
数据分布和负载均衡分析
本文通过分析Ceph Crush算法的问题,总结数据分布和负载均衡的相关算法和策略,思考对Crush算法的优化途径。
- Ceph-Crush 问题
- 问题1:不可控迁移,迁移量是理论下限的h倍(h为分层结构的层数)
- 问题2:不够均衡,CRUSH 输入的样本容量不够、副本机制的缺陷
- 问题3:选择存储节点时,仅以节点存储容量为唯一选择条件,并没有考虑其他因素(到网络和节点 的负载状况等等)
- 相关优化 In Ceph
- 算法优化
- MapX(fast’20)增加时间戳,开销极大,在对象存储中不可行
- 降低迁移任务的优先级,治标不治本,只是推后了迁移,并未解决迁移带来的问题
- 使用 cluster device flags 选择性标记 failed OSDs,减少数据传输
- 选择节点考虑负载、异构环境、网络等等情况
- 事后补救
- balancer(Luminous版本之后,并不完善)调整映射关系,目前只支持 compat weight-set 和upmap
- 测试显示,打开balancer模块,大约1分钟会触发一次,几分钟基本就调整完了,调整的结果非常好
- 并不持久化,扩容或者重启OSD会重新计算分布,之前的映射失效
- 手动调整(reweight、批量调整、upmap等)
- 算法优化
- 数据分布&&负载均衡
- 评判指标
- 负载均衡:节点磁盘容量,数据访问(read/write)负载等均匀分布
- 可扩展性:能否友好的应对增/删节点,以及日益增长的规模
- 可靠性:数据分片需要多个副本
- 可用性:副本放置需要考虑故障域隔离,保证更好的可用性
- 一致性、性能指标、分布式CAP等等
- 静态处理
- load balancer
- range-based:region,shard,tablet,Random Slicing(ACM TOS’14)
- hash-based:consistent-hashing,Crush,hash虚拟桶
- consistent-hashing(STOC’97)
- hash环(SOSP’07)
- Jump Consistent Hash,Google
- Maglev Consistent Hash(Google,NSDI’16)
- Crush:RUSHP, RUSHR, RUSHT
- 动态处理:round-robin,least connections,the power of two random choices
- Load Balancing with cache
- small cache ,big effect, SoCC’11
- switchKV,NSDI’16
- NetCache,SOSP’17
- DistCache,FAST’19 Best Paper
- range-based: region, shard, tablet, Random Slicing(ACM TOS’14)
- hash-based: consistent-hashing, Crush, hash虚拟桶
- consistent-hashing(STOC’97)
- hash环(SOSP’07)
- Jump Consistent Hash, Google
- Maglev Consistent Hash(Google, NSDI’16)
- Crush: RUSHP, RUSHR, RUSHT
- 动态处理: round-robin, least connections, the power of two random choices
- Load Balancing with cache
- small cache, big effect, SoCC’11
- switchKV, NSDI’16
- NetCache, SOSP’17
- DistCache, FAST’19 Best Paper
- 评判指标
- 思考
- 算法优化:应该尽量保留Crush算法,添加一些辅助手段
- 类似于MapX:能否有别的方式来区分新旧对象?
- 策略优化:选择节点有必要考量其他因素?用什么策略选择?
- 两次hash、with cache能否借鉴?
- 工具优化:balancer模块探究
- balancer持久化(怎么和crush算法相结合?)
- balancer是否足够优秀,自动调整策略是否有优化空间?
- 大规模对象下表现如何,打开该模块是否影响性能?
- 主pg分布调整
- 算法优化:应该尽量保留Crush算法,添加一些辅助手段
算法优化
1. Ceph-Crush 本身
- Ceph-Crush 问题
- 问题1:不可控迁移,迁移量是理论下限的h倍(h为分层结构的层数)
- 问题2:不够均衡,CRUSH输入的样本容量不够、副本机制的缺陷
- 问题3:选择存储节点时,仅以节点存储容量为唯一选择条件,并没有考虑其他因素(到网络和节点 的负载状况等等)
相关优化
MapX 增加了一个虚拟选择层,通过时间戳来记录集群中各节点加入的时间,将批量加入的节 点看作一个新的虚拟层; 虚拟层将集群分为了不同的子集,子集在数据均衡和创建时可以选择不同的虚拟层; 由于新层不会影响旧层的权重,旧对象在旧层中的放置不会改变,减少了数据迁移,实现了对集群扩容过程的性能控制。
- 时间戳开销极大,在对象存储中不可行。🤔思考:能否有别的方式来区分新旧对象?
[2]降低迁移任务的优先级(以避免扩展后的突发性迁移)
- 治标不治本,只是推后了迁移,并未解决迁移带来的问题
[3]使用cluster device flags 选择性标记failed OSDs,减少数据传输
- 相关实验 https://blog.csdn.net/xiongwenwu/article/details/53120415
- 改了几个操作命令都能发文章😓
Ceph 存储系统在副本模式下选择存储节点时,仅以节点存储容量为唯一选择条件,并没有考虑到网络和节点的负载状况,这影响了系统在网络性能差和节点高负载的情况下的读写性能.
[4] 设计了基于软件定义网络技术的 Ceph 存储系统模型和存储节点选择策略,首先利用软件定义网络技术实时获取网络和负载状况,以简化网络配置和减小测量开销,然后通过建立并求解出综合考虑了多种因素的多属性决策数学模型来确定存储节点的位置
[5] 使用基于遗传算法改进的数据放置算法来优化原始 CRUSH 算法在选择存储节点时只考虑节点存储容量的不足,通过对分布式计算框架 MapReduce 的研究,利用混合整数线性规划算法来求解异构环境下 Ceph 的最优数据放置策略。当对象存储设备、 集群数量或者任务数量较多时,因为利用混合整数线性规划算法的时间复杂度太高,所以该文还通过遗传算法优化了 CRUSH 算法

[6] 不仅考虑权重,还要考虑负载占比, 将Factor从原来的weight改成partition/weight,代表了每个子节点的重量负担,partition=pgs
2. 其他数据分布算法
- 中心化目录显式映射,去中心化包括很多hash式或者范围分片方式
- 典型的hash式包括:一致性hash、Crush、Rendezvous hashing、哈希取模法,虚拟桶算法等等
- 🤔思考:换算法是否合理?
- 哈希取模法
- 哈希表的扩容, 当哈希表中插入元素越来越多的时候,哈希表就需要扩容。 这时候不得不重新申请一块新的连续内存,把所有的元素拷贝过去并进行重新映射(rehash)
- 哈希表的扩容和重新映射都是全量进行的,需要全量迁移数据,现实应用中需要的是增量扩容的方式
- 虚拟桶算法
1997年 MITDavid Karger在解决分布式Cache中提出的
基本定义:我们希望构造一种函数 f(k,n)→m 把字符串映射到 n 个槽上:它的输入是随机到来的字符串 k 和 槽的个数 n。输出是映射到的槽的标号 m , m<n。这个函数需要有这样的性质:
- 映射均匀:对随机到来的输入 k, 函数返回任一个 m 的概率都应该是 1/n
- 一致性:
- 相同的 k, n 输入, 一定会有相同的输出。
- 当槽的数目增减时, 映射结果和之前不一致的字符串的数量要尽量少。更严格的是: 当添加一个槽时, 只需要对 K/n 个字符串进行进行重新映射。
- 这个算法的关键特征在于, 不要导致全局重新映射, 而是要做增量的重新映射。
hash 环
- Amazon Dynamo(SOSP07) [8],虚节点、分片、数据复制、冲突故障处理…
- 割环(等分存储拓扑)、随机分片、动态调整…
- [7] 提出在Ceph中对象到hash使用一致性hash
- 🤔思考:一致性Hash本身问题就很多
- Google提出,空间复杂度更低,根本无内存占用,而且算法非常简洁,C++的实现不到10行代码
- 从概率学角度来满足一致性和均匀性
- 一致性:在这个重新映射的过程中,key要么保留在原来的桶中,要么移动到新增加的桶中
- 均匀性:key会等概率地映射到每个桶中,不会出现某个桶里有大量key,某个桶里key很少甚至没有key的情况
int ch(int key, int n) { random.seed(key); int b = 0; int f = 0; while (f < n) { b = f; r = random.next(); f = floor((b+1)/r) } return b; }致命缺点:不能减少中间节点(减少中间节点将导致后面一系列数据迁移,越前面的节点影响越大);没有权重和副本机制
- o->pg的映射意义好像不大
- 得另外加映射;分多层,一层映射不会或者说很难发生节点删除,一层节点不多,就算有删除迁移并不多。
🤔思考:Jump一致性Hash可以实现扩容和容灾(副本),权重吗?
请求中继: 新加入的节点对于读取不到的数据,可以把请求中继(relay)到老节点,并把这个数据迁移过来。
假如此次扩容时,节点数目由 n 变为 n+1, 老节点的标号则可以由 ch(k,n)计算得出, 即节点数量为 n 的时候的 k 的槽位标号。

移除尾部节点:可以把尾部节点的数据备份到老节点

移除一个非尾部节点,会造成大面积的映射右偏

容灾策略:
- 尾部节点备份一份数据到老节点
- 非尾部节点备份一份数据到右侧邻居节点

带权重:和hash环类似,添加虚拟节点

Maglev一致性哈希
Google提出,介绍了自2008年起服役的网络负载均衡器Maglev, 文中包括Maglev负载均衡器中所使用的一致性哈希算法,即Maglev一致性哈希 (Maglev Consistent Hashing)
Maglev主要思路就是建表
- 为每个槽位生成一个偏好序列, 尽量均匀随机
- 建表:每个槽位轮流用自己的偏好序列填充查找表
- 查表:哈希后取余数的方法做映射

左边的每一个纵列代表槽位的偏好序列, 右边是要填充的查找表,下整个的填充过程:
- B0的偏好序列的第一个数字是 3, 所以填充 B0 到 entry[3]
- 轮到 B1 填充了, B1 的偏好序列第一个是 0, 所以填充 B1 到 entry[0]
- 轮到 B2 填充了,由于 entry[3]被占用, 所以向下看 B2 偏好序列的下一个数字,是 4, 因此填充 B2 到 entry[4]
- 接下来, 又轮到 B0 填充了, 该看它的偏好序列的第2个数字了,是 0,但是 entry[0] 被占用了; 所以要继续看偏好序列的第3个数字,是 4, 同理, 这个也不能用,直到测试到 1 可以用, 则填充 B0 到 entry[1]
- 如上面的填发, 直到把整张查找表填充满
偏好序列
取两个无关的哈希函数 h1 和 h2, 假设一个槽位的名字是 b, 先用这两个哈希函数算出一个 offset 和 skip
offset=h1(b)%M
skip=h2(b)%(M−1)+1然后, 对每个 j,计算出 permutation中的所有数字, 即为槽位 b 生成了一个偏好序列:
permutation[j]=(offset+j×skip)%M
这是一种类似二次哈希的方法, 使用了两个独立无关的哈希函数来减少映射结果的碰撞次数,提高随机性
生成偏好序列的方法可以有很多种(比如直接采用一个随机序列等),生成的偏好序列要随机、要均匀
查找表的长度 MM 必须是一个质数。 和哈希表的槽位数量最好是质数是一个道理, 这样可以减少哈希值的聚集和碰撞,让分布更均匀
Maglev 的增删
映射均匀和一致性
- 由于偏好序列中的数字分布是均匀的,查找表是所有偏好序列轮流填充的, 容易知道,查找表也是分布均匀的, 这样,映射也是均匀的
- 所以,槽位增删导致查找表的某个位置填充的槽位标号发生变化,我们称这是一种「干扰(disruption)」。 槽位增删必然导致填充干扰,我们的目的是追求这个干扰的最小化
删除情况

- 删除槽位 B1 前后,红色圆圈内标出了受干扰的填表结果, 可以看到,查找表7个位置中有3个被重新填充。 其中两个位置(第 0,2行)是因为 B1 的移除导致被其他槽位接管, 还有一个第 6 行的 B0→B2 的联动干扰 (因为 B0 接管了 B1 的 entry[2] 导致原本自己的 entry[6] 被 B2 抢占)
增加B3

- 7个位置中有3个被重新填充。 其中两个位置(第 1,5行)是因为 B3 的加入抢占了其他槽位的填充机会, 另一个第 6 行的 B0→B2 则是一种联动干扰
再删除B0

- 这一次的填表干扰更严重了, 7个里面出现了4个被重新填充。 其中两个(第 3,4 行)是因为 B0 的移除导致位置被其他槽位接管, 还有两个(第 1,6 行,B3→B1 和 B2→B3)都是属于联动干扰
Maglev一致性哈希虽然没有导致全量重新映射, 但却没有做到最小化重新映射
论文指出了联动干扰确实存在, Maglev哈希法并没有实现最小化的干扰。 不过,在 Google 的实际测试中总结出来, 当查找表的长度越大时,Maglev哈希的一致性会越好,但是查表速度会下降。
扩容:请求中继;容灾:未提,暂不支持。
Maglev优势:查表O(1)
- Maglev哈希算法的应用场景是负载均衡,确切的说是弱状态化的后端的负载均衡。 如果后端节点的数据是类似数据库性质的强状态化数据,那么就会有容灾设计的问题
- 如果后端节点是无状态的、或者是弱状态的(如缓存), Maglev哈希算法的一致性的特点还是有好处的:比如降低故障情况下的缓存击穿的比例、连接重新建立的比例等等
🤔思考:Maglev Hash可以实现副本机制吗?
B0 B1 B2 映射 备份 3 0 3 0 2. B1 4. B0 0 2 4 1 10. B0 11. B1 4 4 5 2 5. B1 14. B2 1 6 6 3 1. B0 3. B2 5 1 0 4 6. B2 7. B0 2 3 1 5 9. B2 13. B0 6 5 2 6 8. B1 12. B2 B0 B1 B2 B3 映射 备份 3 0 3 5 0 2. B1 5. B0 0 2 4 3 1 12. B3 13. B0 4 4 5 6 2 6. B1 14. B2 1 6 6 0 3 1. B0 3. B2 5 1 0 1 4 7. B2 9. B0 2 3 1 2 5 4. B3 11. B2 6 5 2 4 6 8. B3 10. B1 B1 B2 B3 映射 备份 0 3 5 0 1. B1 11. B2 2 4 3 1 12. B3 13. B1 4 5 6 2 4. B1 14. B2 6 6 0 3 2. B2 6. B3 1 0 1 4 5. B2 7. B1 3 1 2 5 3. B3 8. B2 5 2 4 6 9. B3 10. B1 三种一致性hash对比
均匀性 最小化重新映射 时间复杂度 加权映射 热扩容 & 容灾 哈希环 ✔ ✔ O(log(n)) ✔ ✔ 跳跃一致性哈希 ✔ ✔ O(log(n)) ✔ ✔ Maglev哈希 ✔ ✘ O(1) ✔ ✘
3. 负载均衡研究
- 静态处理。根据节点的处理能力(节点的规格,涉及CPU,内存,存储多个维度),load balancer可以对负载预先划分边界,能者多劳。对于hash-based的方法,例如consistent-hashing,引入virtual nodes实现环状hash空间的均匀散列(其实可以在virtual nodes中对节点的规格做分拆,为处理能力强的节点适当分配更多的virtual nodes)。
- 动态处理:就是负载均衡的策略选择了,从round-robin,least connections到the power of two random choices(one more random,big effect!这也很有意思,可以看文后的参考资料)。
Load Balancing with cache
small cache ,big effect, SoCC’11

n个存储节点,无论query是怎样的分布,缓存最热的O(nlogn)个对象即可均衡负载
- M个ball依次随机地投入N个bin中,以很高的概率得到最大负载:

优化:选择多个bin,挑一个负载最小的投
The Power of Two Random Choices: A Survey of Techniques and Results,2001
60页的论文证明两次随机选择的威力
应用:NGINX、Haproxy、Cuckoo Hash、BloomFilter…


switchKV,NSDI 2016
NetCache,SOSP 2017
DistCache,FAST 2019 Best Paper!
- 小Cache解决热点的方案不能很好地scale out到多个集群,原因是一个集群一个Cache节点只能保证集群内的负载均衡,而集群间的负载均衡无法保证。如果在集群间再用一个Cache节点,是不足以支撑多个集群的吞吐的,因此集群间需要一层分布式的Cache
- 而分布式Cache的难点在于如果简单地replicate热点数据到多个Cache节点会有一致性问题,而简单地按照hash partition又会造成Cache Node之间的负载不均衡导致吞吐受限于一个节点。所以关键就是避免Cache Node间的不均衡以及保证Cache一致性的开销
- 两层分布式 cache + The Power of Two Random Choices
- 通过两层hash来分布Cache中的数据,保证其一层中有热点的节点会被散列到另外一层
- 然后通过power-of-two-choices来选择负载较低的节点访问
- 能够保证要维护的一致性开销最小化,同时论文理论证明了这个做法是不会导致任何一个Cache引热点数据过载

事后补救
- balancer(Luminous版本之后,并不完善)调整映射关系,目前只支持compat weight-set和upmap,都不持久化
- BoostKit
- 每个OSD对应的PG分布负载均衡,ceph balancer mode使Ceph PG自动均衡优化,主要影响写入的负载均衡
- 主PG的分布负载优化,手动调整尽可能地将主PG均匀分布到各个OSD上
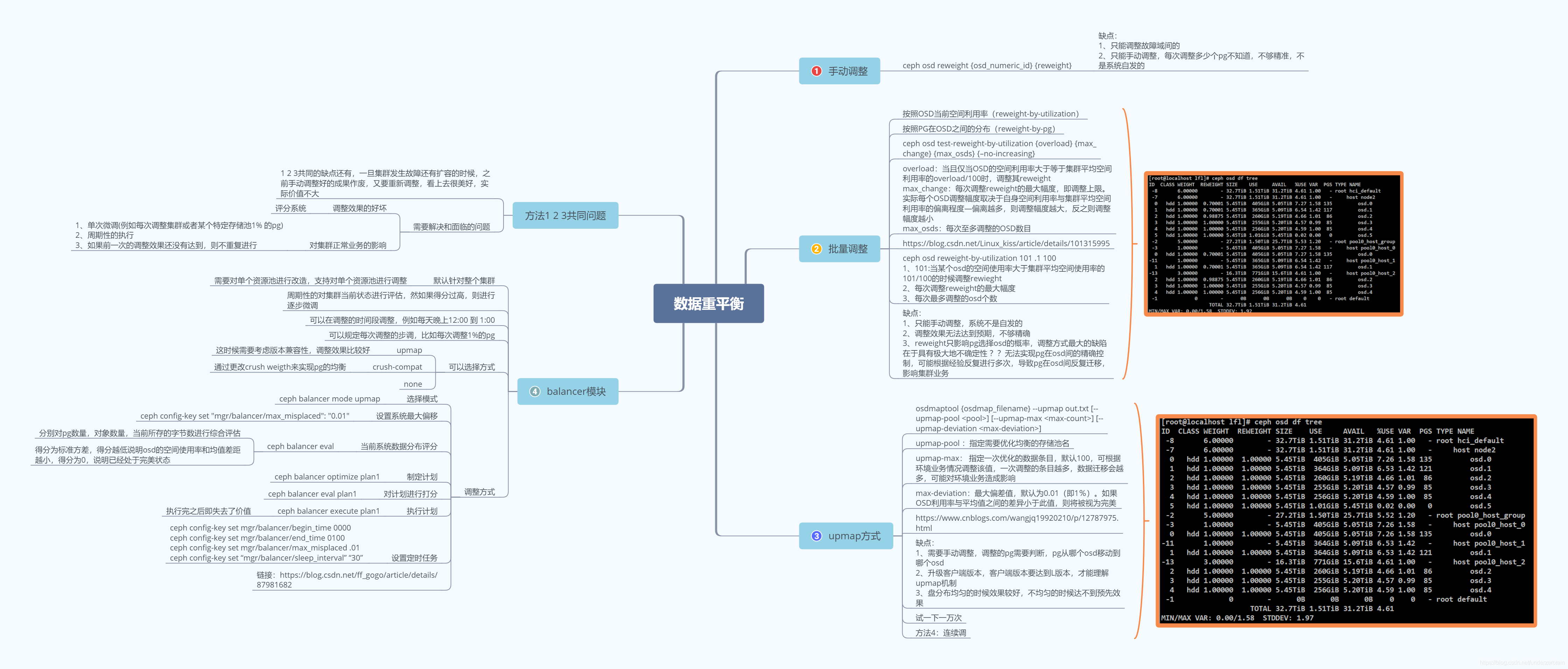
- 数据重平衡操作总结
参考文献
[1] MapX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems
[2] https://docs.ceph.com/docs/mimic/rados/configuration/osd-config-ref
[3] Research on data migration optimization of ceph
[4] A New Node Selection Method for the Ceph Storage System based on Software-defined Network and Fuzzy Multi-attribute Decision-making
[5] Optimizing Data Placement of MapReduce on Ceph-Based Framework under Load-Balancing Constraint
[6] https://www.infoq.cn/article/yHkBk59FX8UUXxm0VNHW
[7] https://patentimages.storage.googleapis.com/26/2e/86/31451bc1d4259c/CN105450734A.pdf
[8] Dynamo: Amazon’s Highly Available Key-value Store
[9] A Fast, Minimal Memory, Consistent Hash Algorithm
[10] Maglev: A Fast and Reliable Software Network Load Balancer
[11] https://writings.sh/post/consistent-hashing-algorithms-part-4-maglev-consistent-hash
[12] https://blog.csdn.net/underzerotem/article/details/106299770?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242