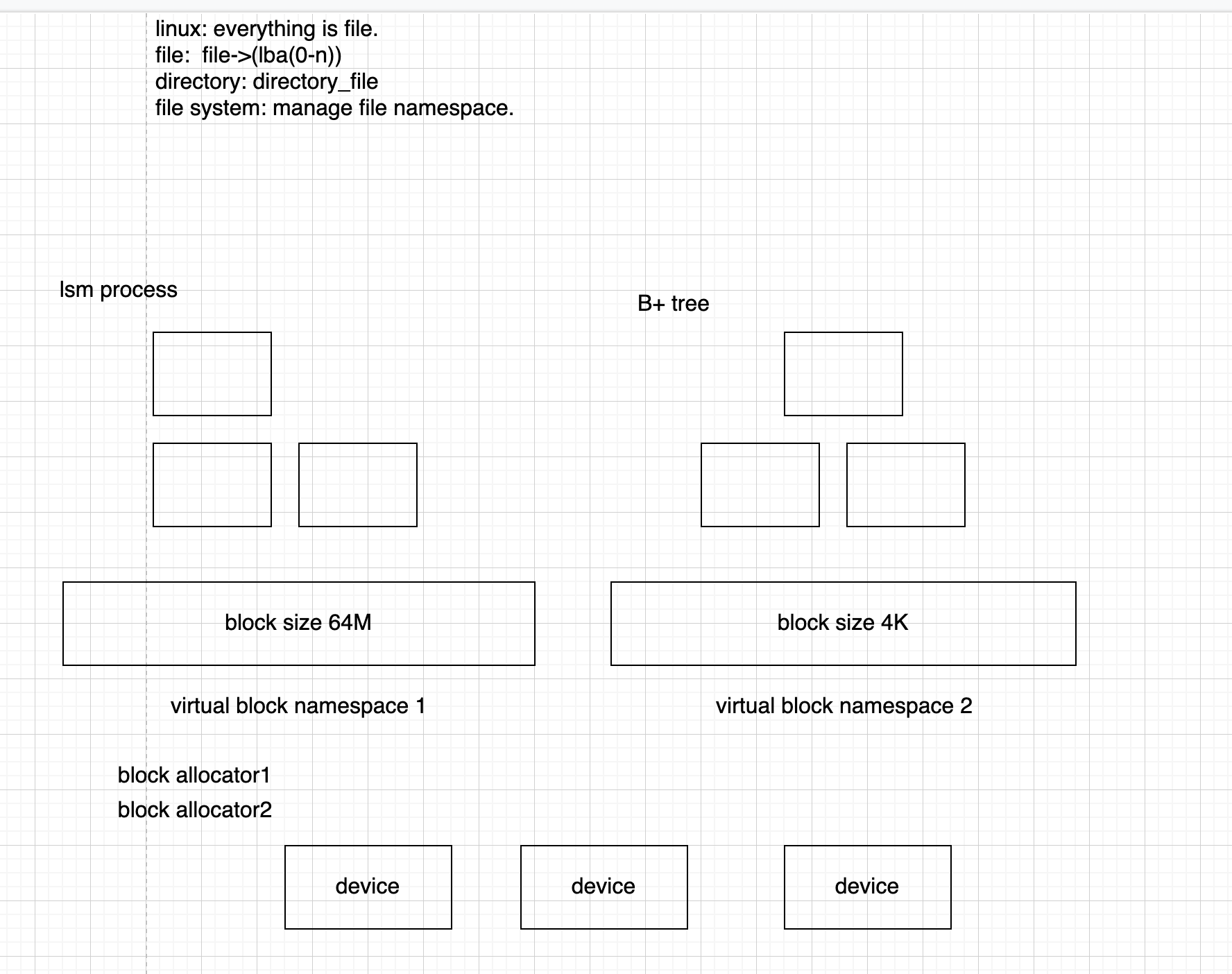
能否和我们设计理念相结合?
都是基于SCM的文件系统
- 在虚拟内存空间上构建文件系统,并利用内存管理单元 (MMU) 将文件系统地址映射到 SCM 上的物理地址
A New Design of In-Memory File System Based on File Virtual Address Framework
持久内存的新兴技术,如 PCM、MRAM,为在内存中保存文件提供了机会。传统的文件系统结构可能需要重新研究。尽管针对内存提出了几种文件系统,但它们中的大多数在没有充分利用处理器端硬件的情况下性能有限。本文提出了一个基于新概念“文件虚拟地址空间”的框架。设计并实现了一种文件系统,即可持续内存文件系统(SIMFS),它充分利用了文件访问路径上的内存映射硬件。首先,SIMFS 将打开文件的地址空间嵌入到进程的地址空间中。然后,文件访问由内存映射硬件处理。还为建议的 SIMFS 提出了几种优化方法。进行了广泛的实验。实验结果表明,SIMFS 的吞吐量比最先进的内存文件系统实现了显着的性能提升
SCMFS : A File System for Storage Class Memory
Efficient persistent memory file systems using virtual superpages with multi-level allocator
相关论文 5 — 共享日志
Mahesh Balakrishnan Meta公司
2015-2019耶鲁副教授,与Microsoft合作提出共享日志CORFU系列 ,在此基础上,和Facebook合作提出Delos系统
- CORFU: A Shared Log Design for Flash Clusters (NSDI’12)
- https://github.com/CorfuDB/CorfuDB
- Gecko: Contention-Oblivious Disk Arrays for Cloud Storage (FAST’13)
- Tango: Distributed Data Structures over a Shared Log (SOSP’13)
vCorfu: A Cloud-Scale Object Store on a Shared Log (NSDI 2017)
- The FuzzyLog: A Partially Ordered Shared Log (OSDI’18)
- Virtual Consensus in Delos (OSDI’20)
- Log-structured Protocols in Delos (SOSP’21)
### CORFU: A Shared Log Design for Flash Clusters
- NSDI’12,CORFU 是一个分布式 SSD 集群,面向客户端提供了追加写和基于偏移的随机读取操作
- Shared Log是一些分布式系统的一种的实现思路。CORFU是一个 Shared Log的实现,它主要是面向SSD设计。CORFU可以被视为一个分布式的SSD,同时提供普通的SSD不能支持的功能,包括容错、可拓展性和垮地理区域复制等。
- 背景:传统上,在构建大规模存储系统时,系统设计者不得不在性能和安全性之间做出选择。闪存有可能极大地改变这种权衡,提供持久性以及高吞吐量和低延迟。商用闪存驱动器的出现为数据中心创造了新的机会,使在磁盘或RAM基础设施上不切实际的新设计成为可能。在本文中,我们假设闪存为数据中心内的共享日志设计打开了大门,其中数百台客户机附加到单个日志的尾部,并并发地从日志体读取日志。共享日志是一种功能强大且通用的原语,用于确保在出现故障和异步时的强一致性。它可以在分布式系统中扮演多种角色:用于一致复制的共识引擎;用于隔离和原子性的事务仲裁器;副本创建的执行历史、一致性快照和geo-distribution;即使是主要的数据存储,也会利用底层媒体的快速附加。Flash是实现可伸缩共享日志的理想介质,支持对日志主体的快速、无争用的随机读取和对日志尾部的快速连续写入
- 共享日志(shared log)是由CORFU(Paxos、Corfu、Delos都是希腊岛屿名)提出的一种大规模闪存存储系统
- CORFU将大量闪存/SSD通过FPGA网络连接起来形成单个共享日志,从关键路径里剔除了通用的服务器,最终构建出一种能耗低时延低的专用存储硬件,但也可以在通用服务器和通用网络上实现
- CORFU提出的共享日志在存储层面实现复制状态机,是一种共识(Consensus)引擎,达到与Raft/Paxos相同的效果
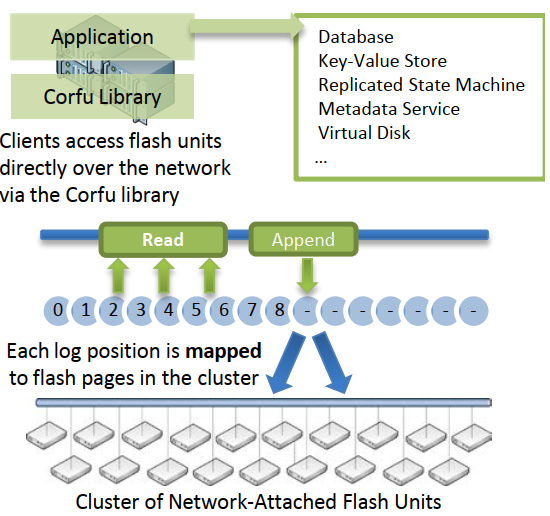
核心策略:Shared Log;客户端为中心
相比传统的Raft/Paxos,CORFU在存储硬件层面实现全序(total order),把大量功能放到客户端实现,I/O吞吐更高,时延更低
CORFU将几个闪存单元形成一个复制组,多个复制组形成闪存集群,把每个共享日志中的位置都映射到一个复制组上的某个闪存页,用专门的sequencer节点帮助定位日志的末尾在哪个闪存单元
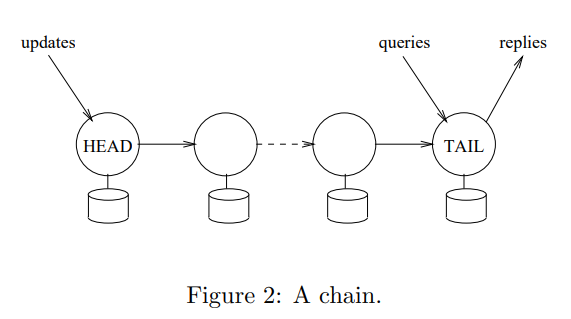
采用链式复制 (chain replication):每次写操作都会以确定顺序写复制组的各个闪存单元,等每个闪存单元确认写完成后再继续下一个;读操作则一般直接从这个复制链的末端读,如果确定没有进行中的写操作,则也可以从这个复制链的中间或起点读
chain replication for supporting high throughput and availability, OSDI’04, FAST公司(微软收购)
- 简适用于高吞吐量和强一致性要求的场景(高并发读):只有一个节点负责处理读请求,而且不用等待其余任何副本的写入请求,而在主从结构中,主节点的读请求需要在等待所有副本返回之后才能应答读请求
- 写性能被牺牲:需要链上的所有副本都串行写入成功后才可返回响应
CORFU与传统的复制状态机实现不同之处在于:
- 并行优势:传统复制状态机在处理update stream时是不能切分成多个update stream并行的,一旦并行就意味着损失原子性。CORFU却天然把global log中的offset映射到不同的闪存上,读写不同的闪存的IO是完全可以并行的
- 将I/O与顺序解耦:传统复制状态机只允许leader机器写,保证命令序列的全局顺序,系统吞吐受限于leader机器的I/O capacity。CORFU的吞吐则只受限于sequencer处理token发放给clients的速度
- 硬件约束:这些闪存单元是用廉价且低能耗的控制器连接起来的,因此闪存设备是没办法主动发起通信的,只能用一种用户驱动的协议保证一致性。
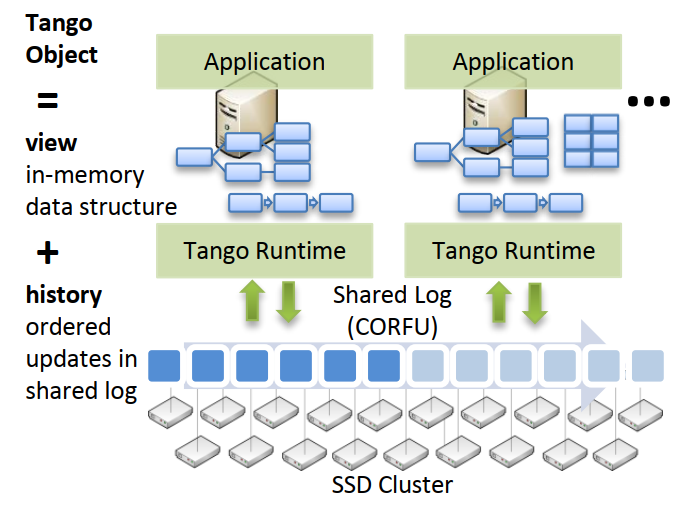
Tango: Distributed Data Structures over a Shared Log
核心思想:
- Tango 使客户端能够基于相同的单个共享日志构建不同的数据结构
- Tango 还提供跨数据结构的事务
背景:近年来,云平台通过为分区存储(Amazon S3或者Azure Blob Store)和和并行计算(MapReduce, Dryad)提供简单的、以数据为中心的接口,使可伸缩应用程序的开发大众化。开发人员可以使用这些抽象轻松地构建某些类的大规模应用程序——例如面向用户的互联网服务或后端机器学习算法——而无需考虑底层的分布式机器
问题:
- 目前的云平台提供的应用程序很少支持存储和访问元数据:应用程序元数据通常以数据结构的形式存在,如映射、树、计数器、队列或图;真实的例子包括文件系统层次结构、资源分配表、作业分配、网络拓扑、重复数据删除索引和来源图。元数据更新通常由跨不同数据结构(或单个数据结构任意子集)的多操作事务组成,同时需要原子性和隔离性;例如,将节点从空闲列表移动到分配表,或将文件从名称空间的一部分移动到另一部分。同时,应用程序元数据需要具有高可用性和在出现故障时的持久性
- 现有的存储元数据的解决方案不提供对具有持久性和高可用性的任意数据结构的事务性访问。云存储服务(例如SimpleDB)和协调服务(例如,ZooKeeper和Chubby)提供持久性、高可用性和强一致性。但是,每个系统都针对特定的数据结构这样做,并且对跨多个操作、项或数据结构的事务的支持有限,甚至不支持。传统的数据库支持事务,但是可伸缩性有限,而且不能超过任意的数据结构
tango
The FuzzyLog: A Partially Ordered Shared Log
- 背景1:大型数据中心系统依赖于控制平面服务control plane services ,如文件系统命名节点、SDN控制器、协调服务和调度器。这类服务通常最初构建为单服务器系统,将状态存储在本地内存数据结构中。持久性、高可用性和可伸缩性等属性通过跨机器分布服务状态来改进
- 背景2:为这样的服务分配状态可能很困难;它们对低延迟和高响应性的要求排除了使用固定api(如键值存储)的外部存储服务,而自定义解决方案可能需要将应用程序代码与混合的分布式协议(如Paxos和两阶段提交(2PC),单独复杂,分层时缓慢/低效,且难以合并
- 共享日志:最近提出的一类设计以共享日志抽象为中心,通过全局共享日志汇集所有更新,以启用容错数据库、元数据和协调服务、键值和对象存储和文件系统命名空间。 基于共享日志构建的服务是简单、紧凑的层,将高级 API 映射到共享日志上的追加/读取操作,这是强一致性、持久性、故障原子性和事务隔离的来源。 例如,一个共享日志版本的 ZooKeeper 使用 1K 行代码,比原系统低一个数量级
- 不幸的是,共享日志的简单性要求强加系统范围的总顺序,这是昂贵的,通常是不可能的,而且通常是不必要的。
- 以前的工作表明,一个集中的,偏离路径的测序器可以使这样的总秩序在中间规模可行(例如,几十台机器组成的小型集群)。然而,在更大的范围内——在系统大小、吞吐量和网络带宽/延迟方面——强加一个总顺序会变得昂贵:如果机器分散在网络上,通过排序器来排序所有更新会限制吞吐量并降低操作速度。
- 对于跨越地理区域的部署,可能不可能有一个总顺序:一个网络分区可能会从序列器或实现日志的服务器的仲裁中切断客户端
- 另一方面,总顺序通常是不必要的:更新不相交的数据(例如,map中的不同键)不需要排序,而接触相同数据的更新可能会来回,因为应用程序需要弱一致性保证(例如,因果一致性)
Virtual Consensus in Delos
OSDI 2020 Best Paper!
核心
- 生产环境中实现在线切换consensus协议
- 分离数据与控制,允许滚动更新的虚拟共享日志
背景:虽然近年不断有新的分布式共识协议的工作出现,但由于生产环境中涉及到共识的系统通常集成度较高,更换共识协议意味着需要对系统做出非常大的改动。无论是出于工作量,还是出于稳定性来考虑,一些较新的共识算法都很难得到采用。因此目前成熟的业界常用的系统通常都在使用有着几十年历史的共识协议。即使是一些使用较新共识协议的系统,他们通常也都是从零开始搭建的,后期想要在这些系统中改为使用更为先进的共识算法也是一件成本非常大的事情
问题:除了在部署协议上的问题,增量的修改共识协议的实现也不是那么容易的。现有的分布式共识协议内的数据流(用于数据的fault tolerance)与控制流(用于更新consensus group的配置)通常是紧耦合的,想要在这样的系统中进行增量的修改几乎是不可能的任务。这大大增加了在生产环境中实现一个新协议的开发量
中间层:观察到数据库具有相似的结构,底部是共识协议,顶部是复制状态机。很多状态机使用可以跨不同 API 重用的通用逻辑
本文:介绍了VirtualLog,这是Facebook在生产环境中使用的Delos这一数据库中的共识组件。VirtualLog可以快速在不同的共识算法之间快速切换,并且大幅简化了可以接入的共识算法所需要实现的功能。具体来说,VirtualLog是指Database与具体一致性协议的实现(Loglet)之间增加的一层新的抽象:
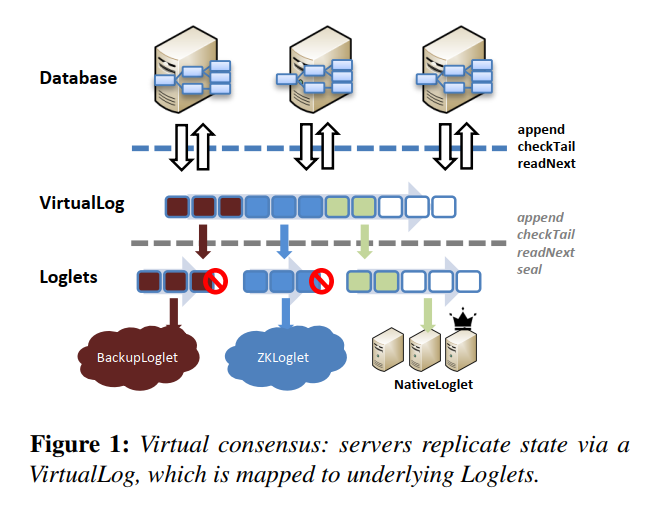
- 每个Loglet即指一个使用过的共识算法的实例,而VirtualLog层将他们组织起来,对外暴露了一个shared log的抽象。这一log的抽象会与下层的Loglets建立log entry之间的映射关系。当需要切换共识协议时,我们只需要让virtualLog将后续的log entry都交由新的loglet去达成共识即可。因此在VirtualLog中,共识协议的切换可以做到无downtime的在线进行
- 借助于VirtualLog在不同Loglets之间切换的能力,我们可以简化Loglets需要实现的功能。上文提到共识算法中的Reconfig会为开发带来非常高的复杂度。但在VirtualLog中,我们可以将Reconfig前后的共识实例作为两个单独的Loglet,而非在一个Loglet内部进行Reconfig,从而一个Loglet可以是固定成员、固定Leader的一个实例,而不再需要提供Reconfig的功能。当Loglet出现failure而需要Reconfig的时候,只需要通知VirtualLog层切换到下一个Loglet即可。基于此,除了可以不提供Reconfig,我们也可以在一定程度上降低对Loglet的高可用的要求
- 一些样例的Loglet实现:包括一个类似于固定Leader的MultiPaxos的NativeLoglet,以及一个类似于Mencius用Round Robin的方式来记录log entry的StripedLoglet
- 限制:较为突出的是Loglet必须是支持total order的协议,而类似EPaxos这样的根据entry内容而允许一定程度的可交换性的partial order的协议则不能实现在VirtualLog中。
- 测试:Delos展示了在真实生产环境中进行Loglet的切换以提升性能,同时不产生任何downtime的例子。当workload发生变化时,Delos也能通过切换使用不同策略或硬件的Loglet来提高系统的性能同时提高资源利用率。Evaluation中还测试了VirtualLog引入的开销,结果表明VirtualLog引入的latency占比不到10%,同时几乎不影响系统的吞吐。
Log-structured Protocols in Delos
Facebook控制面板系统Delos上的最新进展
- 演讲https://www.youtube.com/watch?v=4EGArLVavbg
- 官网Delos: Simple, flexible storage for the Facebook control plane
背景:在实际业务场景的处理过程中,系统栈分为数据面(Data Plane)和控制面(Control Plane)两部分
数据面的代表是各种业务数据库,或者Web服务、机器学习等服务系统
控制面指在这些系统运行过程中,需要保证的一些诸如调度、一致性、分区问题的控制服务,例如ZooKeeper和键值存储等。而这些控制面的服务也需要有一个数据库保存一些元数据,而这个数据库既需要保证容错,又需要兼容多种API
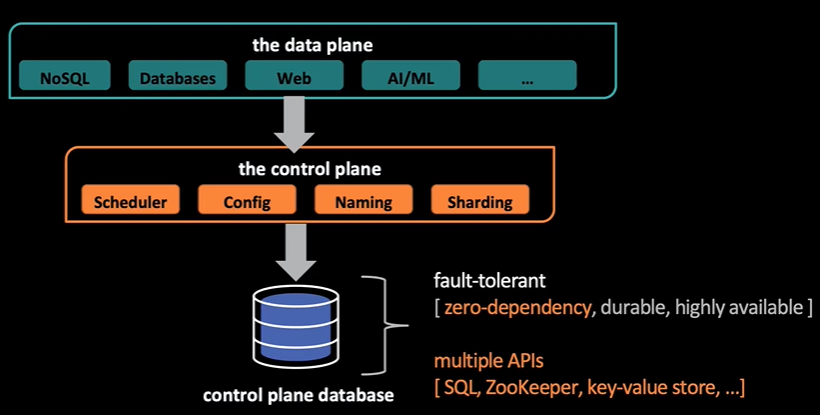
Delos:若为每一个数据面的系统定制一套控制面的服务,将会导致重造轮子的浪费问题。而Delos就是Facebook解决该问题的一个平台。在数据面和控制面中加一层Delos平台,使得两者能够解耦。在OSDI’20中,Delos发表了关于底层的多种一致性协议给上层一个统一的虚拟化一致性(Virtual Consensus)的工作
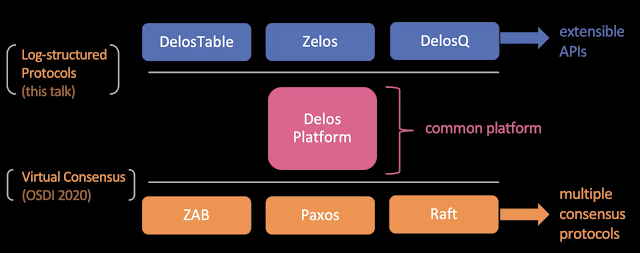
本文主要介绍的是上层应用是如何和Delos平台进行交互的
- 应用与Delos的交互,基于一个重要的观察,即数据库的SMR(State Machine Replication,状态机备份)是一个常用的架构,而共享日志(Shared Log)是SMR中用于同步数据的重要手段。因此,Delos对于上层的接口也使用了共享日志。这样,就从Delos这一层,将上层的API进行了统一(都是用共享日志的形式)
- 尽管Delos这样的设计就可以对上层的API进行统一,但是需要对于每一个上层应用都需要将接口统一到底层共享日志的API,同时会对上层应用的设计带来不灵活
分层状态机备份(layering SMR)
- 核心思想:将平台状态机分解为许多细粒度状态机,并将它们分层为协议状态,就像网络数据包分层一样
- 在应用层的每一个引擎的操作,都会对自己下一层引擎发起propose的请求,最后一层层写到共享日志层中。而最后写到共享日志中的日志,也像网络包一样包含着一层层的payload。
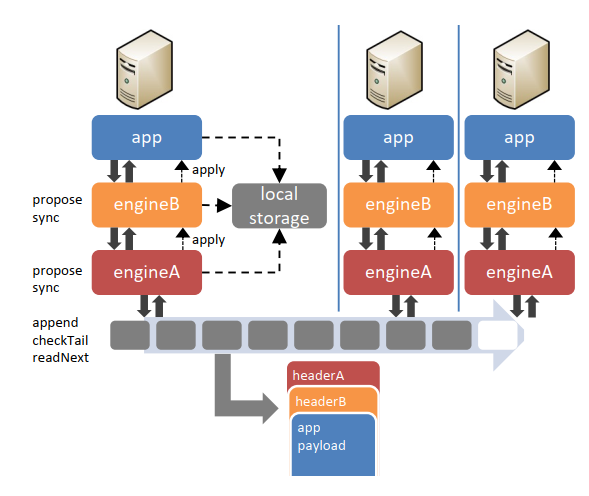
- 通过这样分层SMR的共享日志设计,Delos能够将应用栈中的层次解耦,因此能够很方便地进行增加功能、代码复用、以及提升性能(如加一层batch层进行提升吞吐量,以及减少lease所带来的时延等)。同时,在共享日志上,也允许使用多个应用栈。
产品数据上,基于分层SMR的共享日志协议,可以通过减少中间的层次和重复的代码,带来100倍的延迟下降,以及2倍的吞吐量提升
相关论文6 — Hadoop
HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases
Hadoop FS基础上的一个进化,主要讨论如何优化HDFS的NameNode
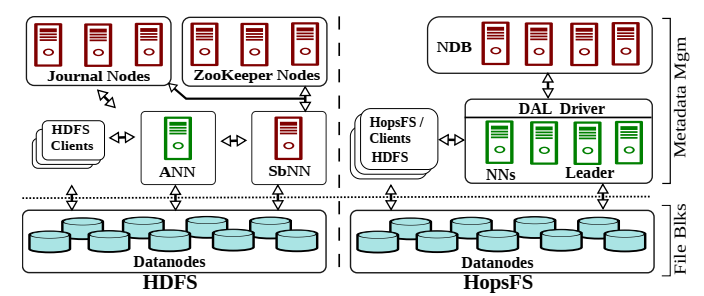
背景:分布式文件系统大规模并行处理系统的重要组件,现在PB级的大规模数据存储已经非常普遍,层次化的文件系统的元数据管理成为了文件系统的瓶颈。现在主流的分布式文件系统通常都是讲元数据的管理存储在单个节点或者存在共享的网络磁盘文件系统,如HDFS,GFS等。也有一些系统静态地将命名空间分片到不同的节点达到扩展元数据的目的,但是这种静态的分片对于一些操作如move等很不友好,而且随着命名空间的增多,需要管理员手动的重新调整元数据和命名空间的映射。
核心:使用NewSQL保存元数据方法,解决HDFS元数据管理的瓶颈。HopsFS使用的MySQL Cluster(一个In-memory的shared-nothing分布式事务数据库)保存HDFS的inode,block,replica等信息,设计了元数据信息存储的表结构和partion方法,提供高效的访问树形目录结构的方式,并且设计了一套并发访问的方案。相比没有修改的HDFS,元数据的存储容量提高了至少37倍,在Spotify的真实负载下,吞吐相比HDFS提高了16~37倍。
- MySQL Cluster is a shared-nothing, replicated, inmemory, auto-sharding, consistent, NewSQL relational database
基本架构
- 对于高可用性,HDFS需要一个Active NameNode (ANN),至少一个Standby NameNode (SbNN),至少3个Journal node用于元数据更改前写日志的基于仲裁的复制,至少3个ZooKeeper实例用于基于仲裁的协调。
- HopsFS支持多个无状态的namenode来访问存储在NDB数据库节点中的元数据。在使用了NewSQL(MySQL Cluster),这些复杂容错等的操作都交给NewSQL去完成,而且NewSQL提供的事务处理能力也为操作的实现提供了很大的方便。
HDFS的结构映射到SQL的关系模型之上
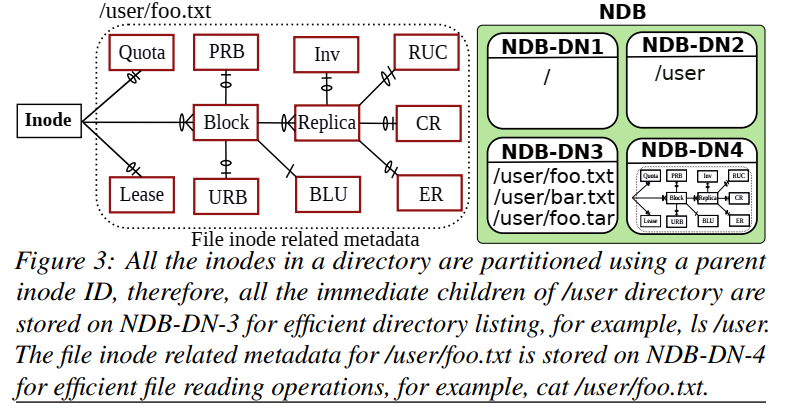
HopsFS:基本的tables的设计
- Inode table,这里的inode和普通的单机的文件系统中的inode类型,也是一个文件or目录的一些元数据,这个table中的每一行都代表了一个文件or一个目录。元数据比如有这个inode包含的blocks信息,还是就是blocks的文件信息,另外,由于FS是有树形的结构的,这里还会好看了父节点的信息;
- 存储格式:以父目录 inode id + 目录或文件名作为 key,元数据作为 value 存储
- Block table,Block的信息保存在table中;
- Replica table,Block会被复制几份保存,Block副本的信息保存在这里;
- Under-replicated blocks table (URB),处于复制状态的Blocks的信息;
- Pending replication blocks table (PRB),等待被复制的Blocks的信息会被保存到这里;
- Corrupted replicas (CR) table,被发现发生错误的Block的信息会被保存到这里;
- Replica under construction (RUC) table,保存客户端写入一个新的Blocks的副本时,这个Blockxx会被保存在这里;
- Excess replicas (ER) table,当一个暂时故障的DataNode恢复之后,可能造成某些Blocks的副本的数量超过要求,这个超出的Blocks的信息保存在这里;
- Invalidation (Inv) table,保存被列入删除的Blocks的信息;
- Inode table,这里的inode和普通的单机的文件系统中的inode类型,也是一个文件or目录的一些元数据,这个table中的每一行都代表了一个文件or一个目录。元数据比如有这个inode包含的blocks信息,还是就是blocks的文件信息,另外,由于FS是有树形的结构的,这里还会好看了父节点的信息;
例子:
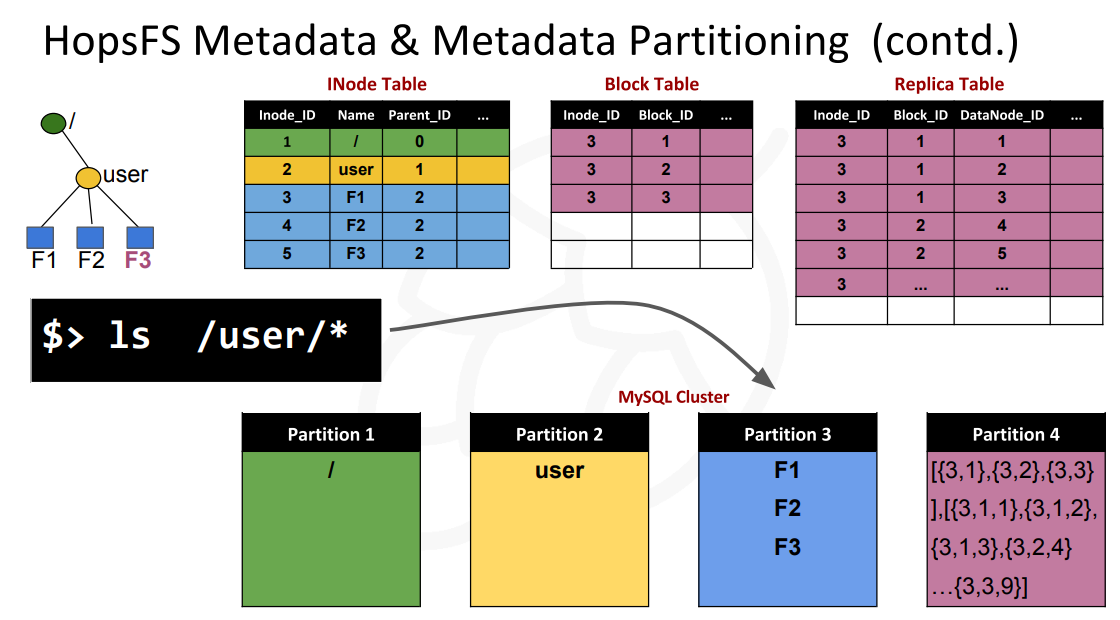
为了实现更好的可拓展性和处理hotspot的问题,HopsFS这里使用的方法是分区的方法,使用的分区的方式是根据inode的信息。这里要处理下面几个问题:
- 根据inode分区的时候如何处理一个目录下面的文件:根据父节点的inode的ID来分区,这样同一个目录下面的文件和目录会被分到一个分区;而文件or目录相关的元数据如blocks、副本和checksum等,直接根据文件or目录本身来分区就可以了;
- root inode的问题:root inode会被非常频繁的使用,所以这里在所有的NameNode都缓存了root inode的信息,而且root inode本身是不可变的;
- root固定保存的另外一个问题就是最上层的目录也很有可能成为热点,而根据父节点的ID分区的方式有导致了这些信息被保存在一个分区上面,这样也是一个问题。这里的解决办法是在这一层是用另外的分区的方式:
- HopsFS使用一种可配置的目录分区方案,其中通过散列子目录的名称对顶级目录的直接子目录进行伪随机分区。默认情况下,HopsFS只对文件系统层次结构的前两个级别(即根目录及其直接后代目录)进行伪随机分区。
其他:细粒度锁机制,事务操作,大规模操作的处理
DanceNN
字节HDFS 元数据系统:NameNode -> DanceNN v1 -> Distributed DanceNN
NameNode,最开始公司使用 HDFS 原生 NameNode,虽然进行了大量优化,依然面临下列问题:
- 元数据(包括目录树,文件和 Block 副本等)全内存存储,单机承载能力有限
- 基于 Java 语言实现,在大内存场景 GC 停顿时间比较长,严重影响 SLA
- 使用全局一把读写锁,读写吞吐性能较差
- 随着集群数据规模增加,重启恢复时间达到小时级别
DanceNN v1 的设计目标是为了解决上述 NameNode 遇到的问题。主要设计点包括:
- 重新实现 HDFS 协议层,将目录树文件相关元数据存储到 RocksDB 存储引擎,提供 10 倍元数据承载
- 使用 C++ 实现,避免 GC 问题,同时使用高效数据结构组织内存 Block 信息,减少内存使用
- 实现一套细粒度目录锁机制,极大提升不同目录文件操作间的并发
- 请求路径全异步化,支持请求优先级处理
- 重点优化块汇报和重启加载流程,降低不可用时间
DanceNNv1 最终在 2019 年完成全量上线,线上效果基本达到设计目标。一个十几亿文件数规模集群,切换后大致性能对比:

- DanceNN v1 开发中遇到很多技术挑战,如为了保证上线过程对业务无感知,支持现有多种 HDFS 客户端访问,后端需要完全兼容原有的 Hadoop HDFS 协议
Distributed DanceNN
一直以来 HDFS 都是使用 Federation 方式来管理目录树,将全局 Namespace 按 path 映射到多组元数据独立的 DanceNN v1 集群,单组 DanceNN v1 集群有单机瓶颈,能处理的吞吐和容量有限,随着公司业务数据的增长,单组 DanceNN v1 集群达到性能极限,就需要在两个集群之间频繁迁移数据,为了保证数据一致性需要在迁移过程中上层业务停写,对业务影响比较大,并且当数据量大的情况下迁移比较慢,这些问题给整个系统带来非常大的运维压力,降低服务的稳定性。
Distributed 版本主要设计目标:
- 通用目录树服务,支持多协议包括 HDFS,POSIX 等
- 单一全局 Namespace
- 容量、吞吐支持水平扩展
Storage Meets Artificial Intelligence (AI)
- 高可用,故障恢复时间在秒级内
- 包括跨目录 Rename 等写操作支持事务
- 高性能,基于 C++ 实现,依赖 Brpc 等高性能框架
- Distributed DanceNN 目前已经在 HDFS 部分集群上线,正在进行存量集群的平滑迁移
- Distributed DanceNN 基于底层分布式事务 KV 存储来构建,实现容量和吞吐水平扩展,主要功能:
- HDFS 等协议层的高效实现
- 服务无状态化,支持高可用
- 服务节点的快速扩缩容
- 提供高性能低延迟的访问
- 对 Namespace 进行子树划分,充分利用子树 Cache Locality
- 集群根据负载均衡策略对子树进行调度
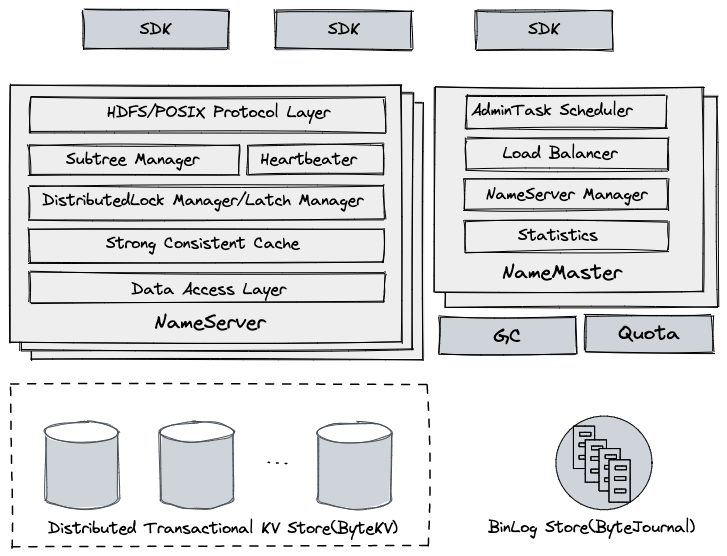
- 模块划分
- SDK:缓存集群子树、NameServer 位置等信息,解析用户请求并路由到后端服务节点上,如果服务节点响应请求不合法,可能强制 SDK 刷新相应的集群缓存。
- NameServer:作为服务节点,无状态,支持横向扩展
- HDFS/POSIX Protocol Layer:处理客户端请求,实现了 HDFS 等协议层语义,包括路径解析,权限校验,删除进入回收
- Subtree Manager:管理分配给当前节点的子树,负责用户请求检查,子树迁移处理等
- Heartbeater:进程启动后会自动注册到集群,定期向 NameMaster 更新心跳和负载信息等
- DistributedLock Manager:基于 LockTable,对跨目录 Rename 请求进行并发控制
- Latch Manager:对所有路径读写请求进行加锁处理,降低底层事务冲突,支持 Cache 的并发访问
- Strong Consistent Cache:维护了当前节点子树的 dentry 和 inode 强一致 Cache
- Data Acess Layer:对底层 KV 存储的访问接口的抽象,上层读写操作都会映射到底层 KV 存储请求
- NameMaster:作为管理节点,无状态,多台,通过选主实现,由主节点提供服务
- AdminTask Scheduler:后台管理相关任务调度执行,包括子树切分,扩容等
- Load Balancer:根据集群 NameServer 负载状态,通过自动子树迁移来完成负载均衡
- NameServer Manager:监控 NameServer 健康状态,进行相应的宕机处理
- Statistics:通过消费集群变更日志,实时收集统计信息并展示
- Distributed Transactional KV Store:数据存储层,使用自研的强一致 KV 存储系统 ByteKV
- 提供水平伸缩能力
- 支持分布式事务,提供 Snapshot 隔离级别
- 支持多机房数据灾备
- BinLog Store
- BinLog 存储,使用自研的低延迟分布式日志系统 ByteJournal,支持 Exactly Once 语义
- 从底层 KV 存储系统中实时抽取数据变更日志,主要用于 PITR 和其他组件的实时消费等
- GC(Garbage collector)
- 从 BinLog Store 实时消费变更日志,读到文件删除记录后,向文件块服务下发删除命令,及时清理用户数据
- Quota:对用户认领的目录,会周期性全量、实时增量的统计文件总数和空间总量,容量超限后限制用户写
存储格式 ,一般基于分布式存储的元数据格式有两种方案:
方案一类似 Google Colossus,以全路径作为 key,元数据作为 value 存储,优点有:
- 路径解析非常高效,直接通过用户请求的 path 从底层的 KV 存储读取对应 inode 的元数据即可
- 扫描目录可以通过前缀对 KV 存储进行扫描
但是有下列缺点:
- 跨目录 Rename 代价大,需要对目录下的所有文件和目录进行移动
- Key 占用的空间相对比较大
方案二类似 Facebook Tectonic 和开源的 HopsFS,以父目录 inode id + 目录或文件名作为 key,元数据作为 value 存储,这种优点有:
- 跨目录 Rename 非常轻量,只需要修改源和目标节点以及它们的父节点
- 扫描目录同样可以用父目录 inode id 作为前缀进行扫描
缺点有:
- 路径解析网络延迟高,需要从 Root 依次递归读取相关节点元数据直到目标节点
- 例如:MkDir /tmp/foo/bar.txt,有四次元数据网络访问:/、/tmp、/tmp/foo 和 /tmp/foo/bar.txt ,层级越小,访问热点越明显,从而导致底层存储负载严重不均衡
- 考虑到跨目录 Rename 请求在线上集群占比较高的比例,并且对于大目录 Rename 延迟不可控,DanceNN 主要采用第二种方案,方案二的两个缺点通过下面的子树分区来解决:
- 子树分区:DanceNN 通过将全局 Namespace 进行子树分区,子树被指定一个 NameServer 实例维护子树缓存
- 子树缓存
- 维护这个子树下所有目录和文件元数据的强一致缓存
- 缓存项有一定淘汰策略包括 LRU,TTL 等
- 所有请求路径在这个子树下的可以直接访问本地缓存,未命中需要从底层 KV 存储进行加载并填充缓存
- 通过对缓存项添加版本的方法来指定某个目录下所有元数据的缓存过期,有利于子树快速迁移清理
利用子树本地缓存,路径解析和读请求基本能够命中缓存,降低整体延迟,也避免了靠近根节点访问的热点问题
- 路径冻结
- 在子树迁移、跨子树 Rename 等操作过程中,为了避免请求读取过期的子树缓存,需要将相关的路径进行冻结,冻结期间该路径下的所有操作会被阻塞,由 SDK 负责重试,整个流程在亚秒级内完成
- 路径冻结后会将该目录下的所有缓存项设置为过期
- 冻结的路径信息会被持久化到底层的 KV 存储,重启后会重新加载刷新
- 子树管理:主要由 NameMaster 负责:
- 支持通过管理员命令进行手动子树分裂和子树迁移
- 定期监控集群节点的负载状态,动态调整子树在集群分布
- 定期统计子树的访问吞吐,提供子树分裂建议,未来支持启发式算法选择子树完成分裂
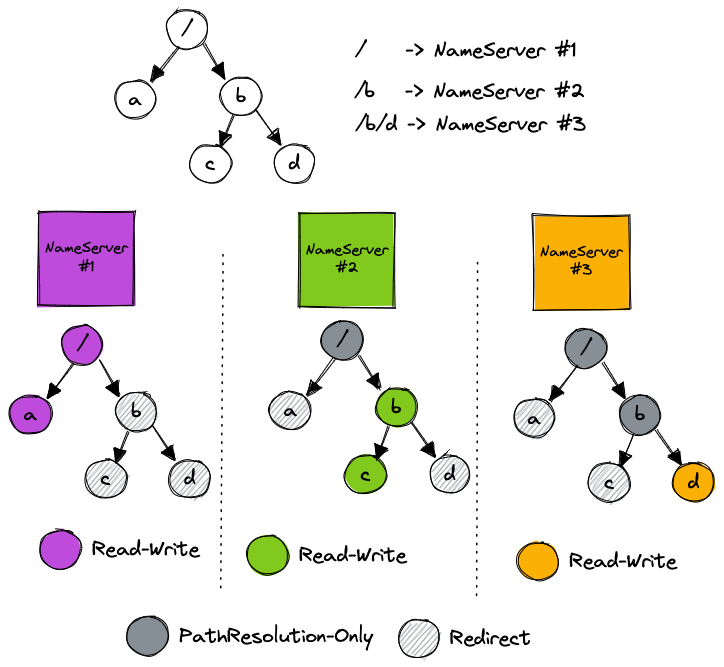
- 举个例子,如下图:目录 / 调度到 NameServer #1,目录 /b 调度到 NameServer #2,目录 /b/d 调度到 NameServer #3
- MkDir /a 请求发送到 NameServer #1,发送到其他 NameServer 会校验失败,返回重定向错误,让 SDK 刷新缓存重试
- Stat /b/d 请求将会发送到 NameServer #3,直接读取本地缓存即可
- ChMod /b 请求将会发送到 NameServer #2,更新 b 目录的权限信息并持久化,对 NameServer #2 和 NameServer #3 进行 Cache 刷新,最后回复客户端
- 其他
- 并发控制
- 分布式锁管理
- Latch 管理
- 请求幂等
关于社区
Hadoop 社区
2022发展趋势:https://www.dbta.com/Categories/Hadoop-532.aspx
2022 年的 Hadoop 趋势是什么?
主要供应商:
- Amazon Web Services Elastic MapReduce;
- Cloudera CDH Hadoop 发行版;
- MapR Hadoop 发行版;
- Microsoft Azure 的 HDInsight;
- Dell-Cloudera Apache Hadoop 解决方案;
- IBM 开放平台。
第一:Hadoop 即服务 (HAAS)
云正日益成为存储和处理大数据的理想解决方案。事实上,无论是小型、中型还是大型公司,这种选择所提供的实际和经济优势都会引起更大的兴趣。通过 Hadoop 即服务,在云上建立 Hadoop 生态系统已经有几年的可能了。该系统的采用与 2022 年更加相关。因此,Hadoop 即服务是一种将生态系统作为服务提供的方式。在该领域工作的供应商对与大数据相关的工具(例如 Spark、HBase 或 Storm)以实例形式与 Hadoop 发行版相结合收费。该系统已经准备好使用,因为供应商已经为客户处理好了一切。集群已经预先建立、可扩展和容错。客户只需插入他希望处理的数据。可用资源可根据项目需要轻松扩展。实际上,该解决方案在成本方面非常有趣,这就是为什么越来越多的供应商正在转向该系统的营销。
第二:YARN(Yet another Resource Negotiator) 从 Hadoop 2.x 引入,YARN 是生态系统最重要的演变之一。它是 MapReduce 的升级版,在早期为它赢得了 MapReduce 2 的名称。其根本原则是将资源端的管理与大数据的处理分离。使用 YARN,您可以根据充足资源的可用性安排某些任务,还可以跟踪执行的操作,这在旧版本中是很困难的。YARN 允许更高效地同时使用 Hive、HBase 或 Spark 等多个应用程序,从而优化数据处理。到目前为止,仍在对该工具进行修改以使其更有效。几年来,采用 YARN 一直是必不可少的,并且在 2022 年仍然如此
第三:最新版本的 Hadoop 及其演变(https://hadoop.apache.org/docs/r3.3.4/index.html) 目前,我们处于 Hadoop 的 3.x 版本,其最新版本是 2022年 8 月发布的 3.3.4。此版本增加带来了一些重大改进,例如:
- protobuf,java 版升级;
- HDFS 擦除编码,除其他外,通过不再使用 Hadoop 的传统复制方法来减少资源消耗,同时保持高可用性;
- MapReduce 在任务级别的改进;
- 在 HDFS 缓存指令中支持非易失性存储类内存 (SCM)
- 一些 YARN 增强功能,包括支持的资源和时间线服务等等
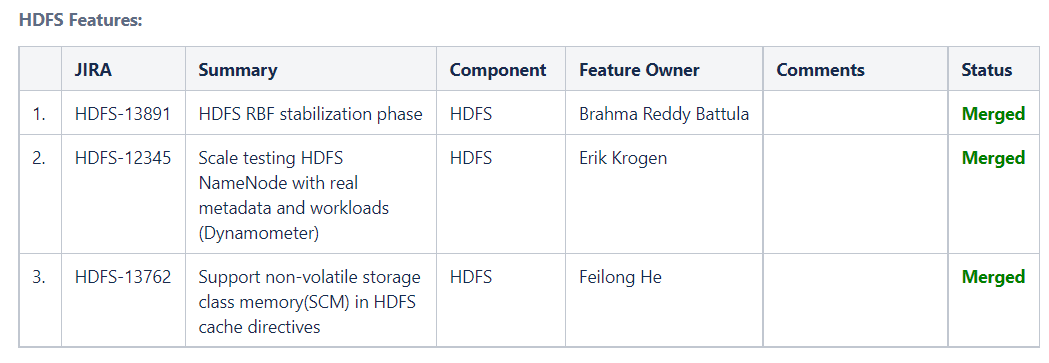
路线图:https://cwiki.apache.org/confluence/display/HADOOP/Roadmap
- 3.3.x
- HDFS RBF稳定阶段
- 使用真实的元数据和工作负载来测试HDFS NameNode (Dynamometer)
- 在HDFS缓存指令中支持非易失存储类内存(SCM)
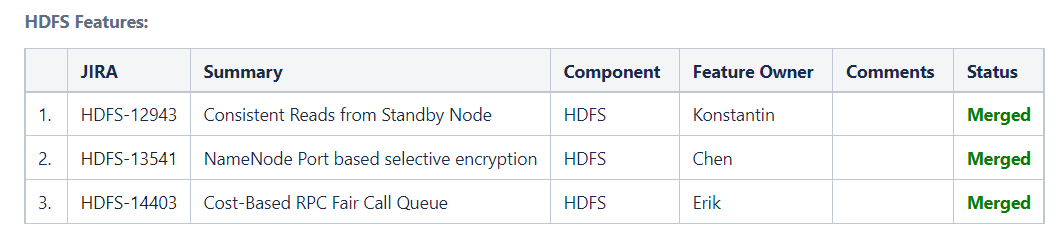
2.10
- 从备节点一致读取
- NameNode基于端口的选择性加密
- 基于成本的RPC公平呼叫队列
3.2.0
- HDFS Storage Policy Satisfier
- Router-based HDFS federation

3.1.0
- HDFS tiered storage

- 3.3.x
存储在线会议,Hadoop Storage Online Meetup
- 2022/06/23 DanceNN: Over 100 Billion metadata management System for FileSystem at ByteDance
- DanceNN 是一个目录树元数据管理系统,起源于字节跳动开发的 HDFS NameNode。 希望解决所有分布式存储系统(包括但不限于HDFS、NAS等)的目录树需求,简化目录树操作的复杂度,解决可扩展性、性能、全局统一命名空间,创建通用分布式 目录树服务。
- 01/06/2022 The practice of HDFS at BIGO
- HDFS作为大数据的底层存储服务,在BIGO的发展中发挥着非常重要的作用。 随着业务的发展和数据的爆炸式增长,单个HDFS集群的瓶颈越来越明显。 我们使用路由器将多个 HDFS 集群集成到一个联合命名空间中,以增强集群扩展能力。 修改Router支持Alluxio和自定义策略,使HDFS EC实现热、温、冷数据的分层存储。 此外,对HDFS集群中的慢节点和慢磁盘进行处理,提高HDFS的读写性能。 本节介绍 BIGO 在路由器和慢节点和慢磁盘方面的经验。
- 12/09/2021 HDFS at Shopee
- 09/09/2021 Uber’s story on running Apache Hadoop deployment in Docker
- …
Ozone:Apache Hadoop 一款新的对象存储系统
- https://ozone.apache.org/
- HDFS问题:https://www.infoq.cn/article/pygmr1elhhoxygf6resd
- NN SCalability,GC disaster,Block report storm,Throughput,NN startup slow
- 元数据的扩展性:元数据都在内存中,造成的拓展性 受物理内存限制的问题 和 GC 灾难问题,小文件不友好
- HDFS 采用的 Master/Slave 架构,并且 master 节点也就是 NameNode 节点,统一管理文件系统命名空间中的元数据,对外提供文件系统元数据服务、数据块管理服务、节点管理、冗余存储管理、心跳管理等众多服务于一身的一个高度中心化的 Master 服务。此外 NameNode 的内部还有全局的 FSlock 以及 DirLock,这些都是全局锁
- NameNode 的 HA ( 高可用性 High Availability ) 也显得特别复杂,至少要引入三个 zookeeper 节点,三个 JournalNode 节点,两个 ZKFC 节点,部署维护都显得比较复杂。文件系统的 inode 信息和 block 信息以及 block 的 location 信息全部在 NameNode 的内存中维护,这使得 NameNode 对内存的要求非常高,需要定制大内存的机器才能承载更大的元数据量(京东的 NameNode 内存是 512GB,阿里的 NameNode 的机器是 1TB 的内存)
- NameNode 堆分配巨大,因此对 GC 的要求是特别高
- 小文件:元数据更多,在同样的数据存储容量的情况下,NameNode 中产生更多的内存对象
- 全局锁和Block report storm,导致的吞吐差和 NameNode 启动慢的问题
- Block report storm(块汇报风暴):HDFS块大小默认128M,启动几百PB数据量的集群时,NameNode需要接受所有块汇报才可以退出安全模式,因此启动时间会达数小时。当集群全量块汇报(FullBlockReport)、下线节点(Decommision datanode)、balance集群存储,也会对集群元数据服务的性能造成影响,这些根本原因都是DataNode需要把所有块汇报给NameNode。
- 全局锁:NameNode 有一把FSNamesystem全局锁,每个元数据请求时都会加这把锁。虽然是读写分开的,且有部分流程对该锁的持有范围进行了优化,但依然大问题。同时FSNamesystem内部的FSDirectory(Inode树)还存在一把单独的锁,用来保护整棵树以及BlockMap的访问和修改
Ozone:分布式key-value对象存储系统Ozone,兼容文件访问接口。利用Hadoop Compatible FileSystem接口, Ozone可以用于大数据生态;利用CSI,S3协议, Ozone可以作为云存储服务云上用户
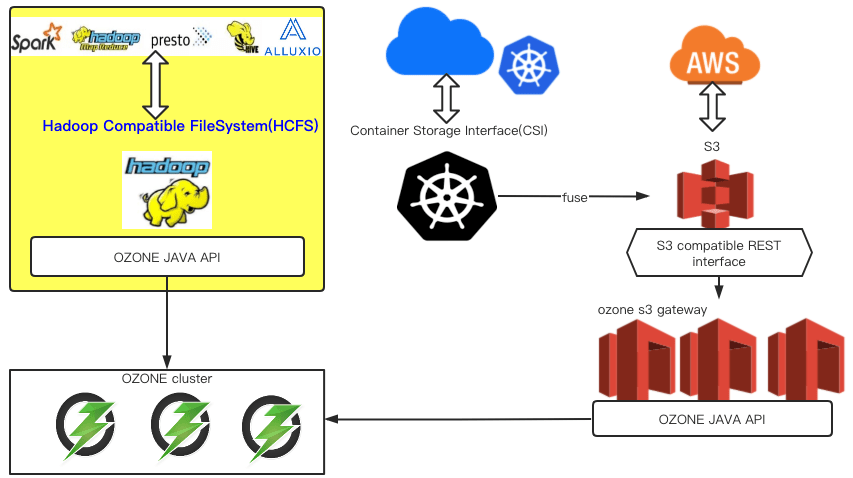
Ozone架构分为三个部分,OzoneManager、StorageContainerManager、Datanode。OzoneManager相当于HDFS的Namespace元数据;StorageContainerManager相当于HDFS的Block Manager,但管理的是Container而不是HDFS的Block。而Datanode使用Raft实现的Ratis保证写一致性
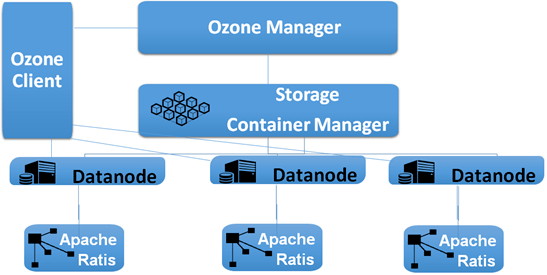
架构
- OM(Ozone Manager):通过RocksDB的K-V方式管理Namespace,Raft协议保持高可用,Shardig实现水平扩展
- SCM(Storage Container Manager):用于Ozone集群管理,负责分配Block,跟踪SC复制状态
- DataNode:负责向SCM汇报SC状态
- SC(Storage Container):Ozone的实际存储单元
- Recon Server:用于监控Ozone集群
- Ozone做了架构优化,上层实现职能分离,OM负责管理Namespace,SCM负责管理Storage Containers
核心技术
- Ozone把Namespace元数据服务和Block Manager拆分为两个服务。OzoneManager负责元数据服务;StorageContainerManager负责数据块管理、节点管理、副本冗余管理。两个服务可以部署在两台机器,各自利用机器资源。Ozone的元数据不像NameNode存储在内存中,不管是OzoneManager的元数据,还是StorageContainerManager中的Container信息都维护在RocksDB中,极大降低对内存的依赖,理论上元数据可以无限扩展。
- StorageContainerManager无须管理默认128MB的Block,只需管理默认5GB的Container。极大地减少了StorageContainerManager管理的数据量,从而提升StorageContainerManager的服务性能。因为StorageContainerManager是以Container作为汇报单位,汇报数量比HDFS大大减少。无论是全量块汇报,增删副本,balancer集群存储,都不会给StorageContainerManager性能造成很大影响。
- OzoneManager内部的锁是Bucket级别,可以达到Bucket级的写并发。Ozone是对象存储,对象语义的操作,不存在目录和树的关系,因此不需要维护文件系统树,可以达到高吞吐量。
当前问题
- Ozone 不支持 Append、truncate 的操作
- Ozone 写 key 的方式是不写完不可见,这是因为 Ozone 在写 key 的过程中不会向 OM 去提交 block,而是把所有的数据全写完之后一次性的向 OM 去提交所有 block 信息,因此在写作的过程中 key 是不可见的
- Ozone 的 RPC 链路比 HDFS 的 RPC 链路长,对于纯元数据操作性能低
- 另外一个就是 Ozone 目前还没有像文件夹的这样的一个 metadata,因此他就没办法去获得文件夹的 owner、modificationTime 等信息。
- Ozone 底层写数据是基于 ratis,而目前 ratis 写也只支持一副本和三副本,腾讯正在向开源社区去贡献都基于的 Strorage cluster 框架的任意副本的支持。
- SCM HA 也是一个很大的问题,现在还没有,不过腾讯现在正在积极地主导 feature,正在向我们的开源社区去 push 相关的改动,预计在 Ozone 的下一个大版本的发布会包含这个功能。
- Ozone 还缺少一个 container balancer 这样的功能,用它来均衡存储,使集群的存储能分布均匀
- Ozone 目前还缺少 DataNode 磁盘预留功能
- Ozone 的写性能,正在通过 RATIS Streaming feature 进行优化。目前我们内部测试 有了这个 Feature 性能提升巨大。
HofsFS
- hadoop官网找不到任何消息
- 公司:https://www.logicalclocks.com/products/hopsfs
- 自己社区:hopshadoop
Apache Spark中国技术社区
- Ozone 是很不错,但它救不了 Hadoop,就这个项目的前后十年来说,Hadoop 社区有远比它更重要的挑战需要去解决
- 。。。
相关论文 — 其他
论文8 (Google) From GFS to Colossus : Cluster-Level Storage
- 2017,第二代GFS,旨在提升存储效率
- 元数据伸缩允许对资源进行划分
- 组合不同大小和不同类型工作负载的磁盘的能力非常强大
论文9 XRP: In-Kernel Storage Functions with eBPF
背景
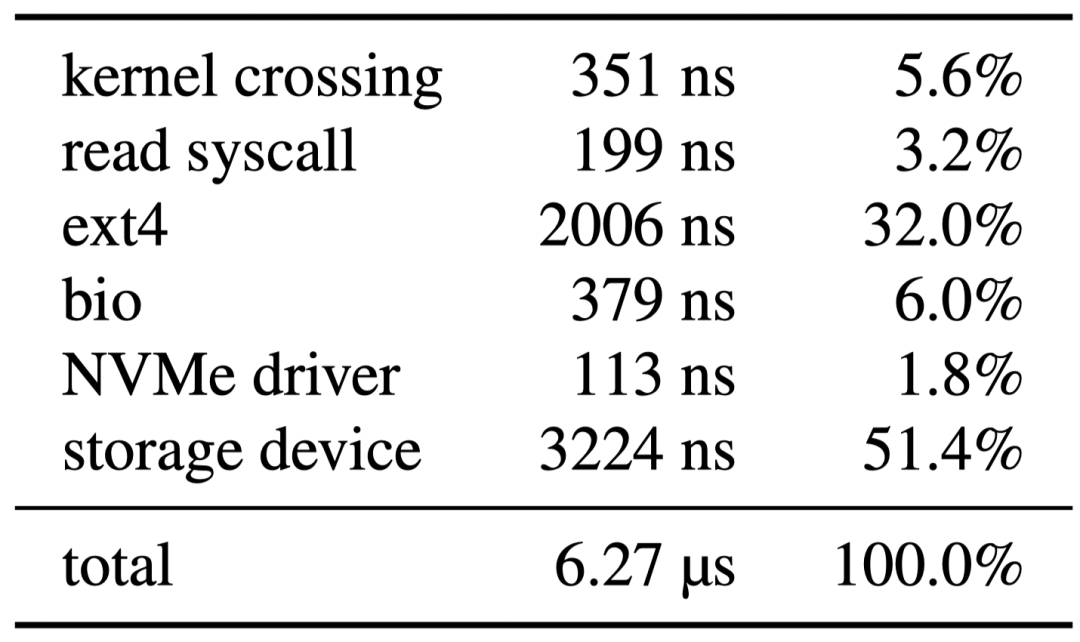
随着微秒级的NVMe存储设备的出现,Linux存储软件栈在总访问开销中的占比也随之明显上升。如下图所示,在最新的高速存储设备上,来自软件栈的开销几乎让访问开销翻倍了
现有的方案都太激进了,它们都需要对应用或是硬件有着侵入性的修改
- 例如有些kernel bypass的方案如SPDK允许应用去直接访问底下的设备,但是也会强迫应用实现自己的文件系统,同时放弃隔离性和安全性,并且还需要polling导致了CPU资源的浪费(尤其是IO利用率低的时候polling的坏处尤为明显)。测试数据展示出使用SPDK的应用在可调度线程数量大于CPU数量时会导致更差的尾时延,甚至吞吐量都会严重下降。因此,本文希望能够探寻一种既易于部署,又无需对应用有过多侵入修改,能够充分利用现有kernel和文件系统功能的高速存储访问方案。
观察:当前部分应用的一些存储IO操作中,需要用户态去处理大量的中间结果。如果每个中间结果都需要往返于内核态和用户态才能处理的话,会引入大量的传递开销(如下图所示,开销主要来自于内核上下文切换和文件系统,此外bio层的开销相比于设备驱动也更为明显)
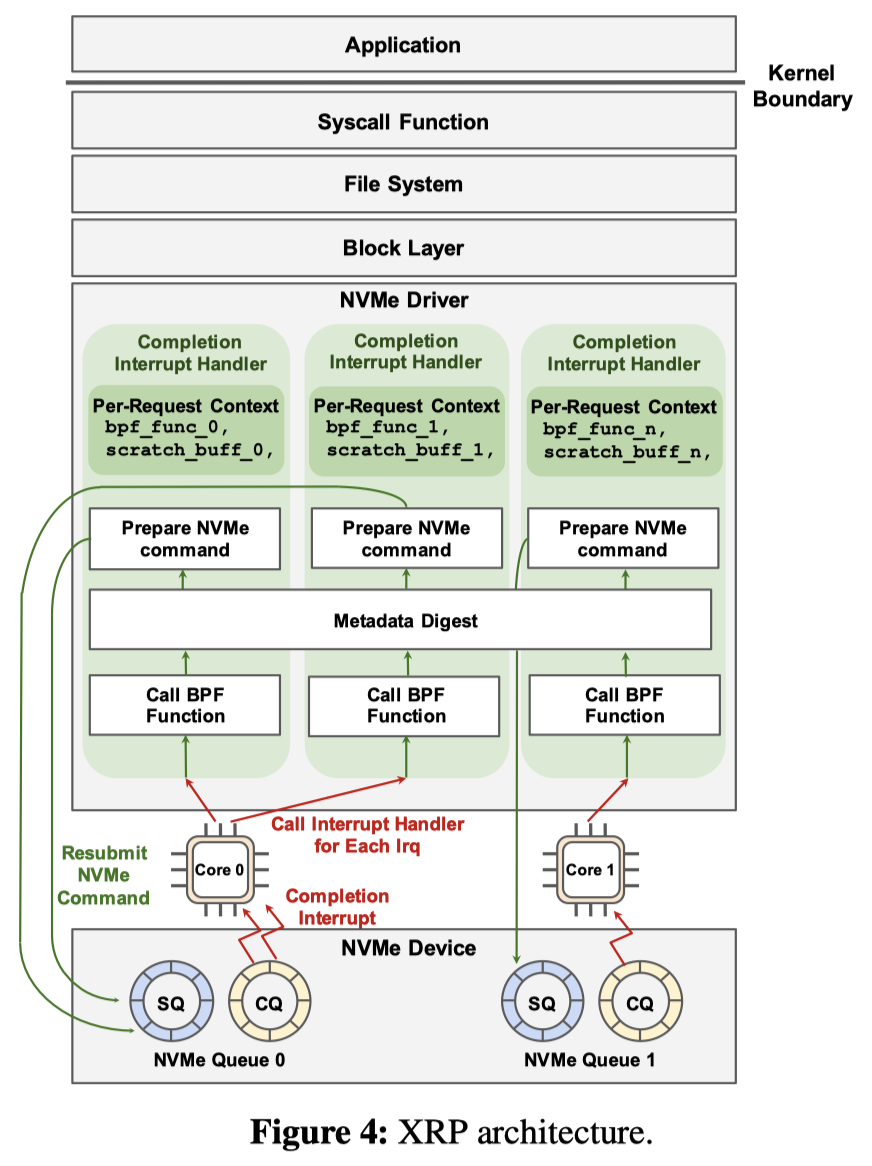
- 一个典型的例子是当应用进行基于b-tree的索引,应用的最终目的其实是想找到最末端的叶子节点,但是通常的b-tree搜索过程中会将搜索路径上的每一个节点读取到用户态。该过程中就会反复多次触发上图中的各项开销。针对这个场景,本文提出XRP,其核心解决思路(如下图)是将多次应用逻辑在软件栈底层batch起来,消除冗余的上层开销。具体来说,本文利用eBPF技术,将部分原本在用户态执行的应用逻辑放入内核态的NVMe驱动层,从而使该过程中的中间结果不用再返回用户态,而是在内核态中就可以继续下一步处理
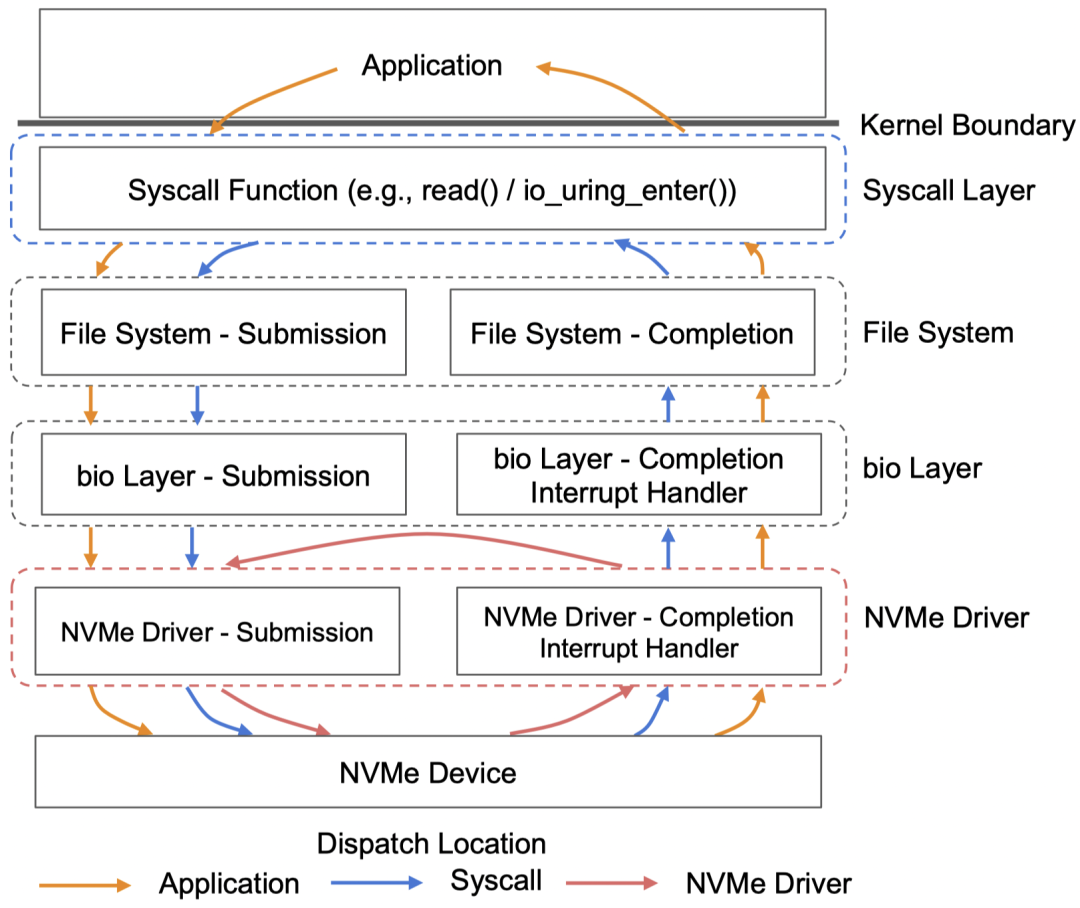
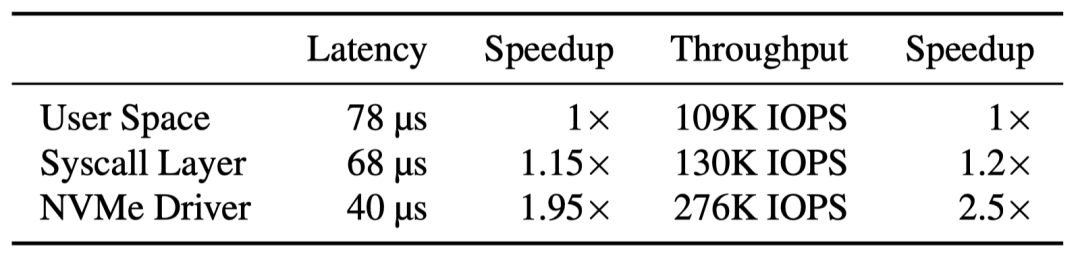
- 之所以选择hook在NVMe驱动层则是因为在内核态的位置也应当尽量能避免经过上图中那些开销较大的步骤(如ext4和bio层)。如下图所示,作者之前的研究中有对深度为10的b-tree进行测试,如果不绕过内核中的syscall和文件系统层,那在延时和吞吐量上的提升并不明显。而在NVMe驱动层则能显著提升这两项性能。
- 尽管这个方法看起来很直观,但是依然存在两个主要挑战:
- NVMe驱动层目前无法访问文件系统的元数据。例如在索引穿越场景下,NVMe中的XRP在处理一个read操作时会在从当前block中通过offset去提取下一个block。但是它无法获知这个offset所关联的物理block,因为它不知道文件系统的相关元数据
- XRP系统难以应对由文件系统处理的并发读写操作。如果文件发生改写,NVMe driver层无法观察到缓存在kernel page cache中的文件更改,这可能会导致XRP读取到错误的数据。而用锁来保护文件结构带来的开销则会比较大。
- 针对上述挑战
- 观察到大部分on-disk的数据结构都非常稳定,常用的数据库大部分采用了index文件创建后不再更改或更改频率较低的索引文件结构,且大部分数据库会选择自行管理page cache而不是使用fs提供的page cache
- 另一方面,大部分索引都集中在少数几个大文件中,且每个索引都不会跨多个文件
- 因此,本文的解决方式是限定XRP的使用场景为索引文件结构比较稳定和用户管理page cache的场景,同时缓存和维护单个文件所需的logical-to-physical-mapping信息(metadata digest)以供NVMe driver层访问
- 架构如下图所示,当NVMe存储设备发送中断后,中断handler最终会调用hook的BPF函数进行处理。该函数利用metadata digest所提供的接口安全地访问少量ext4文件系统元数据从而绕过NVMe驱动以上所有软件层的介入直到本次resubmission逻辑全部处理完成后返回用户态
本文在Linux上通过eBPF实现了支持ext4文件系统的XRP原型。为了和Baseline(linux的同步与异步syscall以及kernel bypass方案SPDK)进行对比,构建了一个简单的KV存储程序——BPF-KV。在尾延时方面,99th下XRP显著好于linux的同步和异步syscall,而在99.9th下,尽管大部分时候依然是SPDK好于XRP,但是当线程数大于执行的物理核心数(6个)时,SPDK的尾时延会显著上升,而XRP则依然稳定。
最新论文
ATC 22
存储3,机器学习3,分离系统2,网络2,部署系统2,容器,bug,安全,编译,NIC
Storage 1
ZNSwap: un-Block your Swap Shai Bergman, Technion; Niklas Cassel and Matias Bjørling, Western Digital; Mark Silberstein, Technion
Building a High-performance Fine-grained Deduplication Framework for Backup Storage with High Deduplication Ratio Xiangyu Zou and Wen Xia, Harbin Institute of Technology, Shenzhen; Philip Shilane, Dell Technologies; Haijun Zhang and Xuan Wang, Harbin Institute of Technology, Shenzhen
Secure and Lightweight Deduplicated Storage via Shielded Deduplication-Before-Encryption Zuoru Yang, The Chinese University of Hong Kong; Jingwei Li, University of Electronic Science and Technology of China; Patrick P. C. Lee, The Chinese University of Hong Kong
Containers
- RunD: A Lightweight Secure Container Runtime for High-density Deployment and High-concurrency Startup in Serverless Computing Zijun Li, Jiagan Cheng, and Quan Chen, Shanghai Jiao Tong University; Eryu Guan, Zizheng Bian, Yi Tao, Bin Zha, Qiang Wang, and Weidong Han, Alibaba Group; Minyi Guo, Shanghai Jiao Tong University
- Help Rather Than Recycle: Alleviating Cold Startup in Serverless Computing Through Inter-Function Container Sharing Zijun Li, Linsong Guo, Quan Chen, Jiagan Cheng, and Chuhao Xu, Shanghai Jiao Tong University; Deze Zeng, China University of Geosciences; Zhuo Song, Tao Ma, and Yong Yang, Alibaba Cloud; Chao Li and Minyi Guo, Shanghai Jiao Tong University
- RRC: Responsive Replicated Containers Diyu Zhou, UCLA and EPFL; Yuval Tamir, UCLA
Distributed Systems 1
- uKharon: A Membership Service for Microsecond Applications Rachid Guerraoui and Antoine Murat, EPFL; Javier Picorel, Huawei Technologies; Athanasios Xygkis, EPFL; Huabing Yan and Pengfei Zuo, Huawei Technologies
- KRCORE: A Microsecond-scale RDMA Control Plane for Elastic Computing Xingda Wei, Shanghai Jiao Tong University, Shanghai AI Laboratory; Fangming Lu, Shanghai Jiao Tong University; Rong Chen, Shanghai Jiao Tong University, Shanghai AI Laboratory; Haibo Chen, Shanghai Jiao Tong University
- Zero-Change Object Transmission for Distributed Big Data Analytics Mingyu Wu, Shuaiwei Wang, Haibo Chen, and Binyu Zang, Shanghai Jiao Tong University
- Sift: Using Refinement-guided Automation to Verify Complex Distributed Systems Haojun Ma, Hammad Ahmad, Aman Goel, Eli Goldweber, Jean-Baptiste Jeannin, Manos Kapritsos, and Baris Kasikci, University of Michigan
Machine Learning 1
- Faith: An Efficient Framework for Transformer Verification on GPUs Boyuan Feng, Tianqi Tang, Yuke Wang, Zhaodong Chen, Zheng Wang, Shu Yang, Yuan Xie, Yufei Ding, University of California, Santa Barbara
- DVABatch: Diversity-aware Multi-Entry Multi-Exit Batching for Efficient Processing of DNN Services on GPUs Weihao Cui, Han Zhao, Quan Chen, Hao Wei, and Zirui Li, Shanghai Jiao Tong University; Deze Zeng, China University of Geosciences; Chao Li and Minyi Guo, Shanghai Jiao Tong University
- Serving Heterogeneous Machine Learning Models on Multi-GPU Servers with Spatio-Temporal Sharing Seungbeom Choi, Sunho Lee, Yeonjae Kim, Jongse Park, Youngjin Kwon, and Jaehyuk Huh, KAIST
- PilotFish: Harvesting Free Cycles of Cloud Gaming with Deep Learning Training Wei Zhang and Binghao Chen, Shanghai Jiao Tong University; Zhenhua Han, Microsoft Research; Quan Chen, Shanghai Jiao Tong University; Peng Cheng, Fan Yang, Ran Shu, and Yuqing Yang, Microsoft Research; Minyi Guo, Shanghai Jiao Tong University
Operating Systems 1
- Privbox: Faster System Calls Through Sandboxed Privileged Execution Dmitry Kuznetsov and Adam Morrison, Tel Aviv University
- BBQ: A Block-based Bounded Queue for Exchanging Data and Profiling Jiawei Wang, Huawei Dresden Research Center, Huawei OS Kernel Lab, Technische Universität Dresden; Diogo Behrens, Ming Fu, Lilith Oberhauser, Jonas Oberhauser, and Jitang Lei, Huawei Dresden Research Center, Huawei OS Kernel Lab; Geng Chen, Huawei OS Kernel Lab; Hermann Härtig, Technische Universität Dresden; Haibo Chen, Huawei OS Kernel Lab, Shanghai Jiao Tong University
Disaggregated Systems
- Sibylla: To Retry or Not To Retry on Deep Learning Job Failure Taeyoon Kim, Suyeon Jeong, Jongseop Lee, Soobee Lee, and Myeongjae Jeon, UNIST
- Speculative Recovery: Cheap, Highly Available Fault Tolerance with Disaggregated Storage Nanqinqin Li, Anja Kalaba, Michael J. Freedman, Wyatt Lloyd, and Amit Levy, Princeton University
- Direct Access, High-Performance Memory Disaggregation with DirectCXL Donghyun Gouk, Sangwon Lee, Miryeong Kwon, and Myoungsoo Jung, KAIST
Networking 1
- Not that Simple: Email Delivery in the 21st Century Florian Holzbauer, SBA Research; Johanna Ullrich, University of Vienna; Martina Lindorfer, TU Wien; Tobias Fiebig, Max-Planck-Institut für Informatik
- AddrMiner: A Comprehensive Global Active IPv6 Address Discovery System Guanglei Song, Jiahai Yang, Lin He, Zhiliang Wang, Guo Li, Chenxin Duan, and Yaozhong Liu, Tsinghua University; Zhongxiang Sun, Beijing Jiaotong University
- Co-opting Linux Processes for High-Performance Network Simulation Rob Jansen, U.S. Naval Research Laboratory; Jim Newsome, Tor Project; Ryan Wails, Georgetown University, U.S. Naval Research Laboratory
- Awarded Best Paper!
Finding Bugs
- KSG: Augmenting Kernel Fuzzing with System Call Specification Generation Hao Sun, Yuheng Shen, Jianzhong Liu, Yiru Xu, and Yu Jiang, Tsinghua University
- DLOS: Effective Static Detection of Deadlocks in OS Kernels Jia-Ju Bai, Tuo Li, and Shi-Min Hu, Tsinghua University
- Modulo: Finding Convergence Failure Bugs in Distributed Systems with Divergence Resync Models Beom Heyn Kim, Samsung Research, University of Toronto; Taesoo Kim, Samsung Research, Georgia Institute of Technology; David Lie, University of Toronto
Security
- SoftTRR: Protect Page Tables against Rowhammer Attacks using Software-only Target Row Refresh Zhi Zhang, CSIRO’s Data61, Australia; Yueqiang Cheng, NIO Security Research; Minghua Wang, Baidu Security; Wei He and Wenhao Wang, State Key Laboratory of Information Security, Institute of Information Engineering, CAS and University of Chinese Academy of Sciences; Surya Nepal, CSIRO’s Data61, Australia; Yansong Gao, Nanjing University of Science and Technology, China; Kang Li, Baidu Security; Zhe Wang and Chenggang Wu, State Key Laboratory of Computer Architecture, Institute of Computing Technology, CAS and University of Chinese Academy of Sciences
- Hardening Hypervisors with Ombro Ethan Johnson, Colin Pronovost, and John Criswell, University of Rochester
- HyperEnclave: An Open and Cross-platform Trusted Execution Environment Yuekai Jia, Tsinghua University; Shuang Liu, Ant Group; Wenhao Wang, Institute of Information Engineering, CAS; Yu Chen, Tsinghua University; Zhengde Zhai, Shoumeng Yan, and Zhengyu He, Ant Group
- PRIDWEN: Universally Hardening SGX Programs via Load-Time Synthesis Fan Sang, Georgia Institute of Technology; Ming-Wei Shih, Microsoft; Sangho Lee, Microsoft Research; Xiaokuan Zhang, Georgia Institute of Technology; Michael Steiner, Intel; Mona Vij, Intel Labs; Taesoo Kim, Georgia Institute of Technology
Machine Learning 2
- Tetris: Memory-efficient Serverless Inference through Tensor Sharing Jie Li, Laiping Zhao, and Yanan Yang, Tianjin University; Kunlin Zhan, 58.com; Keqiu Li, Tianjin University
- PetS: A Unified Framework for Parameter-Efficient Transformers Serving Zhe Zhou, Peking University; Xuechao Wei, Peking University, Alibaba Group; Jiejing Zhang, Alibaba Group; Guangyu Sun, Peking University
- Campo: Cost-Aware Performance Optimization for Mixed-Precision Neural Network Training Xin He, CSEE, Hunan University & Xidian University; Jianhua Sun and Hao Chen, CSEE, Hunan University; Dong Li, University of California, Merced
- Primo: Practical Learning-Augmented Systems with Interpretable Models Qinghao Hu, Nanyang Technological University; Harsha Nori, Microsoft; Peng Sun, SenseTime; Yonggang Wen and Tianwei Zhang, Nanyang Technological University
Distributed Systems 2
- Meces: Latency-efficient Rescaling via Prioritized State Migration for Stateful Distributed Stream Processing Systems Rong Gu, Han Yin, Weichang Zhong, Chunfeng Yuan, and Yihua Huang, State Key Laboratory for Novel Software Technology, Nanjing University
- DepFast: Orchestrating Code of Quorum Systems Xuhao Luo, University of Illinois at Urbana-Champaign; Weihai Shen and Shuai Mu, Stony Brook University; Tianyin Xu, University of Illinois at Urbana-Champaign
- High Throughput Replication with Integrated Membership Management Pedro Fouto, Nuno Preguiça, and João Leitão, NOVA LINCS & NOVA University Lisbon
Operating Systems 2
- CBMM: Financial Advice for Kernel Memory Managers Mark Mansi, Bijan Tabatabai, and Michael M. Swift, University of Wisconsin - Madison
- EPK: Scalable and Efficient Memory Protection Keys Jinyu Gu, Hao Li, Wentai Li, Yubin Xia, and Haibo Chen, Shanghai Jiao Tong University
- Memory Harvesting in Multi-GPU Systems with Hierarchical Unified Virtual Memory Sangjin Choi and Taeksoo Kim, KAIST; Jinwoo Jeong, Ajou University; Rachata Ausavarungnirun, King Mongkut’s University of Technology North Bangkok; Myeongjae Jeon, UNIST; Youngjin Kwon, KAIST; Jeongseob Ahn, Ajou University
Deployed Systems 1
- Zero Overhead Monitoring for Cloud-native Infrastructure using RDMA Zhe Wang, Shanghai Jiao Tong University; Teng Ma, Alibaba Group; Linghe Kong, Shanghai Jiao Tong University; Zhenzao Wen, Jingxuan Li, Zhuo Song, Yang Lu, Yong Yang, and Tao Ma, Alibaba Group; Guihai Chen, Shanghai Jiao Tong University; Wei Cao, Alibaba Group
- CRISP: Critical Path Analysis of Large-Scale Microservice Architectures Zhizhou Zhang, UC Santa Barbara; Murali Krishna Ramanathan, Prithvi Raj, and Abhishek Parwal, Uber Technologies Inc.; Timothy Sherwood, UC Santa Barbara; Milind Chabbi, Uber Technologies Inc.
- Whale: Efficient Giant Model Training over Heterogeneous GPUs Xianyan Jia, Le Jiang, Ang Wang, and Wencong Xiao, Alibaba Group; Ziji Shi, National University of Singapore & Alibaba Group; Jie Zhang, Xinyuan Li, Langshi Chen, Yong Li, Zhen Zheng, Xiaoyong Liu, and Wei Lin, Alibaba Group
Machine Learning 3
- Cachew: Machine Learning Input Data Processing as a Service Dan Graur, Damien Aymon, Dan Kluser, and Tanguy Albrici, ETH Zurich; Chandramohan A. Thekkath, Google; Ana Klimovic, ETH Zurich
- CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics Jinwoo Hwang, Minsu Kim, Daeun Kim, Seungho Nam, Yoonsung Kim, and Dohee Kim, KAIST; Hardik Sharma, Google; Jongse Park, KAIST
- SOTER: Guarding Black-box Inference for General Neural Networks at the Edge Tianxiang Shen, Ji Qi, Jianyu Jiang, Xian Wang, Siyuan Wen, Xusheng Chen, and Shixiong Zhao, The University of Hong Kong; Sen Wang and Li Chen, Huawei Technologies; Xiapu Luo, The Hong Kong Polytechnic University; Fengwei Zhang, Southern University of Science and Technology (SUSTech); Heming Cui, The University of Hong Kong
Storage 2
- IPLFS: Log-Structured File System without Garbage Collection Juwon Kim, Minsu Jang, Muhammad Danish Tehseen, Joontaek Oh, and YouJip Won, KAIST
- Vigil-KV: Hardware-Software Co-Design to Integrate Strong Latency Determinism into Log-Structured Merge Key-Value Stores Miryeong Kwon, Seungjun Lee, and Hyunkyu Choi, KAIST; Jooyoung Hwang, Samsung Electronics Co., Ltd.; Myoungsoo Jung, KAIST
- Pacman: An Efficient Compaction Approach for Log-Structured Key-Value Store on Persistent Memory Jing Wang, Youyou Lu, Qing Wang, and Minhui Xie, Tsinghua University; Keji Huang, Huawei Technologies Co., Ltd; Jiwu Shu, Tsinghua University
Networking 2
- Towards Latency Awareness for Content Delivery Network Caching Gang Yan and Jian Li, SUNY-Binghamton University
- Hashing Design in Modern Networks: Challenges and Mitigation Techniques Yunhong Xu, Texas A&M University; Keqiang He and Rui Wang, Google; Minlan Yu, Harvard University; Nick Duffield, Texas A&M University; Hassan Wassel, Shidong Zhang, Leon Poutievski, Junlan Zhou, and Amin Vahdat, Google
- Firebolt: Finding Bugs in Programmable Data Plane Generators Jiamin Cao, Tsinghua University; Yu Zhou and Chen Sun, Alibaba Group; Lin He, Zhaowei Xi, and Ying Liu, Tsinghua University
Compilers and PL
- Investigating Managed Language Runtime Performance: Why JavaScript and Python are 8x and 29x slower than C++, yet Java and Go can be Faster? David Lion, University of Toronto and YScope Inc.; Adrian Chiu and Michael Stumm, University of Toronto; Ding Yuan, University of Toronto and YScope Inc.
- Automatic Recovery of Fine-grained Compiler Artifacts at the Binary Level Yufei Du, University of North Carolina at Chapel Hill; Ryan Court and Kevin Snow, Zeropoint Dynamics; Fabian Monrose, University of North Carolina at Chapel Hill
- JITServer: Disaggregated Caching JIT Compiler for the JVM in the Cloud Alexey Khrabrov, University of Toronto; Marius Pirvu and Vijay Sundaresan, IBM; Eyal de Lara, University of Toronto
- Riker: Always-Correct and Fast Incremental Builds from Simple Specifications Charlie Curtsinger, Grinnell College; Daniel W. Barowy, Williams College
- Awarded Best Paper!
Storage 3
- FlatFS: Flatten Hierarchical File System Namespace on Non-volatile Memories Miao Cai, Key Laboratory of Water Big Data Technology of Ministry of Water Resources, Hohai University; School of Computer and Information, Hohai University; State Key Laboratory for Novel Software Technology, Nanjing University; Junru Shen, School of Computer and Information, Hohai University; Bin Tang, Key Laboratory of Water Big Data Technology of Ministry of Water Resources, Hohai University; Hao Huang, State Key Laboratory for Novel Software Technology, Nanjing University; Baoliu Ye, State Key Laboratory for Novel Software Technology, Nanjing University; Key Laboratory of Water Big Data Technology of Ministry of Water Resources, Hohai University; School of Computer and Information, Hohai University
- StRAID: Stripe-threaded Architecture for Parity-based RAIDs with Ultra-fast SSDs Shucheng Wang, Qiang Cao, and Ziyi Lu, Wuhan National Laboratory for Optoelectronics, HUST; Hong Jiang, Department of Computer Science and Engineering, UT Arlington; Jie Yao, School of Computer Science and Technology, HUST; Yuanyuan Dong, Alibaba Group
- Vinter: Automatic Non-Volatile Memory Crash Consistency Testing for Full Systems Samuel Kalbfleisch, Lukas Werling, and Frank Bellosa, Karlsruhe Institute of Technology
NICs
- AlNiCo: SmartNIC-accelerated Contention-aware Request Scheduling for Transaction Processing Junru Li, Youyou Lu, Qing Wang, Jiazhen Lin, Zhe Yang, and Jiwu Shu, Tsinghua University
- FpgaNIC: An FPGA-based Versatile 100Gb SmartNIC for GPUs Zeke Wang, Hongjing Huang, Jie Zhang, and Fei Wu, Zhejiang University; Gustavo Alonso, ETH Zurich
- Faster Software Packet Processing on FPGA NICs with eBPF Program Warping Marco Bonola, CNIT/Axbryd; Giacomo Belocchi, Angelo Tulumello, and Marco Spaziani Brunella, Axbryd/University of Rome Tor Vergata; Giuseppe Siracusano, NEC Laboratories Europe; Giuseppe Bianchi, University of Rome Tor Vergata/CNIT; Roberto Bifulco, NEC Laboratories Europe
Deployed Systems 2
NVMe SSD Failures in the Field: the Fail-Stop and the Fail-Slow Ruiming Lu, Shanghai Jiao Tong University; Erci Xu, PDL; Yiming Zhang, Xiamen University; Zhaosheng Zhu, Mengtian Wang, and Zongpeng Zhu, Alibaba Inc.; Guangtao Xue, Shanghai Jiao Tong University; Minglu Li, Shanghai Jiao Tong University & Zhejiang Normal University; Jiesheng Wu, Alibaba Inc.
CacheSack: Admission Optimization for Google Datacenter Flash Caches Tzu-Wei Yang, Seth Pollen, Mustafa Uysal, Arif Merchant, and Homer Wolfmeister, Google
Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam ,Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, Akshat Vig, Amazon Web Services
OSDI 22
SIGMOD 22
FAST 22
value_sizes=(16 64 256 1024 4096 8192 16384) nums=(1342177280 536870912 157903209 41297762 10444959 5232660 2618882)
./db_bench -compression_type=none -key_size=16 -threads=1 -benchmarks=fillseq -cache_size=10737418240 -duration=0 -db=/mnt/ssd/64B_data -num=536870912 -value_size=64
./db_bench -compression_type=none -key_size=16 -threads=1 -benchmarks=readrandom -cache_size=10737418240 -db=/mnt/ssd -duration=60 -use_existing_db -num=2618882 -value_size=16384